
Most existing video summarisation methods are based on either supervised or unsupervised learning. In this paper, we propose a reinforcement learning-based weakly supervised method that exploits easy-to-obtain, video-level category labels and encourages summaries to contain category-related information and maintain category recognisability. Specifically, We formulate video summarisation as a sequential decision-making process and train a summarisation network with deep Q-learning (DQSN). A companion classification network is also trained to provide rewards for training the DQSN. With the classification network, we develop a global recognisability reward based on the classification result. Critically, a novel dense ranking-based reward is also proposed in order to cope with the temporally delayed and sparse reward problems for long sequence reinforcement learning. Extensive experiments on two benchmark datasets show that the proposed approach achieves state-of-the-art performance.
翻译:大部分现有的视频汇总方法都是基于监督或不受监督的学习。在本文中,我们建议采用一种基于强化的基于学习的薄弱监管方法,利用容易获取的视频级别类别标签,并鼓励摘要包含与类别有关的信息并保持分类可识别性。具体地说,我们将视频汇总作为顺序决策程序,并用深层次的Q学习来培训一个汇总网络。还培训了一个配套分类网络,为培训DQSN提供奖励。我们与分类网络一起,根据分类结果开发了一种全球可识别性奖。关键的一点是,还提出了一种新的密集排序奖,以应对长期强化学习的滞后和稀少的奖励问题。关于两个基准数据集的广泛实验表明,拟议方法取得了最新业绩。






































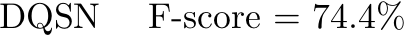









相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


