
开源大模型赶上ChatGPT了吗?

在2022年底发布之时,ChatGPT在整个人工智能领域的研究和商业方面都带来了翻天覆地的变化。通过对大型语言模型(LLM)进行指令调优、经过监督的微调以及根据人类反馈的强化学习,它展示了一个模型可以回答人类问题并在广泛的任务范围内遵循指示。继这一成功之后,对LLM的兴趣大大增强,学术界和工业界频繁涌现出新的LLM,包括许多专注于LLM的初创公司。虽然闭源LLM(例如,OpenAI的GPT、Anthropic的Claude)通常优于它们的开源对手,但后者的进展迅速,有声称在某些任务上达到或甚至超越ChatGPT的情况。这不仅对研究,也对商业有着关键影响。在这项工作中,为庆祝ChatGPT发布一周年,我们提供了这一成功的详尽概述,综述了所有开源LLM声称与ChatGPT不相上下或更好的任务。
https://www.zhuanzhi.ai/paper/fd1994eb5720038ded207caa6a3783f0
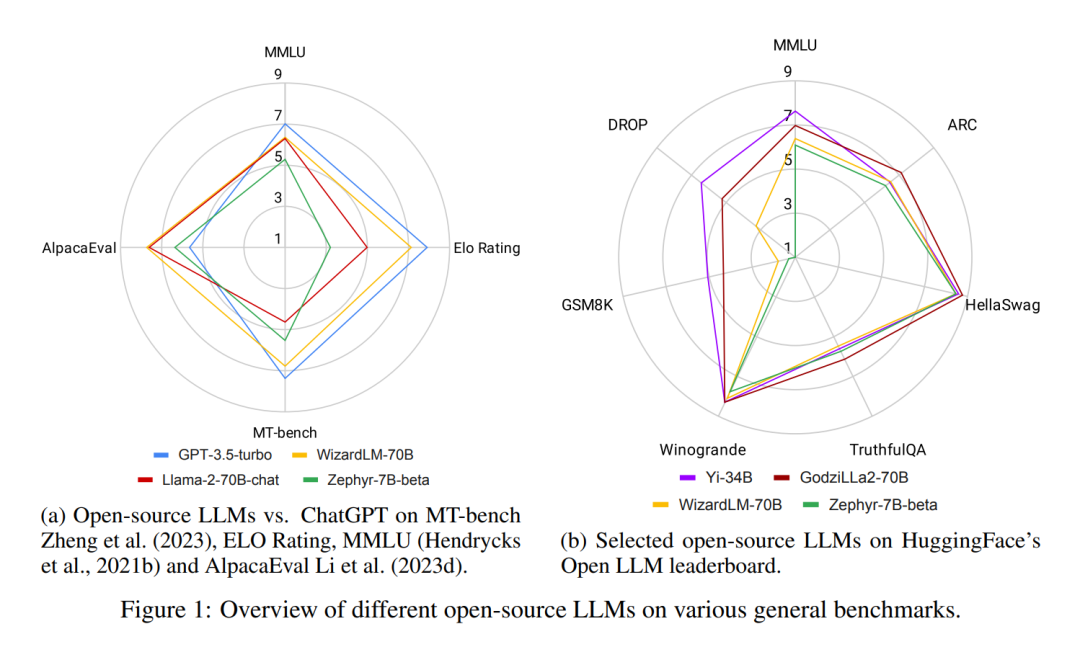
在一年前,OpenAI发布的ChatGPT引起了人工智能界和更广泛世界的轰动。首次,一个基于应用的AI聊天机器人能够普遍提供有用、安全、详细的回答,遵循指令,甚至承认并修正其先前的错误。值得注意的是,它可以执行这些传统上由经过预训练然后定制微调的语言模型(如概括或问答(QA))完成的自然语言任务,看似惊人地好。作为其类的首个,ChatGPT吸引了大众的注意 — 它在发布仅两个月内就达到了1亿用户,比如TikTok或YouTube等其他流行应用快得多。它还吸引了巨额商业投资,因其潜在的降低劳动力成本、自动化工作流程,甚至为客户带来新体验的能力(Cheng et al., 2023)。然而,由于ChatGPT没有开源,且其访问由私人公司控制,大部分技术细节仍然未知。尽管有声称ChatGPT遵循了InstructGPT(也称为GPT-3.5)中引入的程序(Ouyang et al., 2022b),但其确切的架构、预训练数据和微调数据是未知的。这种封闭源性质产生了几个关键问题。首先,不了解内部细节,如预训练和微调程序,就难以正确估计其对社会的潜在风险,尤其是知道LLM可能会生成有毒、不道德和不真实的内容。其次,据报道,ChatGPT的性能随时间变化,妨碍了可重现结果(Chen et al., 2023c)。第三,ChatGPT经历了多次中断,仅在2023年11月就有两次重大中断,期间ChatGPT网站和其API的访问完全被阻止。最后,采用ChatGPT的企业可能会担心调用API的高昂成本、服务中断、数据所有权和隐私问题,以及不可预测的事件,如最近有关首席执行官Sam Altman被解职、员工叛乱以及他最终回归的董事会戏剧(REUTERS来源)。开源LLM是一个有希望的方向,因为它们可以潜在地补救或绕过上述大多数问题。因此,研究界一直在推动将高性能LLM保持在开源状态。然而,截至今天,人们普遍认为,像Llama-2(Touvron et al., 2023b)或Falcon(Almazrouei et al., 2023)这样的开源LLM落后于它们的封闭源对手,比如OpenAI的GPT3.5(ChatGPT)和GPT-4(OpenAI,2023b)、Anthropic的Claude2或Google的Bard3,其中GPT-4通常被认为是截至2023年底的所有LLM中的佼佼者。然而,这个差距越来越小,开源LLM迅速赶上。事实上,正如图1所示,在某些任务上,最好的开源LLM已经比GPT-3.5-turbo表现得更好。然而,对于开源LLM来说,并不是一场直截了当的上坡战。LLM的格局不断演变:封闭源LLM定期在更新的数据上重新训练,开源LLM几乎每周都会发布,有大量的评估数据集和基准用于比较LLM,这使得挑选出最佳LLM尤其具有挑战性。在这项综述中,我们旨在整合最近的开源LLM论文,并提供一个概述,即在各个领域与ChatGPT相当或超越的开源LLM。我们的贡献有三个方面: • 整合对开源LLM的各种评估,提供对开源LLM与ChatGPT的公正和全面的看法(图1,第3.1节)。 • 系统地审查在各种任务中超越或赶上ChatGPT的开源LLM,并进行分析(图2,第3节,第4.2节)。 • 提出关于开源LLM发展趋势的见解(第4.1节)、训练开源LLM的良好做法(第4.3节)和开源LLM可能存在的问题(第4.4节)。 这项综述旨在为研究界和商业领域提供一个关于开源LLM当前格局和未来潜力的关键资源。对于研究人员,它提供了当前开源LLM进展和演变趋势的详细综合,强调未来调查的有希望的方向。对于商业领域,这项综述提供了宝贵的见解和指导,帮助决策者评估采用开源LLM的适用性和好处。在接下来的文章中,我们首先介绍背景前提(第2节),然后对在各个领域击败ChatGPT的开源LLM进行深入审查(第3节),接着讨论开源LLM的见解和问题(第4节),最后我们总结这项综述(第5节)。

开源LLM与ChatGPT对比
通用能力
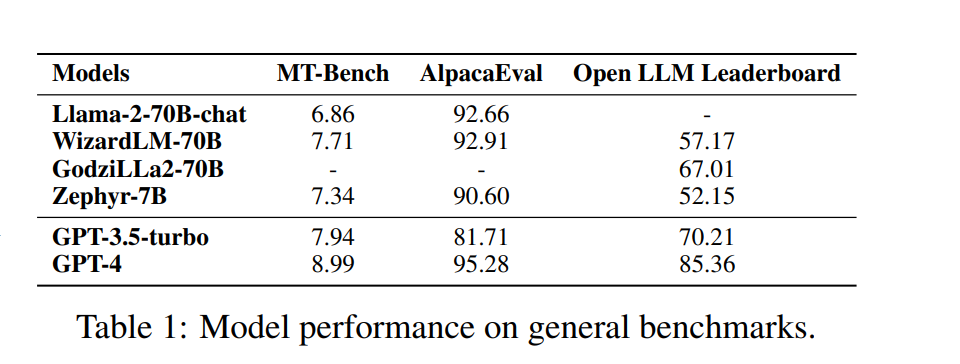
Llama-2-70B(Touvron et al., 2023b)是一款杰出的开源LLM,已在庞大的两万亿令牌数据集上进行预训练。它在各种通用基准测试中展示了卓越的结果。当进一步使用指令数据进行微调时,Llama-2-chat-70B变体在一般对话任务中表现出增强的能力。特别是,在AlpacaEval中,Llama-2-chat-70B取得了92.66%的胜率,超过了GPT-3.5-turbo的10.95%。然而,GPT-4仍然是所有LLM中的顶尖表现者,其胜率为95.28%。另一个较小的模型Zephyr-7B(Tunstall et al., 2023)使用了蒸馏直接偏好优化(Rafailov et al., 2023a),在AlpacaEval中与70B LLM取得了相当的结果,胜率为90.6%。它甚至在MT-Bench上超过了Llama-2-chat-70B,得分为7.34对6.86。此外,WizardLM-70B(Xu et al., 2023a)经过使用大量具有不同复杂度的指令数据的微调。它作为最高得分的开源LLM在MT-Bench上脱颖而出,得分为7.71。然而,这仍然略低于GPT-3.5-turbo(7.94)和GPT-4(8.99)的得分。尽管Zephyr-7B在MT-Bench上表现出色,但在开放LLM排行榜上得分仅为52.15%。另一方面,GodziLLa2-70B(Philippines, 2023),一款结合了各种专有LoRAs(来自Maya Philippines 6)和Guanaco Llama 2 1K数据集(mlabonne, 2023)与Llama-2-70B的实验模型,在开放LLM排行榜上取得了更具竞争力的67.01%的得分。这一表现与GPT-3.5-turbo(70.21%)相当。然而,两者都明显落后于GPT-4,后者以85.36%的高分领先。UltraLlama(Ding et al., 2023)利用了具有增强多样性和质量的微调数据。它在其提出的基准测试中与GPT-3.5-turbo的表现相匹配,而在世界和专业知识领域则超越了后者。 大模型发展趋势
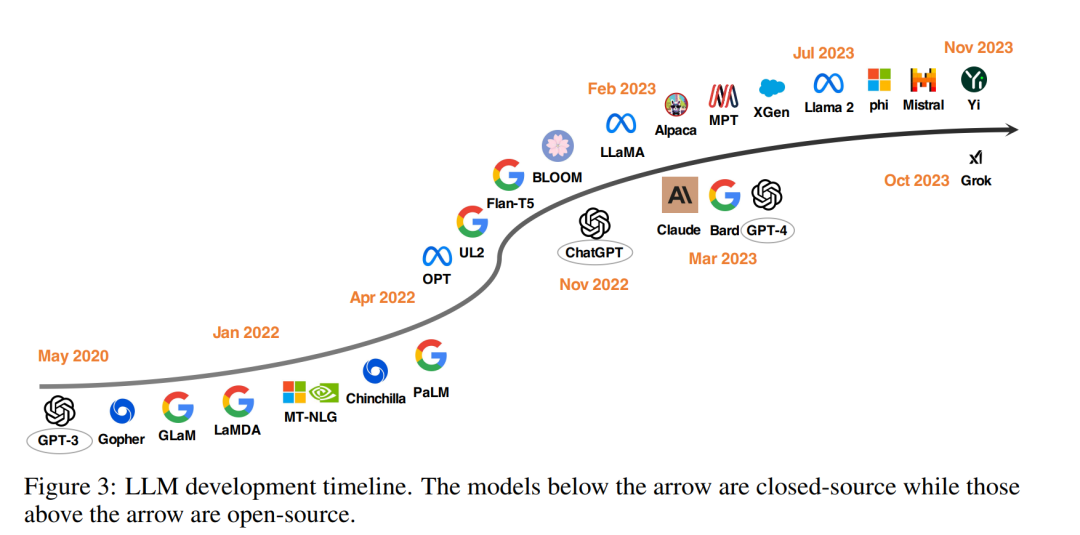
自从Brown et al.(2020年)展示了一个固定的GPT-3模型可以在各种任务上实现令人印象深刻的零次和少次尝试性能以来,为推进LLM的发展已经做出了许多努力。其中一个研究方向专注于扩大模型参数,包括Gopher(Rae et al., 2021年)、GLaM(Du et al., 2022年)、LaMDA(Thoppilan et al., 2022年)、MT-NLG(Smith et al., 2022年)和PaLM(Chowdhery et al., 2022年),达到了540B参数。尽管这些模型展示了显著的能力,但它们封闭源的性质限制了其广泛应用,因此引起了对开发开源LLM的日益浓厚的兴趣(Zhang et al., 2022年;Workshop et al., 2022年)。
另一个研究方向不是扩大模型规模,而是探索了为预训练较小模型提供更好的策略或目标,如Chinchilla(Hoffmann et al., 2022b年)和UL2(Tay et al., 2022年)。在预训练之外,还有相当多的关注集中在研究语言模型的指令调优上,例如FLAN(Wei et al., 2021b年)、T0(Sanh et al., 2021年)和Flan-T5(Chung et al., 2022年)。
OpenAI的ChatGPT一年前的出现极大地改变了自然语言处理(NLP)社区的研究重点(Qin et al., 2023a年)。为了赶上OpenAI,Google和Anthropic分别推出了Bard和Claude。虽然它们在许多任务上显示出与ChatGPT相当的性能,但与最新的OpenAI模型GPT-4(OpenAI,2023b年)之间仍存在性能差距。由于这些模型的成功主要归因于来自人类反馈的强化学习(RLHF)(Schulman et al., 2017b年;Ouyang et al., 2022a年),研究人员探索了各种改进RLHF的方法(Yuan et al., 2023年;Rafailov et al., 2023b年;Lee et al., 2023b年)。
为了促进开源LLM的研究,Meta发布了Llama系列模型(Touvron et al., 2023a,b年)。从那时起,基于Llama的开源模型开始爆炸性地出现。一个代表性的研究方向是使用指令数据对Llama进行微调,包括Alpaca(Taori et al., 2023年)、Vicuna(Chiang et al., 2023年)、Lima(Zhou et al., 2023b年)和WizardLM(Xu et al., 2023a年)。正在进行的研究还探索了提高基于Llama的开源LLM的代理(Xu et al., 2023d年;Zeng et al., 2023年;Patil et al., 2023年;Qin et al., 2023b年)、逻辑推理(Roziere et al., 2023年;Luo et al., 2023a,c年)和长文本建模(Tworkowski et al., 2023年;Xiong et al., 2023年;Xu et al., 2023b年)能力。此外,除了基于Llama开发LLM之外,还有许多努力投入到从零开始训练强大的LLM,例如MPT(团队,2023年)、Falcon(Almazrouei et al., 2023年)、XGen(Nijkamp et al., 2023年)、Phi(Gunasekar et al., 2023年;Li et al., 2023e年)、Baichuan(Yang et al., 2023a年)、Mistral(Jiang et al., 2023a年)、Grok(xAI,2023年)和Yi(01ai,2023年)。我们相信,开发更强大、更高效的开源LLM,以民主化封闭源LLM的能力,应该是一个非常有前景的未来方向。
最佳开源 LLM配方
训练LLM涉及复杂且资源密集型的实践,包括数据收集和预处理、模型设计和训练过程。虽然定期发布开源LLM的趋势日益增长,但领先模型的详细实践通常不幸保密。以下我们列出了社区广泛认可的一些最佳实践。
数据预训练涉及使用万亿级别的数据Token,这些数据Token通常来自公开可获取的资源。从伦理角度来说,排除包含私人个体信息的任何数据至关重要(Touvron et al., 2023b)。与预训练数据不同,微调数据在数量上较小,但在质量上更为优越。使用顶级质量数据微调的LLM表现出改善的性能,特别是在专业领域(Philippines, 2023; Zeng et al., 2023; Xu et al., 2023d,a)。
模型架构虽然大多数LLM采用仅解码器的变换器架构,但模型中采用了不同技术来优化效率。Llama-2实现了Ghost关注机制,用于改进多轮对话控制(Touvron et al., 2023b)。Mistral(Jiang et al., 2023b)采用滑动窗口关注机制来处理扩展的上下文长度。
训练使用指令调优数据进行监督微调(SFT)的过程至关重要。为了获得高质量的成果,数万条SFT注释就足够,这一点由用于Llama-2的27,540条注释证实(Touvron et al., 2023b)。这些数据的多样性和质量至关重要(Xu et al., 2023a)。在RLHF阶段,近似策略优化(PPO)(Schulman et al., 2017a)通常是首选算法,以更好地使模型的行为与人类偏好和指令遵从性保持一致,这在提高LLM安全性方面起着关键作用。PPO的一种替代方法是直接偏好优化(DPO)(Rafailov et al., 2023a)。例如,Zephyr-7B(Tunstall et al., 2023)采用了蒸馏DPO,在各种通用基准测试上显示出与70B-LLM相当的结果,甚至在AlpacaEval上超过了GPT-3.5-turbo。
总结
在这项综述中,我们提供了对在各种任务领域超越或赶上ChatGPT的高性能开源LLM的系统性调研,标志着ChatGPT发布一周年(第3节)。此外,我们提供了关于开源LLM的见解、分析和潜在问题(第4节)。我们相信,这项综述揭示了开源LLM的有希望的发展方向,并将激发进一步在开源LLM领域的研究和发展,有助于缩小与付费对手的差距。
