论文题目: Rule-Guided Compositional Representation Learning on Knowledge Graphs
摘要:
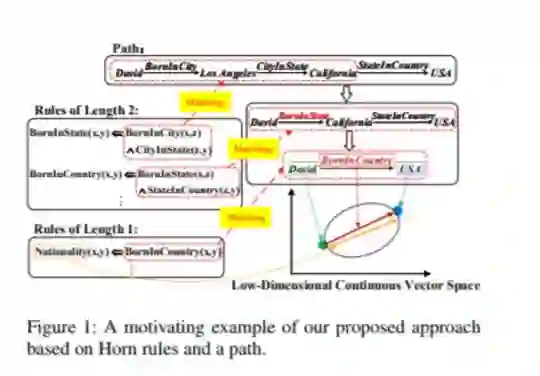
知识图的表示学习是将知识图中的实体和关系嵌入到低维连续向量空间中。早期的KG嵌入方法只关注编码在三元组中的结构化信息,由于KG的结构稀疏性,其性能受到限制。最近的一些尝试考虑路径信息来扩展KGs的结构,但是在获取路径表示的过程中缺乏可解释性。本文提出了一种新的基于规则和路径的联合嵌入(RPJE)方案,该方案充分利用了逻辑规则的可解释性和准确性、KG嵌入的泛化性以及路径的补充语义结构。具体来说,首先从KG中挖掘出不同长度(规则体中的关系数)的Horn子句形式的逻辑规则,并对其进行编码,用于表示学习。然后,利用长度2的规则来精确地组合路径,而使用长度1的规则来明确地创建关系之间的语义关联和约束关系嵌入。优化时还考虑了规则的置信度,保证了规则在表示学习中的可用性。大量的实验结果表明,RPJE在KG完成任务上的表现优于其他最先进的基线,这也证明了利用逻辑规则和路径来提高表示学习的准确性和可解释性的优越性。
论文作者:
张永飞:男,博士,副教授,博士生导师。2005年毕业于北京航空航天大学自动化学院,获学士学位,免推直博;2011年毕业于北京航空航天大学模式识别与智能系统专业,获博士学位。2007年至2009年在美国密苏里大学哥伦比亚分校电气与工程学院访问。2011年加入北航计算机学院数字媒体北京市重点实验室。科研工作:目前主要研究方向包括(1)(视觉)大数据智能分析处理;(2)高性能实时图像/视频编解码与可靠传输。主持国家自然科学基金项目面上项目、国家重点研发计划项目子课题、国家自然科学基金重点项目子课题、863项目子课题、国家重点实验室自主课题、企业合作预研项目等多项科研任务;作为技术骨干参与国家973计划、杰出青年基金、国家自然科学基金项目等多项国家级课题的科研工作等。
刘偲,计算机学院副教授、博导。 2012年博士毕业于中科院自动化所,2009-2014年于新加坡国立大学(NUS)任研究助理、博后。2016年在微软亚洲研究院(MSRA)任铸星计划研究员。2014-2018在中国科学院信工所任副研究员。其研究方向是跨模态多媒体智能分析,包括自然语言处理(NLP)和计算机视觉(CV)。共发表了CCF A类论文 40余篇,其研究成果发表于TPAMI、IJCV、TIP、CVPR、ICCV和ACM MM等。 Google Scholar引用4000+次。2017年入选中国科协青年人才托举工程,2017年获CCF-腾讯犀牛鸟专利奖。任2017中国计算机大会(CNCC)主论坛特邀讲者,2017 CCF青年精英大会“青年技术秀”讲者。获2017 ACM 中国新星提名奖,2017国际计算机学会人工智能专委会中国区(ACM SIGAI China) 新星奖,2018吴文俊人工智能优秀青年奖。 另外,她获CCF A类会议ACM MM 2012最佳技术演示奖,ACM MM 2013最佳论文奖。指导学生获得ChinaMM2018 最佳学生论文奖。带领学生多次获得国际、国内竞赛冠军: 2016年获CCF大数据与计算智能大赛(BDCI)综合特等奖,2017年获CVPR Look Into Person Challenge Human Parsing Track冠军,2019年获得ICCV Youtube-Video Object Segmentation 竞赛冠军。 主办了ECCV 2018和ICCV 2019‘Person in Context’workshop。担任中国图像图形学学会理事、副秘书长。任ICCV 2019、CVPR 2020 Area chair,AAAI 2019、IJCAI2019、IJCAI 2020 SPC。