ICLR2020|迄今为止最大规模,Google 推出针对少样本学习的 Meta 数据集

新智元报道
新智元报道
来源:ICLR
编辑:科雨、白峰
【新智元导读】深度学习的成功往往依赖于大量手动标注的训练数据,这种局限性,激发了对少样本学习的研究,Google 在 ICLR2020 发布的 Meta-Dataset 则针对此问题,进行了新的探索和尝试。
标注数据受限,Google发布少样本学习数据集


在标准图像分类任务中,我们使用一组属于特定类别的一组图像进行模型的训练,然后使用相同类别的图像进行测试,然而,针对测试过程中遇到的全新类别问题,我们却无法很好的应对和处理少样本情况下的图像分类问题。
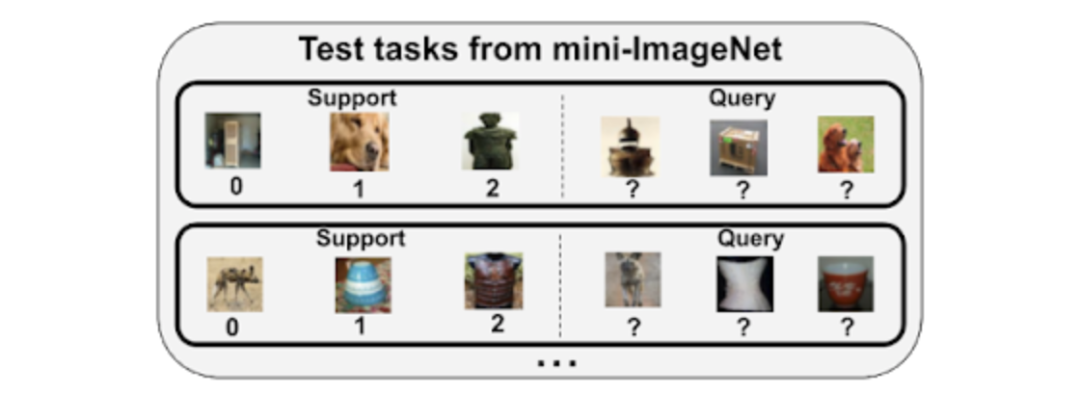
用于研究少样本分类的流行数据集是 mini-ImageNet,它是用 ImageNet 数据集的类别进行下采样后获得的。这个数据集包括 100 个类别,并被划分为训练集,验证集和测试集。

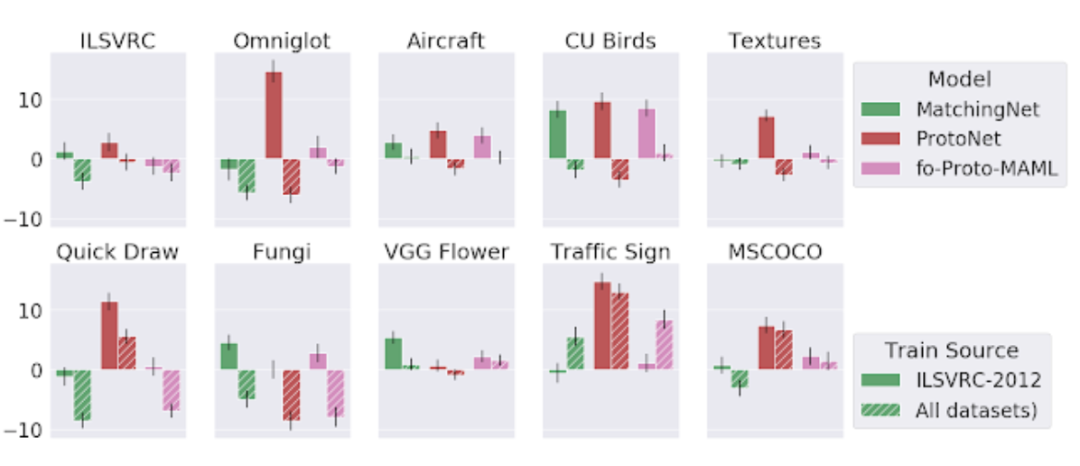
(1)现有方法难以利用异构训练数据
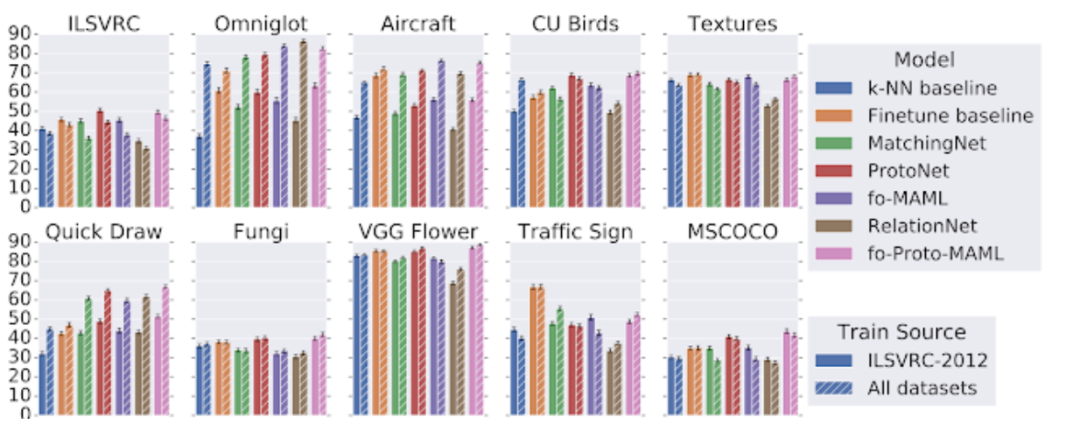
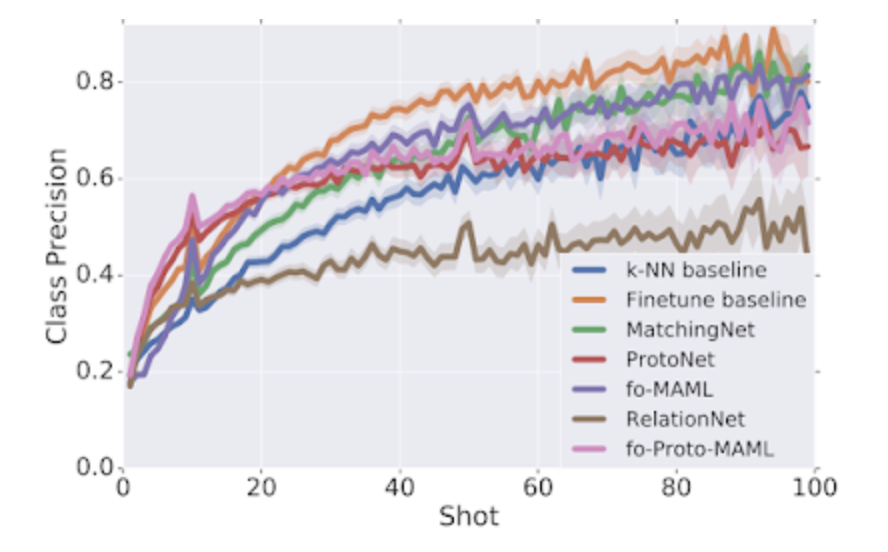
(2)某些模型在测试中对数据的利用更充分
(3)元学习器的自适应算法与其端到端训练(即元学习训练)相比,对性能影响更大
元数据集(Meta-Dataset)为少样本分类带来了新的挑战。研究人员的初步探索,解释了现有方法的局限性,并表明需要进行进一步的研究。
在非元学习领域,最近的工作已经有了一些很不错的成果,例如使用针对任务的巧妙设计,以及更复杂的超参数调整,结合预训练和元学习优势的「元基线」。研究者希望元数据集可以对机器学习这一重要子领域的研究起到更大的推动作用。

登录查看更多
相关内容
专知会员服务
20+阅读 · 2020年2月12日



相关VIP内容
专知会员服务
20+阅读 · 2020年2月12日
相关资讯
相关论文