中山大学发布最新《图对抗机器学习》2020综述论文,带你全面了解40+种攻防对抗学习方法

-
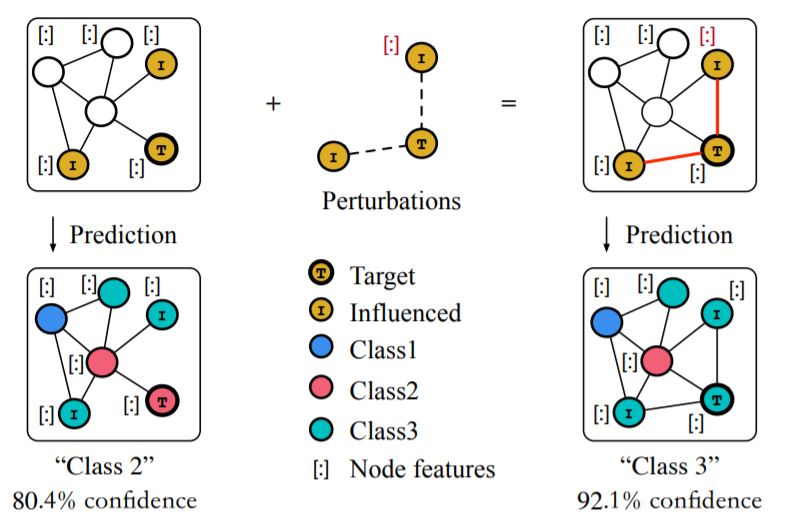
我们深入研究了这一领域的相关工作,并对当前防御和攻击任务中不统一的概念给出了统一的问题形式化和明确的定义。
-
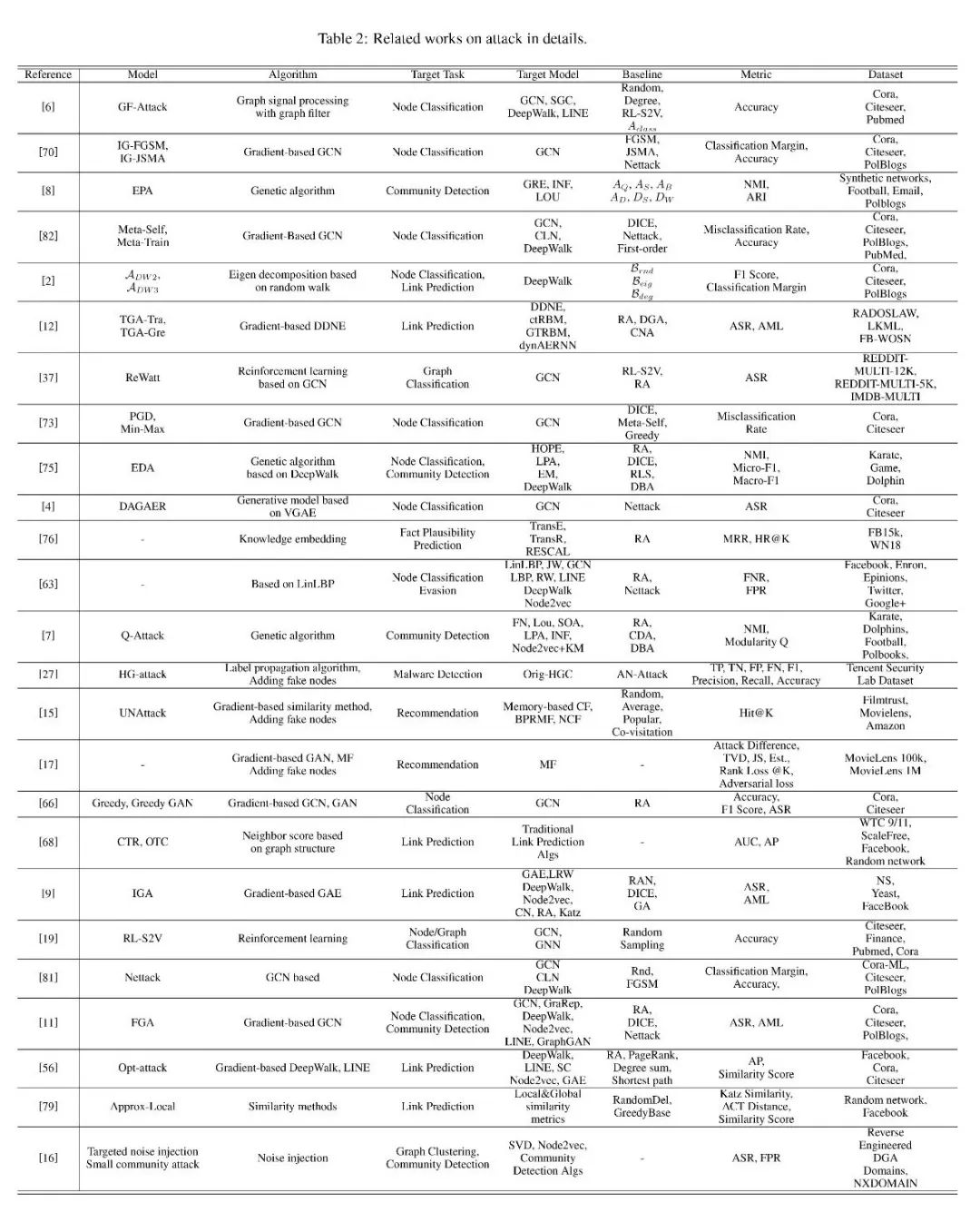
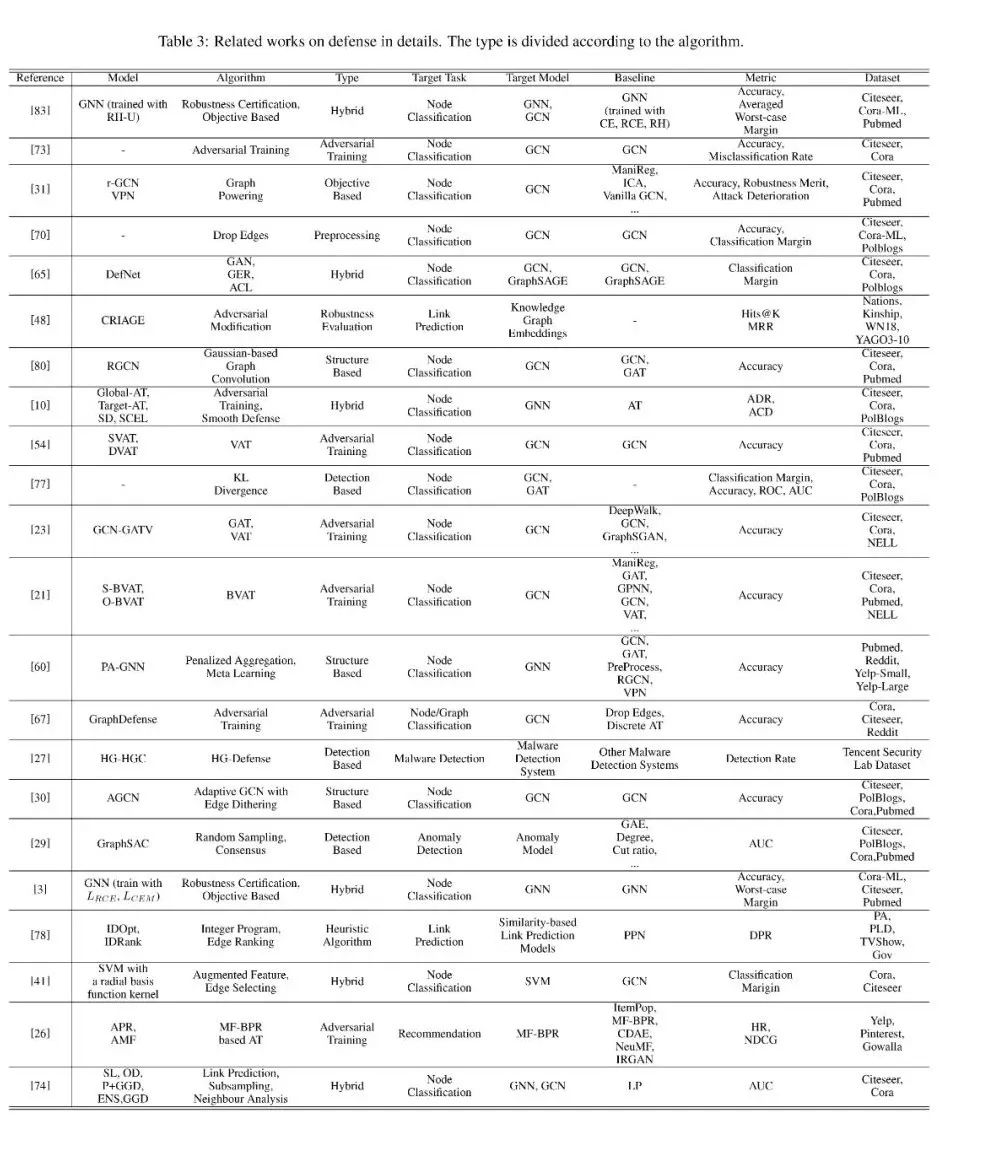
我们总结了现有工作的核心贡献,并根据防御和攻击任务中合理的标准,从不同的角度对其进行了系统的分类。
-
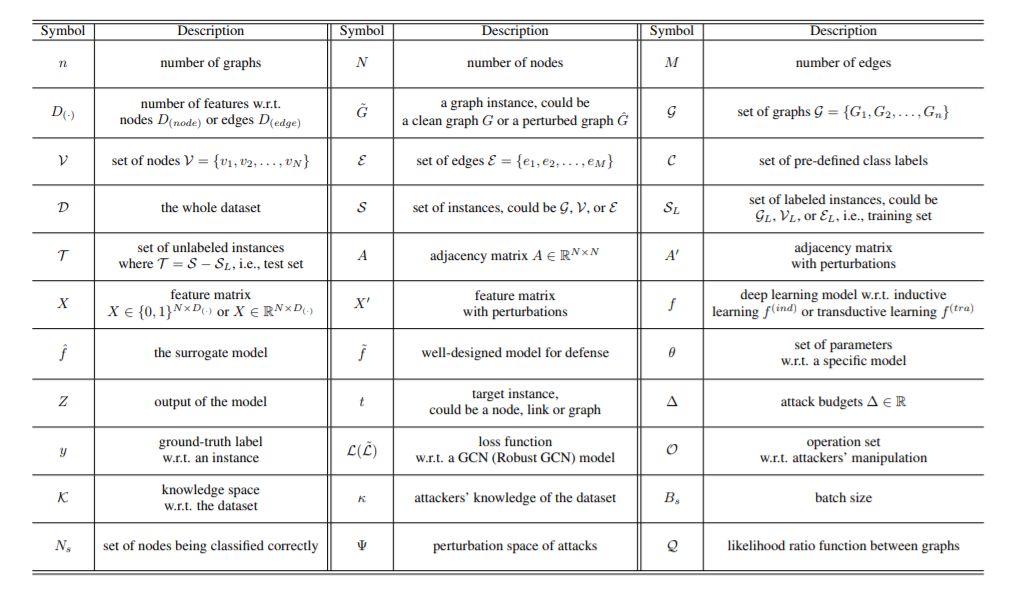
我们强调了相关指标的重要性,并对其进行了全面的调研和总结。
-
针对这一新兴的研究领域,我们指出了现有研究的局限性,并提出了一些有待解决的问题



便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ GAL ” 就可以获取《 中山大学发布最新《图对抗机器学习》2020综述论文,带你全面了解40+种攻防对抗学习方法 》论文专知下载链接



登录查看更多
相关内容

Arxiv
9+阅读 · 2018年5月30日
Arxiv
9+阅读 · 2018年1月27日

相关VIP内容
相关资讯
相关论文
Arxiv
9+阅读 · 2018年5月30日
Arxiv
9+阅读 · 2018年1月27日