超越Transformer!AAAI 2021最佳论文:高效长序列预测模型

©PaperWeekly 原创 · 作者|西南交一枝花
学校|西南交通大学CCIT实验室博士生
研究方向|NLP、时空数据挖掘

前言

论文标题:
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
论文链接:
https://arxiv.org/abs/2012.07436
源码链接:
https://github.com/zhouhaoyi/ETDataset

研究动机
针对第三点,展开来说香草变压器解决 LSTF 问题有三点不足:
1. 自注意力机制的平方级计算时间复杂度;
2. Transformer 通常堆叠多层网络,导致内存占用瓶颈;
3. step-by-step 解码预测,使得推理速度慢。
同时,上述三点对应 Informer 的主要贡献点:
1. ProbSparse self-attention,笔者称其为概率稀疏自注意力,通过“筛选”Query 中的重要部分,减少相似度计算;
2. Self-attention distilling,笔者称其为自注意力蒸馏,通过卷积和最大池化减少维度和网络参数量;
3. Generative style decoder,笔者称为生成式解码器,一次前向计算输出所有预测结果。

3.1 输入输出形式化表示
输入: 时间 t
3.2 编解码结构
3.3 输入表示
RNN 由于其递归循环结构可以捕获时序模式,但只依赖于时间序列。Vanilla Transformer 使用点乘注意力,没有循环结构,为捕获时序,使用位置编码。
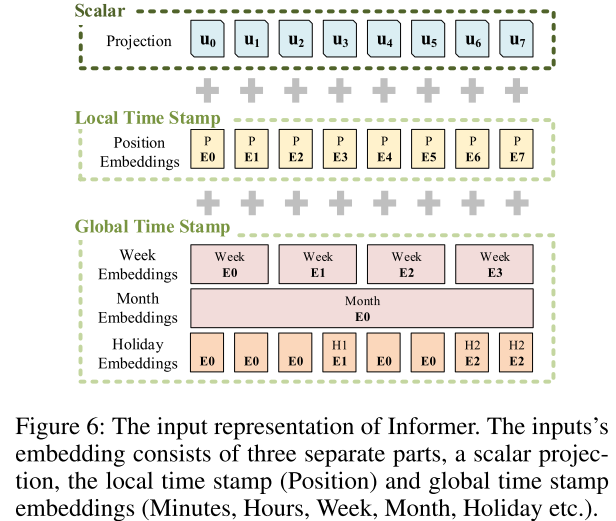
局部时间戳。即 Transformer 中的固定位置嵌入。计算方式为:, 。
-
全局时间戳。这里使用的可学习嵌入表示 。具体实现时,构建一个词汇表(文中给定 60 大小,以分钟最为最小单位,与图不对应),使用 Embedding 层表示每一个“词汇”。 -
为对齐维度,使用 1D 卷积将输入标量 转为向量 ,计算方法为:

方法介绍
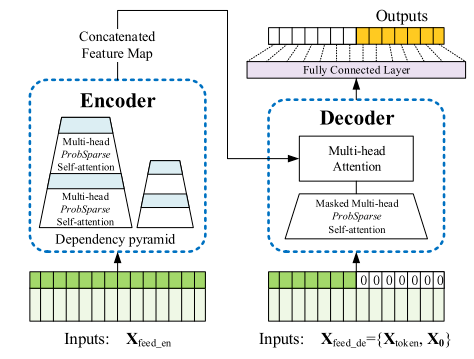
左边:编码过程,编码器接收长序列输入(绿色部分),通过 ProbSparse 自注意力模块和自注意力蒸馏模块,得到特征表示。(堆叠结构增加模型鲁棒性)。
4.1 高效的自注意力机制
自荐一下,笔者以前分享过注意力机制,感兴趣的可以点击查看 Attention 注意力机制的前世今身。
首先,回顾经典的自注意力机制。接收三个输入(query, key, value),使用缩放点积计算三者的公式为:。
接着,为进一步探索自注意力机制,按行说明自注意力计算方式。
-
分别为 Q, K, V 的第 i 行; -
第i个query的注意力可以定义为核平滑的概率形式: -
,计算该概率的时间复杂度为平方级,并且需要 的空间复杂度。
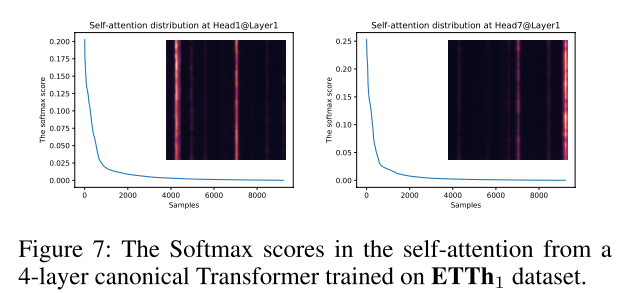
最后,针对如何区分注意力计算中哪些是可忽略的问题,作者进行了下面的工作。首先是 Query 稀疏度的度量方法;然后根据“筛选”后的 Query,提出 ProbSparse Self-attention,计算自注意力得分。
经过简化后,作者定义第 i 个 Query 的稀疏性度量公式为:。如果第 i 个 query 的 M 值较大,说明它的注意力概率 p 相较其他部分差异性较大,比较大可能性是重要性部分。
4.2 编码器
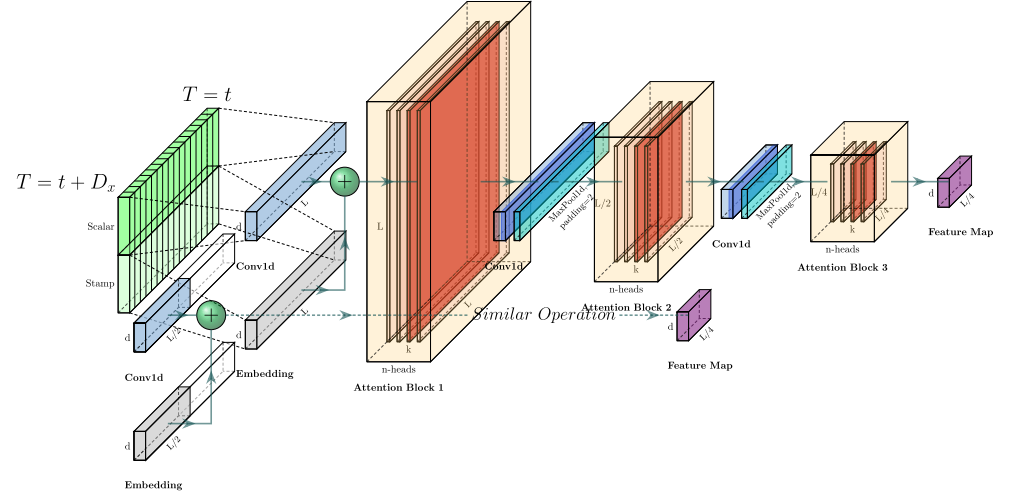
4.3 解码器

5.1 数据集
5.2 基准模型
1.ARIMA 2. Prophet 3. LSTMa 4. LSTnet 5. DeepAR.
5.3 超参设置

无论是单变量的长序列预测还是多变量的长序列预测,Informer 均能在多数数据集上取得最优表现。
从单变量预测来看,1. 在两种评测指标上,Informer 能够取得不错的提升,并且随着预测序列长度的增加,推理速度和预测误差增长地较为缓慢;2. Informer 相较原始自注意力的 infomer,取得最优的次数最多(28>14),并且优于 LogTansformer 和 Reformer;3. Informer 相较 LSTMa 有巨大的提升,说明相较 RNN 类模型,自注意力机制中较短网络路径模型具有更强的预测能力。
5.6 消融实验

Informer 能获得 AAAI 的 Best Paper 确实有很多值得肯定的地方。首先,在阅读体验上,笔者很好地顺着作者的逻辑结构了解到本工作的研究动机、研究内容,讲故事的能力确实很重要。
此外,实验部分比较充实,能够很好地 cover 全文一直提及的 LTSF 的难点以及 Transformer 应用到 LTSF 上需要解决的问题。在研究内容上,笔者觉得能获得最佳论文奖项,肯定不是靠纯堆模型。确实,本文在 fundamental 内容(ProbSparse self-attention)上也做了很多探索研究。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





