
论文题目: Learning Contextualized Document Representations for Healthcare Answer Retrieval
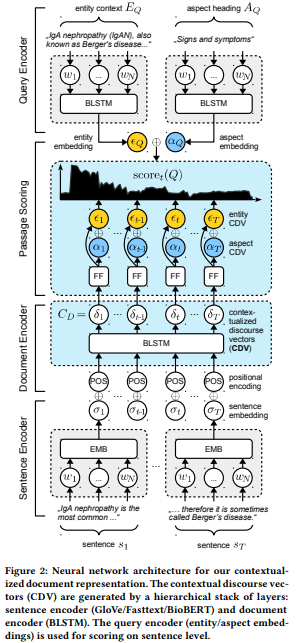
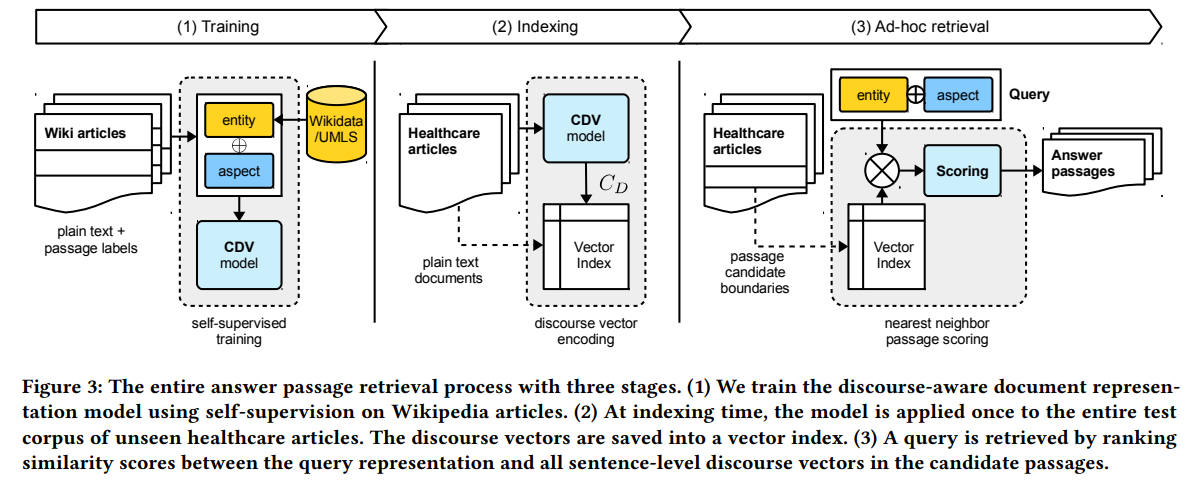
摘要: 我们提出了上下文文档向量(CDV),这是一种分布式的文档表示,用于从较长的医疗文档中有效地检索答案。我们的方法基于来自自由文本和医疗分类法的实体和方面的结构化查询元组。我们的模型利用具有分层LSTM层和多任务训练的双重编码器体系结构来编码临床实体的位置和方面。我们使用连续表示来解决具有短延迟的查询,在句子级使用近似近邻搜索。我们使用CDV模型从网上9个英语公共卫生资源中检索连贯的回答段落,面向患者和医疗专业人员。由于没有适用于所有应用程序场景的端到端训练数据,我们使用来自Wikipedia的自监督数据来训练我们的模型。我们证明,我们的广义模型显著地优于几个最先进的卫生医疗基准,并且能够适应不需要额外微调的异构领域。
成为VIP会员查看完整内容


相关内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
37+阅读 · 2020年3月14日
专知会员服务
28+阅读 · 2020年2月12日
专知会员服务
23+阅读 · 2019年11月26日
专知会员服务
49+阅读 · 2019年11月15日
Arxiv
12+阅读 · 2019年9月26日
Arxiv
15+阅读 · 2018年1月5日



相关VIP内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
37+阅读 · 2020年3月14日
专知会员服务
28+阅读 · 2020年2月12日
专知会员服务
23+阅读 · 2019年11月26日
专知会员服务
49+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
12+阅读 · 2019年9月26日
Arxiv
15+阅读 · 2018年1月5日