
题目: M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
摘要: 将图表示学习与多视图数据(边信息)相结合进行推荐是当前行业的发展趋势。现有的方法大多可归纳为多视图表示融合;它们首先构建一个图,然后将多视图数据集成到图中每个节点的一个紧凑表示中。然而,这些方法在工程和算法方面都引起了关注:1)工业中的多视图数据丰富且信息量大,可能超过单个矢量的能力;2)由于多视图数据往往来自不同的分布,可能会引入归纳偏差。在本文中,我们使用多视图表示对齐方法来解决这个问题。特别地,我们提出了一个多任务多视图图表示学习框架(M2GRL),用于从多视图图中学习节点表示。M2GRL为每个单视图数据构造一个图,从多个图中学习多个独立的表达式,并执行与模型跨视图关系的对齐。M2GRL选择了多任务学习范式来联合学习视图内表示和跨视图关系。M2GRL运用同方差不确定性自适应调整训练过程中任务的减重。我们在淘宝上部署了M2GRL,并对它进行了570亿例的培训。根据离线度量和在线A/B测试,M2GRL显著优于其他最先进的算法。在淘宝上对多样性推荐的进一步探索表明,利用M2GRL产生的多重表示是有效的,我们认为这是一个很有前途的方向,为各种不同重点的行业推荐任务。
成为VIP会员查看完整内容
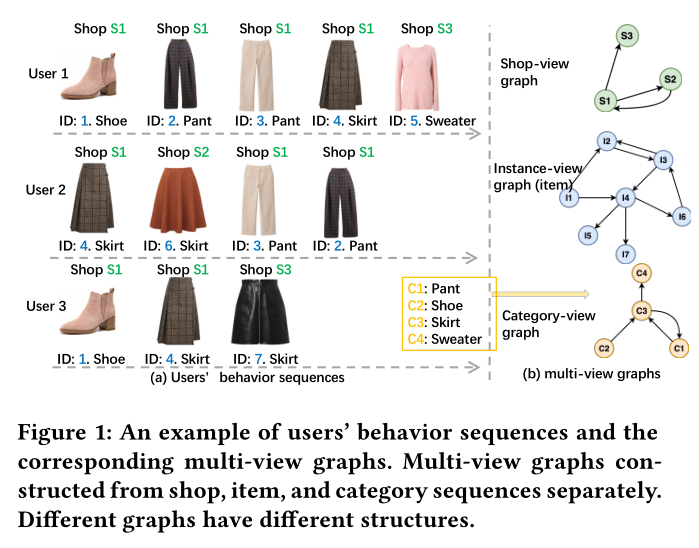
相关内容

推荐系统,是指根据用户的习惯、偏好或兴趣,从不断到来的大规模信息中识别满足用户兴趣的信息的过程。推荐推荐任务中的信息往往称为物品(Item)。根据具体应用背景的不同,这些物品可以是新闻、电影、音乐、广告、商品等各种对象。推荐系统利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
115+阅读 · 2020年1月3日
专知会员服务
147+阅读 · 2019年12月16日
专知会员服务
74+阅读 · 2019年11月20日
Arxiv
23+阅读 · 2020年3月7日

相关VIP内容
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
115+阅读 · 2020年1月3日
专知会员服务
147+阅读 · 2019年12月16日
专知会员服务
74+阅读 · 2019年11月20日
相关资讯