Transformer变体层出不穷,它们都长什么样?

©PaperWeekly 原创 · 作者|上杉翔二
单位|悠闲会
研究方向|信息检索
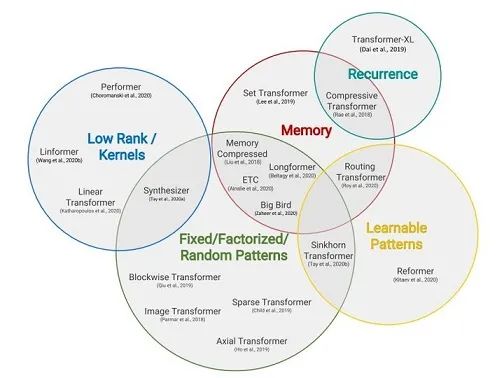


上图上标的是“Recurrence”,首先看看这篇文章聚焦的 2 个问题:
虽然 Transformer 可以学习到输入文本的长距离依赖关系和全局特性,但是!需要事先设定输入长度,这导致了其对于长程关系的捕捉有了一定限制。
-
出于效率的考虑,需要对输入的整个文档进行分割(固定的),那么每个序列的计算相互独立,所以只能够学习到同个序列内的语义联系,整体上看,这将会导致文档语意上下文的碎片化(context fragmentation)。
那么如何学习更长语义联系?
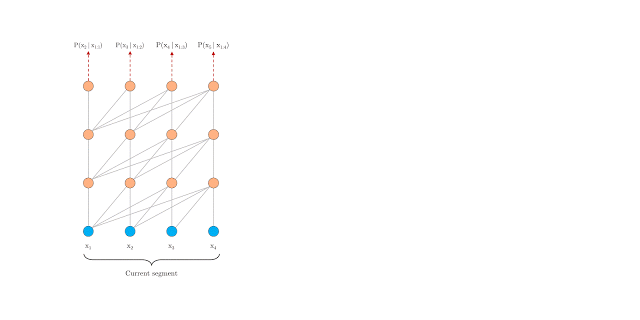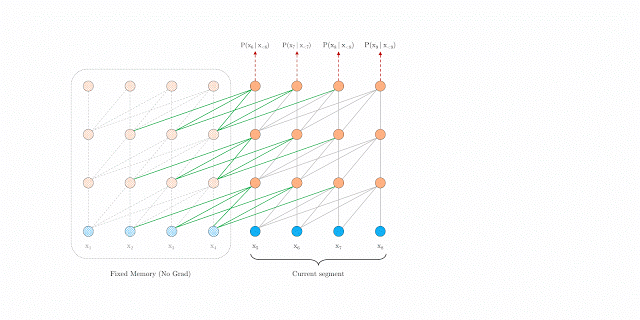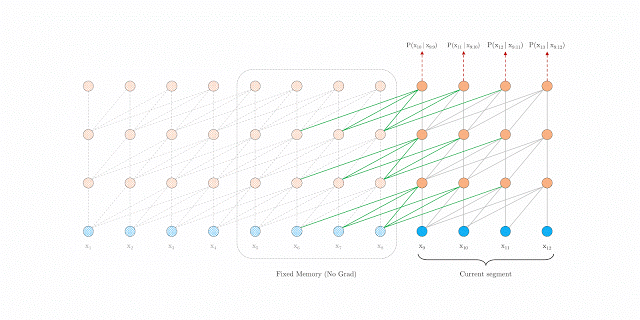
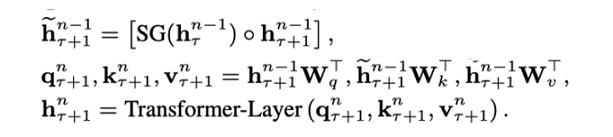
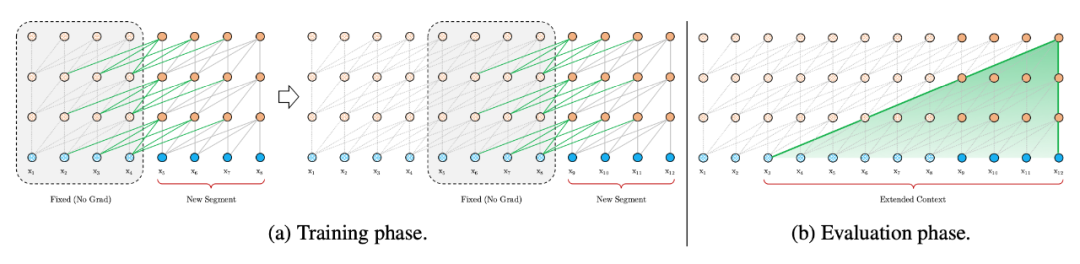
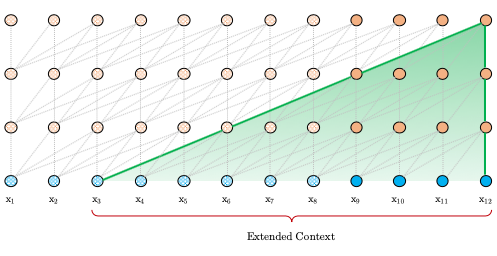
-
其中 SG 是是 stop-gradient,不再对 的隐向量做反向传播(这样虽然在计算中运用了前一个序列的计算结果,但是在反向传播中并不对其进行梯度的更新,毕竟前一个梯度肯定不受影响)。 -
是对两个隐向量序列沿长度 L 方向的拼接 。3 个 W 分别对应 query,key 和 value 的转化矩阵,需要注意的是!k 和 v 的 W 用的是 ,而 q 是用的 ,即 kv 是用的拼接之后的 h,而 q 用的是原始序列的信息。感觉可以理解为以原始序列查拼接序列,这样可以得到一些前一个序列的部分信息以实现跨语义。 -
最后的公式是标准的 Transformer。
def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):
#w是上一层的输出,r是相对位置嵌入(在下一节),r_w_bias是u,r_r_bias是v向量
qlen, rlen, bsz = w.size(0), r.size(0), w.size(1)
if mems is not None: #mems就是前一些序列的向量,不为空
cat = torch.cat([mems, w], 0) #就拼起来
if self.pre_lnorm: #如果有正则化
w_heads = self.qkv_net(self.layer_norm(cat)) #这个net是nn.Linear,即qkv的变换矩阵W参数
else:
w_heads = self.qkv_net(cat)#没有正则就直接投影一下
r_head_k = self.r_net(r)#也是nn.Linear
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1) #复制3份
w_head_q = w_head_q[-qlen:] #q的W不要拼接的mems
else:#没有mems,就正常的计算
if self.pre_lnorm:
w_heads = self.qkv_net(self.layer_norm(w))
else:
w_heads = self.qkv_net(w)
r_head_k = self.r_net(r)
w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)
klen = w_head_k.size(0)
#qlen是序列长度,bsz是batch size,n_head是注意力头数,d_head是每个头的隐层维度
w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
w_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_head
r_head_k = r_head_k.view(rlen, self.n_head, self.d_head) # qlen x n_head x d_head
####计算注意力的四个部分
#AC是指相对位置的公式里的a和c两个部分,相对位置在下一节做笔记
rw_head_q = w_head_q + r_w_bias # qlen x bsz x n_head x d_head
#爱因斯坦简记法求和sum,统一的方式表示各种各样的张量运算
AC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head
#BD是指相对位置的公式里的b和d两个部分
rr_head_q = w_head_q + r_r_bias
BD = torch.einsum('ibnd,jnd->ijbn', (rr_head_q, r_head_k)) # qlen x klen x bsz x n_head
BD = self._rel_shift(BD)
# [qlen x klen x bsz x n_head]
attn_score = AC + BD #最后的结果
attn_score.mul_(self.scale)#进行放缩
Relative Position Encodings
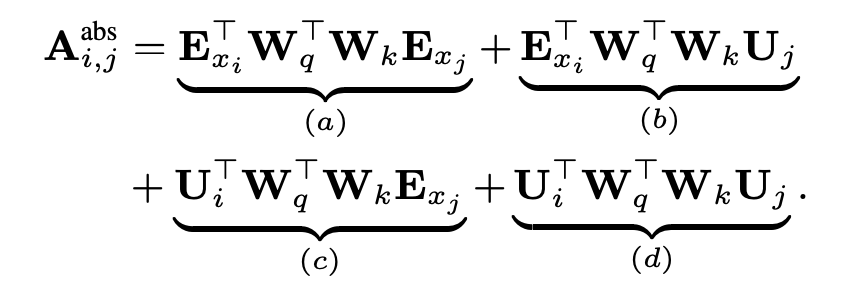
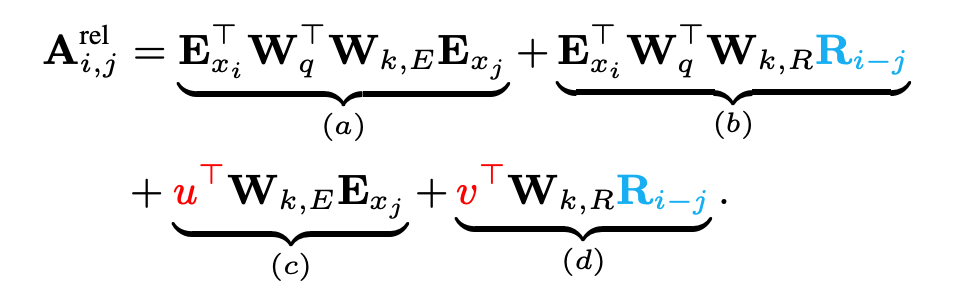
上图是原始 Transformer 和 Transformer-XL 的比较,其中 E 表示词的 Embedding,而 U 表示绝对位置编码。这大一堆看起来奇奇怪怪,实际上 Transformer 的注意力计算是 的分解,即先编码 Q(当前词 i)和 K(其他的词 j)然后算内积,位置编码是直接 add 在词嵌入上面的。
而 Transformer-XL 的改变是:
-
把 j 的绝对位置 U 换成了相对位置 R,该相对位置表示也是一个正弦函数表示(i 和 j 的相对位置向量,j 是之前的序列,所以相减一定是正数)。R 不是通过学习得到的,好处是预测时,可以使用比训练距离更长的位置向量。 -
使用两个可学习参数 u 和 v 替代了中的 query i 的位置映射。这里是由于每次计算 query 向量是固定的,不需要编码。 每一层的 Attention 计算都要相对位置编码。Transformer 里面只有 input 的时候会加,而 XL 需要每层。
-
a. 基于内容的“寻址”,即没有添加原始位置编码的原始向量, 查 。 -
b. 基于内容的位置偏置,即相对于当前内容的位置偏差, 查 。 -
c. 全局的内容偏置,用于衡量 key 的重要性,query 固定查 。 -
d. 全局的位置偏置,根据 query 和 key 之间的距离调整重要性,query 固定查 。
相对位置编码的代码为:
class PositionalEmbedding(nn.Module):
def __init__(self, demb):
super(PositionalEmbedding, self).__init__()
self.demb = demb #编码维度
inv_freq = 1 / (10000 ** (torch.arange(0.0, demb, 2.0) / demb)) #间隔频率
def forward(self, pos_seq):
sinusoid_inp = torch.ger(pos_seq, self.inv_freq) #序列的位置向量 operation 间隔
pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1) #正弦余弦
return pos_emb[:,None,:] #直接返回R,非学习矩阵R
简单把编码维度设置为 10,查询向量也是 10 个,存储之前的序列也是 10,有以下结果:
>>> import torch
>>> inv_freq = 1 / (10000 ** (torch.arange(0.0, 10, 2.0) / 10))
>>> inv_freq
tensor([1.0000e+00, 1.5849e-01, 2.5119e-02, 3.9811e-03, 6.3096e-04])
>>> pos_seq=torch.arange(20-1, -1, -1.0) #qlen+mlen,即10+10的维度然后逆序
>>> pos_seq
tensor([19., 18., 17., 16., 15., 14., 13., 12., 11., 10., 9., 8., 7., 6.,
5., 4., 3., 2., 1., 0.])
>>> sinusoid_inp = torch.ger(pos_seq,inv_freq)
>>> sinusoid_inp
tensor([[1.9000e+01, 3.0113e+00, 4.7726e-01, 7.5640e-02, 1.1988e-02],
[1.8000e+01, 2.8528e+00, 4.5214e-01, 7.1659e-02, 1.1357e-02],
[1.7000e+01, 2.6943e+00, 4.2702e-01, 6.7678e-02, 1.0726e-02],
[1.6000e+01, 2.5358e+00, 4.0190e-01, 6.3697e-02, 1.0095e-02],
[1.5000e+01, 2.3773e+00, 3.7678e-01, 5.9716e-02, 9.4644e-03],
[1.4000e+01, 2.2189e+00, 3.5166e-01, 5.5735e-02, 8.8334e-03],
[1.3000e+01, 2.0604e+00, 3.2655e-01, 5.1754e-02, 8.2024e-03],
[1.2000e+01, 1.9019e+00, 3.0143e-01, 4.7773e-02, 7.5715e-03],
[1.1000e+01, 1.7434e+00, 2.7631e-01, 4.3792e-02, 6.9405e-03],
[1.0000e+01, 1.5849e+00, 2.5119e-01, 3.9811e-02, 6.3096e-03],
[9.0000e+00, 1.4264e+00, 2.2607e-01, 3.5830e-02, 5.6786e-03],
[8.0000e+00, 1.2679e+00, 2.0095e-01, 3.1849e-02, 5.0477e-03],
[7.0000e+00, 1.1094e+00, 1.7583e-01, 2.7867e-02, 4.4167e-03],
[6.0000e+00, 9.5094e-01, 1.5071e-01, 2.3886e-02, 3.7857e-03],
[5.0000e+00, 7.9245e-01, 1.2559e-01, 1.9905e-02, 3.1548e-03],
[4.0000e+00, 6.3396e-01, 1.0048e-01, 1.5924e-02, 2.5238e-03],
[3.0000e+00, 4.7547e-01, 7.5357e-02, 1.1943e-02, 1.8929e-03],
[2.0000e+00, 3.1698e-01, 5.0238e-02, 7.9621e-03, 1.2619e-03],
[1.0000e+00, 1.5849e-01, 2.5119e-02, 3.9811e-03, 6.3096e-04],
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
>>> sinusoid_inp.sin()
tensor([[ 1.4988e-01, 1.2993e-01, 4.5935e-01, 7.5568e-02, 1.1988e-02],
[-7.5099e-01, 2.8479e-01, 4.3689e-01, 7.1598e-02, 1.1357e-02],
[-9.6140e-01, 4.3251e-01, 4.1416e-01, 6.7627e-02, 1.0726e-02],
[-2.8790e-01, 5.6939e-01, 3.9117e-01, 6.3654e-02, 1.0095e-02],
[ 6.5029e-01, 6.9200e-01, 3.6793e-01, 5.9681e-02, 9.4642e-03],
[ 9.9061e-01, 7.9726e-01, 3.4446e-01, 5.5706e-02, 8.8333e-03],
[ 4.2017e-01, 8.8254e-01, 3.2077e-01, 5.1731e-02, 8.2024e-03],
[-5.3657e-01, 9.4569e-01, 2.9688e-01, 4.7755e-02, 7.5714e-03],
[-9.9999e-01, 9.8514e-01, 2.7281e-01, 4.3778e-02, 6.9405e-03],
[-5.4402e-01, 9.9990e-01, 2.4856e-01, 3.9800e-02, 6.3095e-03],
[ 4.1212e-01, 9.8959e-01, 2.2415e-01, 3.5822e-02, 5.6786e-03],
[ 9.8936e-01, 9.5448e-01, 1.9960e-01, 3.1843e-02, 5.0476e-03],
[ 6.5699e-01, 8.9544e-01, 1.7493e-01, 2.7864e-02, 4.4167e-03],
[-2.7942e-01, 8.1396e-01, 1.5014e-01, 2.3884e-02, 3.7857e-03],
[-9.5892e-01, 7.1207e-01, 1.2526e-01, 1.9904e-02, 3.1548e-03],
[-7.5680e-01, 5.9234e-01, 1.0031e-01, 1.5924e-02, 2.5238e-03],
[ 1.4112e-01, 4.5775e-01, 7.5285e-02, 1.1943e-02, 1.8929e-03],
[ 9.0930e-01, 3.1170e-01, 5.0217e-02, 7.9621e-03, 1.2619e-03],
[ 8.4147e-01, 1.5783e-01, 2.5116e-02, 3.9811e-03, 6.3096e-04],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
使用 Transformer-XL 的预训练模型经典的就是 XLNet 啦,可以更好的处理较长的文本。
然后是关于 Transformer 的复杂度问题进行改进的文章。


论文标题:
Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection
论文链接:
https://arxiv.org/abs/1912.11637
代码链接:
https://github.com/lancopku/Explicit-Sparse-Transformer
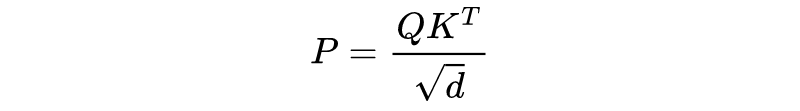
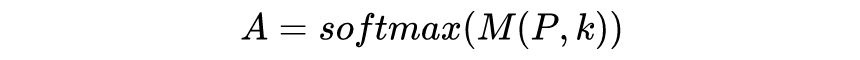
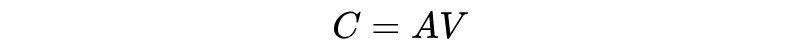


论文标题:
Longformer: The Long-Document Transformer
论文链接:
https://arxiv.org/abs/2004.05150
代码链接:
https://github.com/allenai/longformer
-
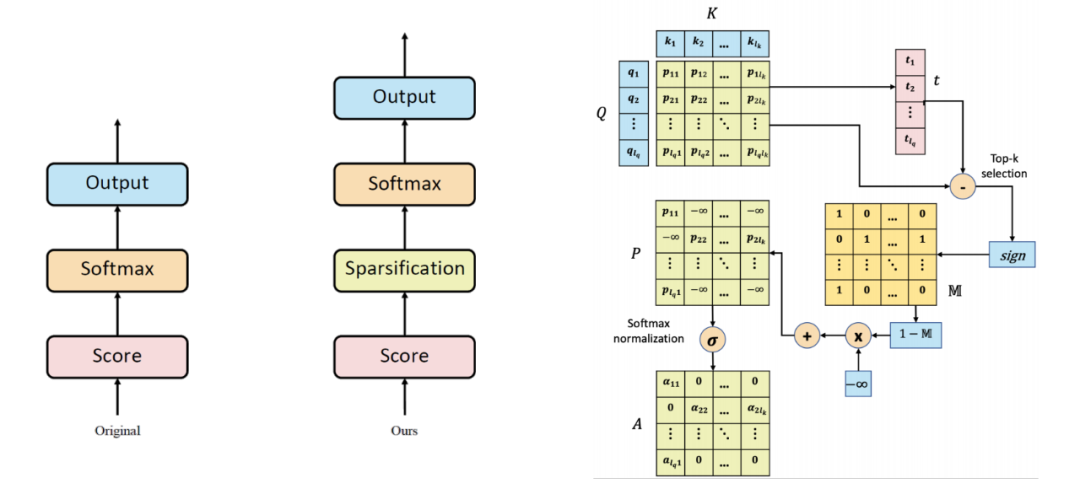
Sliding Window:如上图 (b) 所示,跟 CNN 很像,给定一个固定的窗口大小 w,其两边都有个 w/2 个 token 与其做 attention。计算复杂度降为 O(n x w),即复杂度与序列长度呈线性关系。而且如果为每一层设置不同的窗口 size 可以很好地平衡模型效率和表示能力。
-
Dilated sliding window:如上图 (c) 所示,类似扩张 CNN,可以在计算复杂度不变的情况下进一步扩大接收域。同样的,如果在多头注意力机制的每个头设置不同的扩张配置,可以关注文章的不同局部上下文,特别是通过这种 Dilated 可以扩张甚至很远的地方。
-
Global Attention :如图 (d) 所示,计算全局 token 可能表征序列的整体特性。比如 BERT 中的 [CLS] 这种功能,复杂度降为 O(n)。
完整内容可以看原文。


论文标题:
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
论文链接:
https://arxiv.org/abs/2101.03961
代码链接:
https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
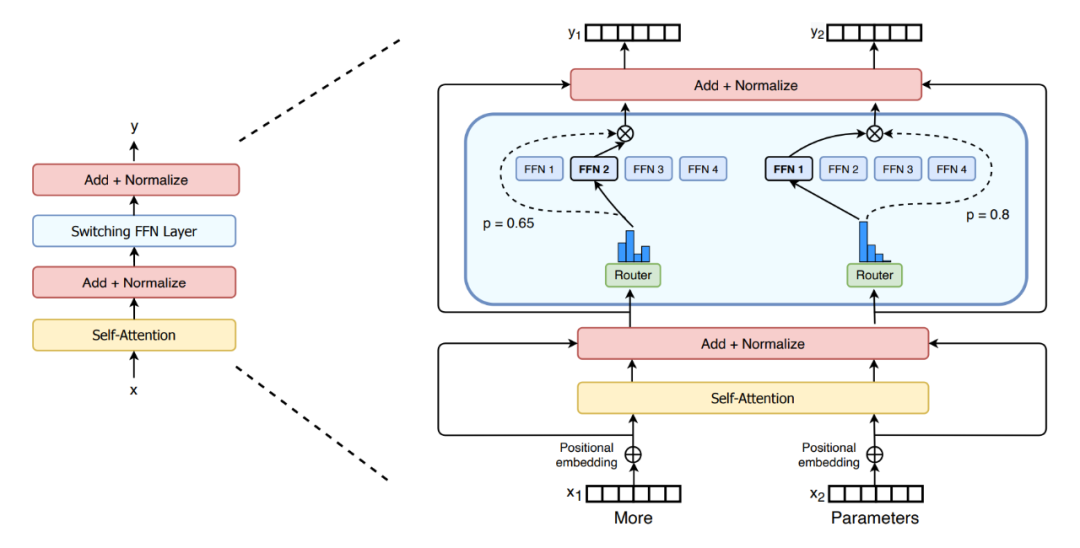
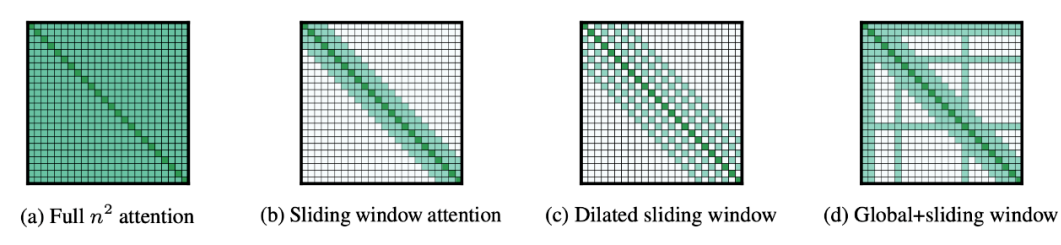
相比起 Sparse Attention 需要用到稀疏算子而很难发挥 GPU、TPU 硬件性能的问题。Switch Transformer 不需要稀疏算子,可以更好的适应 GPU、TPU 等稠密硬件。主要的想法是简化稀疏路由。
即在自然语言 MoE (Mixture of experts)层中,只将 token 表征发送给单个专家而不是多个的表现会更好。模型架构如上图,中间蓝色部分是比价关键的部分,可以看到每次 router 都只把信息传给分数 p 最大的单个 FFN。而这个操作可以大大降低计算量。

Routing Transformers

论文标题:
Efficient Content-Based Sparse Attention with Routing Transformers
收录会议:
TACL 2020
论文链接:
https://arxiv.org/abs/2003.05997
代码链接:
https://github.com/google-research/google-research/tree/master/routing_transformer
和前两篇文章的目标一样,如何使标准 Transformer 的时间复杂度降低。Routing Transformer 将该问题建模为一个路由问题,目的是让模型学会选择词例的稀疏聚类,所谓的聚类簇是关于每个键和查询的内容的函数,而不仅仅与它们的绝对或相对位置相关。
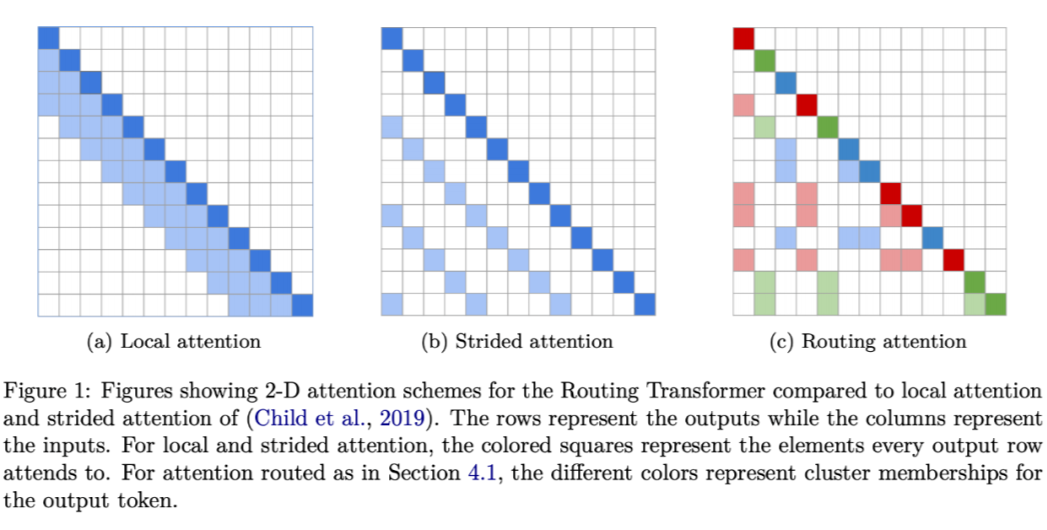
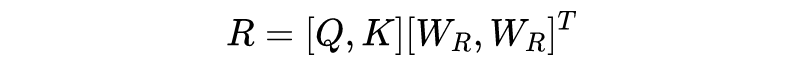
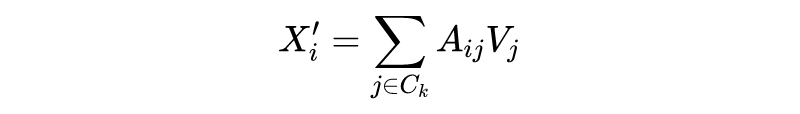

Linformer

论文标题:
Linformer: Self-Attention with Linear Complexity
论文链接:
https://arxiv.org/abs/2006.04768
代码链接:
https://github.com/tatp22/linformer-pytorch
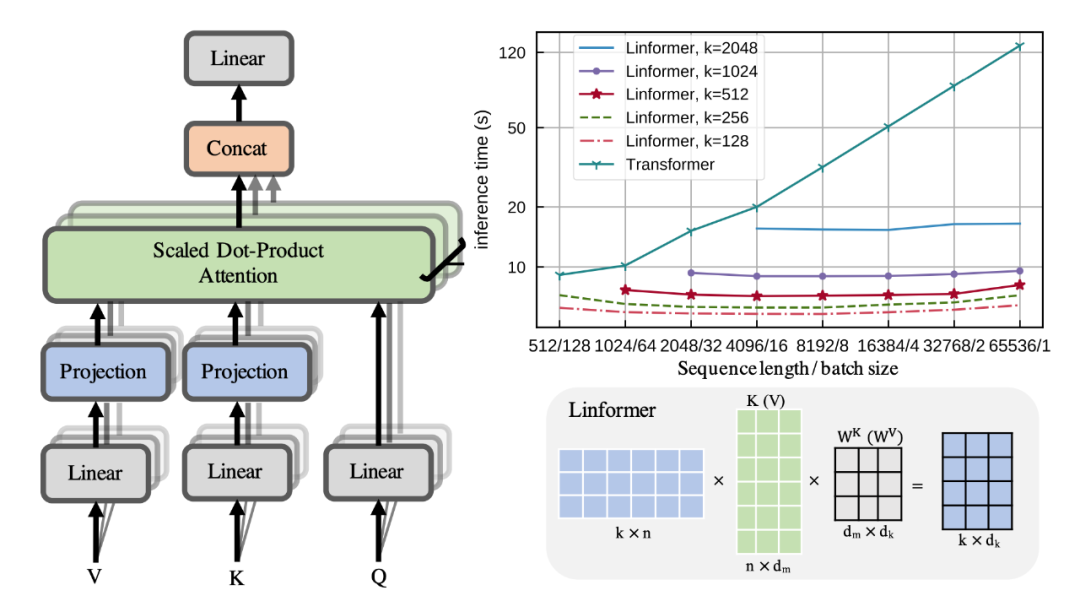
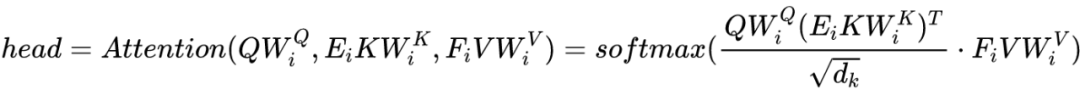
同时还提供三种层级的参数共享:
-
Headwise: 所有注意力头共享投影句子参数,即 Ei=E,Fi=F。 Key-Value: 所有的注意力头的键值映射矩阵共享参数同一参数 ,即 Ei=Fi=E。
-
Layerwise: 所有层参数都共享。即对于所有层,都共享投射矩阵 E。
完整内容可以看原文,原文有理论证明低秩和分析。

Big Bird

论文标题:
Big Bird: Transformers for Longer Sequences
论文链接:
https://arxiv.org/abs/2007.14062
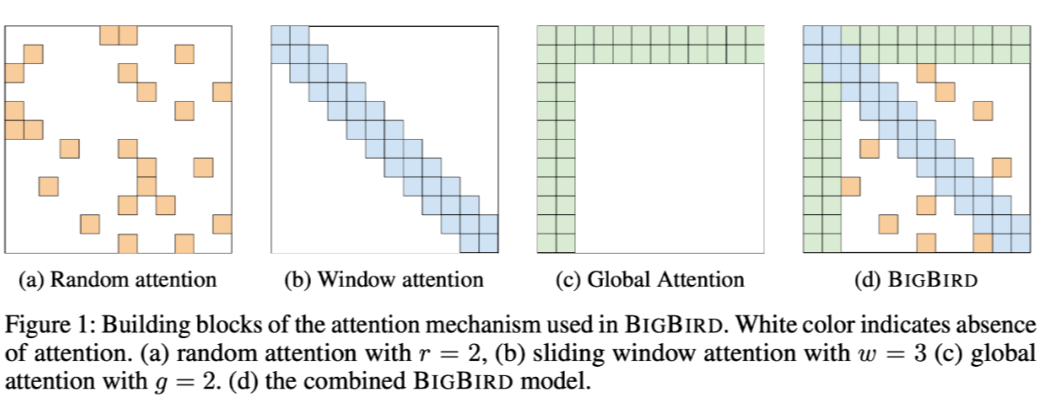
-
Random Attention(随机注意力)。如图 a,对于每一个 token i,随机选择 r 个 token 计算注意力。 -
Window Attention(局部注意力)。如图 b,用滑动窗口表示注意力计算 token 的局部信息。 Global Attention(全局注意力)。如图 c,计算全局信息。这些在 Longformer 中也讲过,可以参考对应论文。
最后把这三部分注意力结合在一起得到注意力矩阵 A,如图 d 就是 BIGBIRD 的结果了,计算公式为:
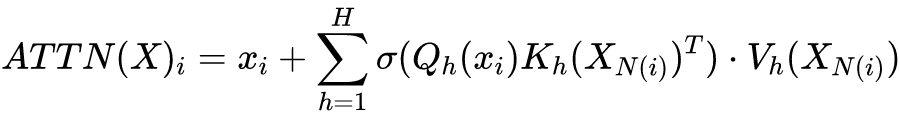
H 是头数,N(i) 是所有需要计算的 token,这里就是由三部分得来的稀疏部分,QKV 则是老伙伴了。
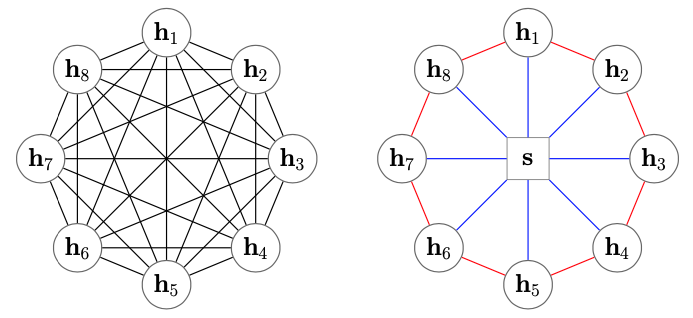

Star-Transformer

论文标题:
Star-Transformer
收录会议:
NAACL 2019
论文链接:
https://arxiv.org/abs/1902.09113
代码链接:
https://github.com/fastnlp/fastNLP
问题:
Transformer 的自注意力机制每次都要计算所有词之间的注意力,其计算复杂度为输入长度的平方,结构很重
在语言序列中相邻的词往往本身就会有较强的相关性,似乎本来就不需要计算所有词之间
解决:
Star-Transformer 用星型拓扑结构代替了全连通结构如上图左边是 Transformer,而右边是 Star-Transformer。在右边的图中,所有序列中直接相邻的词可以直接相互作用,而非直接相邻的元素则通过中心节点实现间接得信息传递,因此,复杂性从二次降低到线性,同时保留捕获局部成分和长期依赖关系的能力。
Radical connections,捕捉非局部信息。即每两个不相邻的卫星节点都是两跳邻居,可以通过两步更新接收非局部信息。
Ring connections,捕捉局部信息。由于文本输入是一个序列,相邻词相连以捕捉局部成分之间的关系。值得注意的是它第一个节点和最后一个节点也连接起来,形成环形连接。

-
在初始化阶段,卫星节点(周围的词节点)的初始值为各自相应的词向量 ,而中心节点(集成节点)的初始值为所有词节点词向量的平均值 。 -
更新卫星节点。对于某卫星节点 ,先得到它的上下文信息 ,它由相邻节点 ,中心节点 ,和这个节点对应的 token 词嵌入 组成。然后多头注意力更新特征,最后使用层归一化。 -
更新中心节点(relay node)。中心节点与上一时刻和所有卫星信息的交互,所以同样是多头注意力 ,H 是可学习的位置编码(它在所有时刻都是一样的)。 -
交替更新 T 步,over。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





