Andrej Karpathy最新专访:AGI、Optimus、软件2.0时代丨万字精华观点

10月底,在著名AI播客主持人Lex Fridman长达三个小时的访谈节目中,特斯拉前AI总监Andrej Karpathy谈及了他对于Transformer、神经网络、大规模语言模型、AGI的理解,以及对特斯拉、Optimus的看法。此外,在天马行空的交流中,他还讲到了对宇宙人生、外星生物的畅想,甚至包括他个人专注、近乎疯狂的日常工作模式。在特斯拉的五年间,他一手促成了Autopilot的开发。智源社区选取全文精华内容进行了整理,供参考。
编译:智源社区
原视频链接:https://www.youtube.com/watch?v=cdiD-9MMpb0

Andrej Karpathy
前特斯拉人工智能和自动驾驶部门(Autopilot)负责人,主攻计算机视觉和深度学习领域,曾为OpenAI创始成员和研究科学家,师从斯坦福大学教授李飞飞,与其共同设计并讲授广为人知的斯坦福深度学习课程CS231n,2022年7月宣布从特斯拉离职。
精彩提要
● 构建AGI需要具身交互
● 当机器人想成为人类
● 让特斯拉工程团队实现软件2.0
● 基于视觉的自动驾驶
● 特斯拉的数据引擎
● 实现自动驾驶的时间表
● 离开特斯拉
● Optimus量产
● 生物演进
● 外星文明
● ImageNet已被击败
● 神经网络的本质
● Transformer强大且稳定
● 用语言模型理解世界
● Karpathy的一天
● 给初学者的建议
“
构建AGI需要具身交互

特斯拉Optimus

“
当机器人想成为人类
“
让特斯拉工程团队实现软件2.0
L:软件2.0这一概念在过去的几个月中逐渐演化开来,能否对此做出一些解释?
A:几年前,我在一篇博文中提出了「软件2.0」,这是因为我观察到在软件开发领域中,有很多代码并不是通过C++等语言编写,而是通过神经网络生成代码。对于编程来说,这是一项重大的转变,神经网络正在「接管」软件领域。人们不再手工编写代码,编程范式转变为收集训练数据并设定训练目标。我们需要将数据集、目标设置、架构设置通过编译过程转化为表示神经网络权重、前馈过程的二进制语言。这一想法已经在诸多工业界的任务中得到了应用。
类比地看,在软件1.0时代,我们在集成开发环境(IDE)中编写代码、调试代码、运行代码、在 GitHub上维护代码;而在软件2.0时代,这种范式则转变为了Hugging Face这类模式。
L:你曾经是特斯拉的AI主管,你如何成规模地让工程团队实现软件2.0?
A:在软件2.0概念下,我们对计算机进行编程、影响算法的方式并不是人工地编写命令,而是对神经网络使用的数据集、网络架构、损失函数进行修改,如果训练出的神经网络可以给出正确的答案,我们就可以部署这个系统。
L:为了完成各项任务,也许可以构建多头神经网络。你如何将问题分解为一系列小任务?
A:以AutoPilot为例,许多在软件1.0时代由C++编写的程序可以逐渐由小型的神经网络替代,整个大的系统将这些小网络组合起来。我们也许拥有不止一个摄像头,我们需要将根据各个摄像头的图像得到的预测结果融合起来。我们可以将这个融合的过程交给神经网络完成,将各个软件接口交由软件2.0实现。神经网络可以比人类更加胜任编写软件的工作。
L:那么这种预测是在4D空间进行的(随时间变化的3D空间)。在软件2.0下,如何在这样的世界中进行数据标注?采用自监督的方式或是人类手工标注?
A:监督学习是目前工业界普遍可用的技术。因此,我们需要准备输入数据集、输出标签,它们需要满足以下三个特性:(1)大规模(2)准确(3)多样。在此基础之上,数据清洗的工作非常繁重。我们收集训练数据的机制很多,例如:人工标注、仿真模拟、离线追踪器(一种自动的三维重建过程)。
在特斯拉,我们从零开始构建了一个上千人的数据标注团队。人类非常擅长于某些特定的标注工作(例如,2D图像标注),同时也有一些标注工作是人类不擅长的(例如,标注3维空间中随时间变化的物体)。因此,我们分别将一些标注工作交给人类和离线追踪器完成。

“
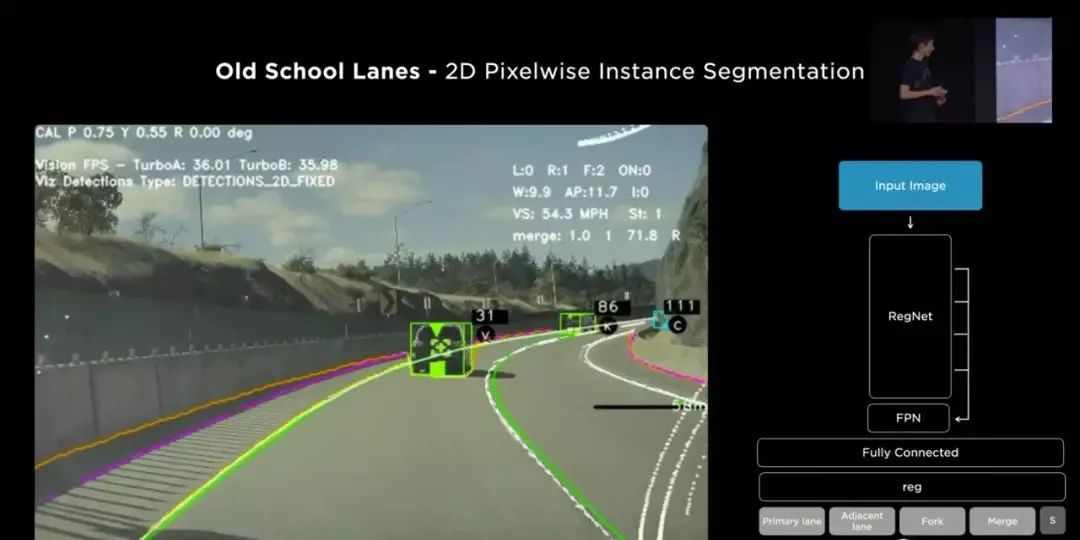
基于视觉的自动驾驶
L:你将驾驶任务形式化定义为了使用8个摄像头的视觉任务,将摄像头用于自动驾驶测试有何利弊?
A:人类也会使用视觉,像素传感器能以极低的成本提供大量的信息,这些信息构成了对世界状态的复杂、高带宽的约束。
L:但是除了视觉之外,人类还会使用常识、物理等约束来认识世界。除了视觉感知,人类在对世界进行预测时还会用到推理等方法。
A:是的,人类对世界的演进形成了强大的先验知识。不仅有根据数据得来的似然项,而是对数据的位置、运动方式等属性的先验项。
L:在自动驾驶任务中,可能发生的事件的复杂程度至关重要。其中存在哪些难点?
A:驾驶场景下,我们要实现心智理论,预测其它智能体会做什么。
L:从视觉的角度来说,自动驾驶任务中最困难的视觉问题是什么?
A:尽管视觉传感器很强大,但是我们仍然需要对信号进行精细的处理。最困难的问题是构建神经网络系统的整个工作流程。就数据引擎而言,它需要能够训练神经网络、迭代式地评估系统。而大规模地完成上述任务是十分困难的。此外,以较低的延迟在汽车芯片上部署系统也并非易事,此时算力、内存、带宽都有限。
“
特斯拉的数据引擎
“
实现自动驾驶的时间表
L:你认为解决自动驾驶问题的时间表是什么样的?
A:我认为自动驾驶时间表的困难之处显然在于,没有人真正实现过自动驾驶。这并不像,你认为建造这座桥梁的时间表是什么样的?好吧,我们以前造过无数的桥,而这座需要这么长时间。
没有人实现过自动驾驶,答案并不清楚。有些部分比其他部分容易得多,这真的很难预测。你尽力而为,基于趋势线等等,也基于直觉,但那就是为什么从根本上说,真的很难预测。
L:福特和其他公司曾经做出预测,我们将在2020年,2021年,或某个特定时间解决L4级自动驾驶问题。而现在,这个预言证明他们都错了。你如何形成一个强有力的表达,让你能够对于可解决性做出预测?你是很多人的领袖,你必须说,这实际上是可能的。如何建立这种直觉?
A:是的,专家级的直觉,仅仅直觉,一种信念。套用游戏的类比,这里有“战争迷雾”,但你肯定也能看到改进的前沿。可以通过历史衡量,已经取得的进展。
我认为,例如,至少以我在特斯拉大约五年的时间里所看到的,我加入公司时,它只能在高速公路上保持车道。我记得从帕洛阿尔托到旧金山,需要三到四次的人工干预。任何时候,道路有了任何几何上的变化,或者转弯太猛,它就无法运作。
在五年内,从那个状态发展到一个具有相当能力的系统,并看到在表象之下,实际发生了些什么,以及就数据,算力和其他一切而言,团队现在运营的规模。这些都是巨大的进步。
L:这就像,你在爬山,虽然有雾,但你也在不断取得很大的进展。
A:有雾,你正在取得进展,并且你看到接下来的方向是什么。
你在看着剩下的一些挑战,而它们并没有干扰你,它们没有改变你的哲学,而且你没有扭曲自己。你会说,实际上这些就是我们仍然需要做的事情。
L:是的,解决问题的根本要素似乎就在那里。从数据引擎,到车上的计算机,再到用于训练的算力,所有这些要素。
“
离开特斯拉
L:在特斯拉,这么多年来,你已经实现了... 你已经实现了很多惊人的突破性的想法和工程工作,所有这些。从数据引擎,到人员方面,所有这一切。你能说说,为什么选择离开特斯拉吗?
A:基本上,正如我所描述的,在这五年里,随着时间的推移,我逐渐转到管理岗位上。我大部分时间都是在开会,和发展组织,做出关于团队的高层次的战略决策,以及团队应该做些什么,等等。这有点像企业高管的角色。
我认为我做的还不错,但这并不是我本质上最享受做的事情。我记得,当初加入公司时,还没有计算机视觉团队,因为特斯拉刚刚脱离第三方供应商MobilEye的依赖,开始搭建自己的计算机视觉系统。我加入的时候,有两个人在训练深度神经网络。他们的训练工作是在脚边的电脑上完成的,一台工作站。
L:那是很基本的分类任务。
A:我把团队从萌芽状态,发展到了我认为是相当值得尊敬的一个深度学习团队,一个大规模的计算集群,一个非常好的数据标注团队。我对团队的情况非常满意,团队变得相当的自主,所以我可以退后一些。我很高兴,能再次从事更多的技术工作,重新专注AGI(通用人工智能)。
这个决定很难,因为我显然非常爱这家公司。我爱Elon,我爱特斯拉,离开是很困难的,我爱这个团队。我认为,特斯拉会开展一些不可思议的工作。它是一家大规模的机器人公司,拥有大量的内部人才。而我认为,人形机器人将会很了不起。自动驾驶的交通运输将会很了不起。所有这些都发生于特斯拉。作为它的一部分,并帮助它成长,我很享受这个过程。我很高兴有可能在未来某个时候,回到特斯拉开启第二篇章,从事Optimus或AGI的工作。
“
Optimus量产
L:你提到了人形机器人,你对于Optimus特斯拉机器人有什么看法?你认为10年,20年,30年,40年,50年后,工厂和家庭中会有机器人吗?
A:是的,我认为这是一个非常困难的项目,我认为需要一些时间。但还有谁在大规模地生产人形机器人?我认为,这是一个值得追求的非常好的外形尺寸。因为就像我提到的,这个世界是为人形尺寸设计的。这些东西将能够操作我们的机器,它们将能坐在椅子上,甚至有可能驾驶汽车。基本上,这个世界是为人类设计的。这就是你想投资的外形尺寸,并且随着时间的推移,使其发挥作用。
我认为,还有另外一派想法,那就是,选择一个问题,并设计机器人来解决它。但实际上,设计机器人,让整个数据引擎和它背后的一切技术都运作起来,实际上是一个非常困难的问题。
寻求通用的接口,是合理的。对于任何一个特定的任务,它们都不是完美的,但它们实际上具有通用性,只要给它英语指示,就能完成一些事情。我认为,在物理世界中寻求一个通用的接口,是非常合理的。
我认为,这是个非常困难的项目,将需要一些时间。但我认为,没有其他公司能够基于这一愿景执行。我认为它将令人惊奇,它基本上代表着劳动力。如果你认为交通运输是一个巨大的市场,那就试试劳动力市场吧,很疯狂。
L:嗯,但对我来说,这不仅仅是劳动力,同样令人兴奋的是,社会性的机器人。我们与这些机器人在不同层面上建立的关系。这就是为什么我看到Optimus时非常激动。人们因为我的激动而批评我。
A:是的,正如你所提到的,之所以能这么快,是因为从autopilot系统中,复制粘贴了大量的技术。特斯拉在生产人形机器人方面拥有大量的专业技术,让人难以置信。
有一次Elon说,我们要开发机器人。然后基本上第二天,所有这些CAD模型就开始出现了,而人们开始讨论供应链和生产制造。人们带着螺丝刀和所有工具出现了,并开始把机器人的身体组装在一起。我当时就说,哇,所有这些人,特斯拉都有。从根本上说,生产汽车和生产机器人并没有什么区别。的确如此,不仅仅是对于硬件而言。我们也不要忘记,硬件不仅仅是为了演示,大规模生产这些硬件,是一件完全不同的事情。而对于软件来说,也是如此。基本上,这款机器人目前认为自己是一辆汽车。
L:后续问题是,我们开车,操控物体,这个任务有多难,以至于进行规模化,它就可以产生影响?我认为,根据不同的场景,机器人技术的好处在于,除非用于制造业,它会有更大的容错空间。对于驾驶来说,安全性至关重要,时间精度也非常重要。
A:(规模化)需要很长的时间。制定产品发展路线图,获得收入是至关重要的。我不会给自己设定一个非零即一的损失函数:在它成功之前,是无法运作的。我们不希望处于这种境地。我们想让它几乎立即运作起来,然后,我们想要慢慢地部署它,并进行规模化。我们想要搭建我们的数据引擎,我们的改进循环,测量,评估,控制管理,以及所有的流程。我们想要随着时间的推移,逐步改进产品。而且我们在这一过程中获得收入,这一点至关重要。因为否则的话,我们将无法推进这些大型项目,那在经济上并不合理。
而且从工作团队的角度来看,他们也需要一路都获得多巴胺。他们不能接受,只是承诺这会成为有用的产品,一旦成功,它将在10年内改变世界。这不是我们想要的方式。我们想要的方式类似于今天的autopilot,它提供了不断增强的安全性和驾驶的便利性,就在今天。人们为它掏钱,人们喜欢它,人们购买它。然后,你也有更大的使命,正在努力实现。
L:团队的多巴胺,是快乐的来源。
A:没错,我们部署这个产品,人们喜欢它,人们驾驶试用它,人们为它掏钱,他们关心它,发布所有这些油管视频。你的奶奶驾驶试用它,她给你反馈。人们喜欢它,人们参与其中,你参与其中,这无比重要。
“
生物演进
L:作为忠实的生物学爱好者,你认为有什么重要的事是生物神经网络可以完成而计算机还不能做到的?
A:如今,将神经网络与人脑类比是值得商榷的。诚然,神经网络的起源受到了人脑的启发,但如今通过训练得到的人工智能的优化过程和人脑的优化过程有很大区别。人脑通过长时间的多智能体的自博弈(self-play)过程不断演化,大脑中的预测模型对于人类的存活和繁衍至关重要。而神经网络的优化实际上是对于大量数据的压缩。
L:人类由单个受精卵发育成胚胎,进而构建出器官和肢体,而DNA起到了编码的作用。这个发育的过程伴随着「学习和计算」。而纵观地球上的生命史,你认为最有趣的创造是什么?是物种起源,真核生物的诞生,哺乳动物、人类、智力的起源还是整个连续的过程?
A:从整个太阳系、地球的物质构成,生命的起源开始,生命的演进是非常传奇的故事。作为人工智能研究者,我认为人类的特别之处在于,人类在非常短的时间内形成了其他动物没有形成的科技社会。
L:有两种有趣的解释:(1)人类并不特别,所有的一切都写在了基因编码中,人类会越来越聪明,在多智能体的博弈中存活下来,这是一种自然的演化过程(2)有一些特殊的罕见事件发生了(例如,火的发明、太空漫游)。那么有哪些神奇的事情说明人类智能在宇宙中是特别的存在?
A:人类智能是否罕见尚不可知。但似乎在进化过程中会通过探索断断续续达到一些均衡点,从而实现一些稀疏的飞跃。例如,DNA、性别、真核生物系统、意识的出现。
“
外星文明
L:你认为存在多少有智慧的外星文明?他们的智慧与人类是否相似
A:我一直都在思考这个问题。我想知道在宇宙中,科技社会的存在是否普遍。而随着我研究的深入,我认为这样的科技社会应该相当多。
L:赞成,但是人类在地球上所取得的成就为什么很难实现?
A:我曾经认为声明的起源是非常神奇、罕见的事情。但是如果我们关注更加基础的化学上的细节,我们就会发现这一过程也可能在其它系统中发生。实际上,在地球形成不久后,生命的起源就开始了。
“
ImageNet已被击败
L:著名的ImageNet数据集近期在学术界有一些负面评价,你认为在机器学习研究中数据集的优势和劣势分别是什么?
A:互联网本身就是一个基准,允许深度学习社区证明深度神经网络确实有效,这当中有很大的价值。ImageNet很有用,但它在这方面变得有点像Minist数据集了,Minist数据集是28×28像素点的数据集,基本上快成为一个用来搞笑的数据集了。Imagenet已被击败,在1,000种分类预测方式中获得了90%的准确率。如果我没记错的话,目前前五名的错误率是1%左右。
L:鉴于您拥有构建庞大的现实世界数据集的经验,您是否希望看到基准数据集朝着研究社区使用的特定方向发展?
A:不幸的是,我认为学术界目前还没有下一个Imagenet。很明显,我认为我们已经击败了Emnist,我们基本上已经击败了imagenet。目前整个学术社区还没有下一个大的基准。

“
神经网络的本质
L:何为神经网络?为什么它能如此好地进行学习?
A:最初,神经网络是一种对人脑工作机制的数学化的抽象。归根到底,它是一种简单的数学表达式,可以写作矩阵乘法(点积)、非线性算子等操作构成的序列,包含若干个计算节点。我们可以宽泛地认为这种节点就好比人脑中的突触,它们可以被训练、修改。我们要合理设置这些计算节点,使其完成各种任务。人们不要过于纠结赋予神经网络与大脑相对应的意义。
L:正是如此。诗歌本质上也是字母和空格的组合,但是它能让人有奇妙的感触。同理,计算机和大脑中的这些计算节点组合起来也产生了令人惊讶的力量。
A:当足够大的由神经元组成的网络在足够复杂的问题上训练时(例如,预测大规模互联网数据中下一个词),往往会产生神奇的结果。
L:那么,在我们对话时,你的大脑会预测我要说的下一个词吗?或者它在做其它更有趣的事吗?
A:我们的大脑就好比一个与GPT类似的生成模型,对话的另一方会给出一些提示(prompt),而你也会根据自己的结构化知识(例如,记忆)加入一些额外的提示。
L:但是,如果要对你一生中所说过的话进行搜索,搜索的规模可能很大。同时,你也许通过同样的语序说过很多单词。
A:是的,我们重新组合一些常用的短语组成独特的句子。
L:许多人认为神经网络并不可信。你如何看待神经网络产生的令人意想不到的结果?
A:尽管从数学上说,神经网络非常简单,它涌现出的神奇行为看似并不可信,但我们有时也确实低估了神经网络。实际上,我们非常擅长优化神经网络,如果我们让它处理非常困难的问题,它会被迫在优化过程中学习到非常有趣的解。
L:直观地说,网络中大量的计算节点得到的表征从数据中捕获了一些智慧和知识,你认为这些知识竟是什么?
A:以目前大热的 GPT 模型为例,它可以根据互联网上的单词序列预测下一个单词。当我们利用足够大规模的数据训练好这些模型后,可以以任意方式为神经网络提供提示,要求网络解决一些问题。例如,你可以让网络求解某个数学问题,它们就会基于在互联网上见到的方法,给出与其几乎一致的答案,这些答案看上去是正确的。
“
Transformer强大且稳定
“
用语言模型理解世界
“
Karpathy的一天
L:作为世界上最有生产力、最聪明的人之一,你的富有成效的一天是怎么度过的?平时几点起床?
A:我不是一个早起的人,我是个夜猫子,八九点左右起床。我在读博期间,通常凌晨3点睡觉,我觉得凌晨时间是很宝贵的,因为大家都睡着了。东海岸,每天早上7、8点,已经开始有各种分散你精力的讯息了。但是凌晨3点,万籁俱寂,你不会被打扰,有大量的时间去做事情。你需要在一些项目上积聚动力。你需要加载你的工作内存,甚至洗澡、睡觉的时候,都沉迷于某个问题,醒来的时候马上进入状态开始工作。在解决某些问题的几天里几乎是与世隔绝的,我不想被打扰。
在特斯拉的时候,解决问题意味着面临各种障碍。比如,需要关联到我的集群中,调出VS代码编辑器,我可能会遭遇一些愚蠢的错误,各种各样阻碍生产力的小问题。你需要屏蔽各种形式分散注意力的内容,比如新的故事、邮件、其他有趣的项目,你只想真正集中注意力。
我也可以抽出一些时间来分散注意力,但不能太多。早上我喝咖啡,常规地看一些新闻、推特、hackernews、华尔街日报等等。
L:在高效的一天,你通常可以专注工作多长时间?
A:我大概可以小几个小时专注,然后中间休息吃点东西。我正在使用一个跟踪器,可以准确告诉我每天花在写代码上的时间, 即使在非常富有成效的一天,我仍然只花了大约6到8个小时。
这都是因为有太多的填充物。通勤、与人交谈,食物等等。这就是生活的成本,只是维系生命本身,和体内平衡,仅仅维持自己作为一个人本身要付出的成本都是非常高的。
L:在特斯拉工作是什么体验,是不是让员工们突破他们的工作极限?
A:特斯拉在这方面几乎是「臭名昭著」,是一种相对激烈的环境。相比于谷歌,我实习过3次的地方,在谷歌和DeepMind,整体基线是要高于前者的。偶尔会有间断的平衡,会有爆发点。表面看上去有些疯狂,有火药味和冲刺。
L:你的电脑设置是什么?开发环境呢?
A:我有一个大屏,27英寸的mac。旁边是我的笔记本。做深度学习,所有东西都得是linux系统。mac运行VS Code。但实际上你有一个远程文件夹,通过 ssh 你在其他地方的集群上操作实际文件。我认为当前最好的代码编辑器是VSCode。目前,我相信这是最好的IDE,它有大量的扩展。还有GitHub Copilot,这是非常有价值的。
(我最近和Python创始人Guido van Rossum交流,他也很喜欢用Copilot)
L:作为特斯拉的AI总监,包括在斯坦福的经历,全世界都视你为AI专家,你是否患有冒名顶替综合症(imposter syndrome)?
A:在特斯拉的5年间,我大量的时间都花在会议室里。一开始加入特斯拉的时候,我在写代码,后来写的代码越来越少,我开始读代码,后来读的代码也越来越少。所以这只是一个自然渐进的过程。结果到后来,你意识到你应该当一个专家了。但事实上,真相来源于那些实际在写代码的人。你不像之前那么熟悉代码了。确实在这方面有一些不安全感。

“
给初学者的建议
L:从CS231n到今天,您是机器学习/人工智能领域最杰出的讲师之一。对于有兴趣从事机器学习的初学者,您有什么建议?(博士就读于斯坦福期间,他设计并担任斯坦福首个深度学习课程《CS231n:卷积神经网络与视觉识别》的主要讲师。)
A:初学者通常专注于要做什么,我认为重点应该是你做了多少。我是「一万小时」的忠实信徒。只有投入一万小时的工作,才能成为特定领域的专家。所以基本上我会更多地关注你是否花费了10,000小时。
L:对于有志于开发和发表对人工智能世界产生重大影响的想法的研究人员(本科生或研究生),你有什么建议?
A:AI正在不断演化,他们肯定要比我读博期间更具战略性。好比物理研究中,以前是在工作站上做实验,现在你必须在像大型强子对撞机(LHC)或欧洲核子研究中心(CERN)一样的地方工作,人工智能也在朝着这个方向发展。有些事情光在工作站上是实现不了的。

学术头条
新版微信更改了公众号推荐规则,不再以时间排序,而是以每位用户的阅读习惯为准进行算法推荐。在此情况下,学术头条和“学术菌”们的见面有如鹊桥相会一样难得(泪目)
那么,如果在不得不屈服于大数据的当下,你还想保留自己的阅读热忱,和学术头条建立长期的暧昧交流关系, 将学术头条纳入【星标】,茫茫人海中也定能相遇~




