【泡泡图灵智库】DeepVO:基于深度循环卷积神经网络的端到端视觉里程计(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks
作者:Sen Wang, Ronald Clark, Hongkai Wen and Niki Trigoni
来源:ICRA2017
编译:尹双双
审核:杨健博
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

今天介绍的文章是“DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks”——DeepVO:基于深度循环卷积神经网络的端到端视觉里程计,该文章将发表在ICRA2017。
单目视觉里程计(Visual odometry,VO)是机器视觉领域一项重要的研究问题,目前大多数视觉里程计方法都是基于标准框架开发的,包括特征提取,特征匹配,运动估计,局部优化等模块。尽管其中一些方法已经展现了优越的性能,但通常仍需要精心设计和专门进行微调才能适应不同的任务和环境需求,而且单目视觉里程计缺失尺度信息,往往需要一些先验知识来恢复绝对尺度估计。本文使用深度递归卷积神经网络(RCNNs),提出了一种新颖的端到端单目VO的框架。由于它是以端到端的方式进行训练和配置的,因此它可以直接从一系列原始的RGB图像(视频)中计算得到姿态,而无需采用任何传统VO框架中的模块。基于RCNN,一方面它可以通过卷积神经网络(Convolutional Neural Network)自动学习VO问题的有效特征表示,另一方面可以通过递归神经网络(Recurrent Neural Network)对时序模型(运动模型)、数据关联模型(图像序列)进行隐式建模。最后,作者在KITTI VO数据集上进行大量实验,显示提出的方法能与目前最先进方法抗衡,也验证了端到端的深度学习技术可以成为传统VO系统的一种可行的补充。
主要贡献
1) 用基于深度学习端对端的方式解决单目视觉里程计问题,即直接从原始RGB影像估计位姿,不需要先验知识或者参数来恢复绝对尺度;
2) 提出一种RCNN框架,利用CNN学习的几何特征表示,可以将基于VO算法的DL泛用到完全新的环境中。
3) 人工难以明确或简单地实现的影像序列的数据关联模型和运动模型,通过深度递归神经网络(RNNs)隐式封装和自动学习。
算法流程
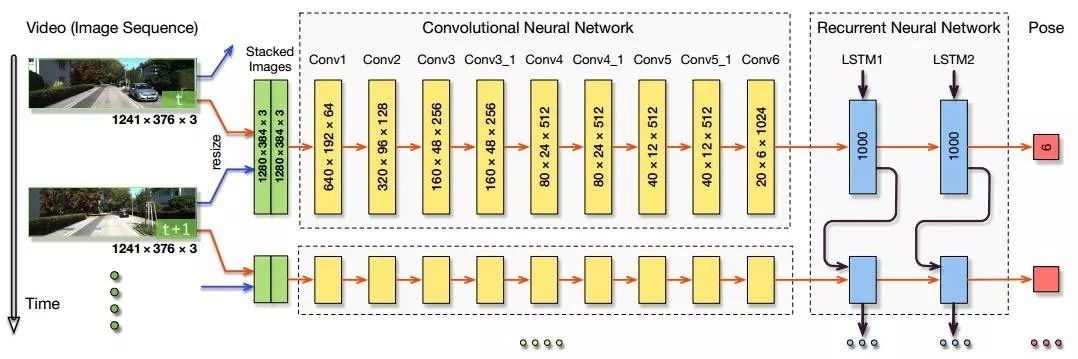
图2.本文提出的基于RCNN的单目VO系统结构图
提出的RCNN架构
如图2所示,输入一段视频剪辑或者单目影像序列,在每个时间间隔,RGB影像帧在预处理中减去训练集的平均RGB值和可选地调整影像大小为64的倍数。两张连续影像堆叠在一起构成一个张量,用于深度RCNN学习怎样提取运动信息和估计位姿。特别地,影像张量被放入CNN来得到单目VO的有效特征,然后传递给一个RNN进行序列的学习。在每个时间间隔里通过网络每个影像对产生一个位姿估计。VO系统随时间进展和随影像捕获估计新的位姿。
2. 基于特征提取的CNN
特征表示应该是理想几何,而不是与表面和视觉纹理相关,因为VO系统需要泛化和扩展到未知地环境中去。本文CNN结构受光流估计的网络启发,配置信息如表1所示,在图2 中给出了一个KITTI数据集的张量例子。
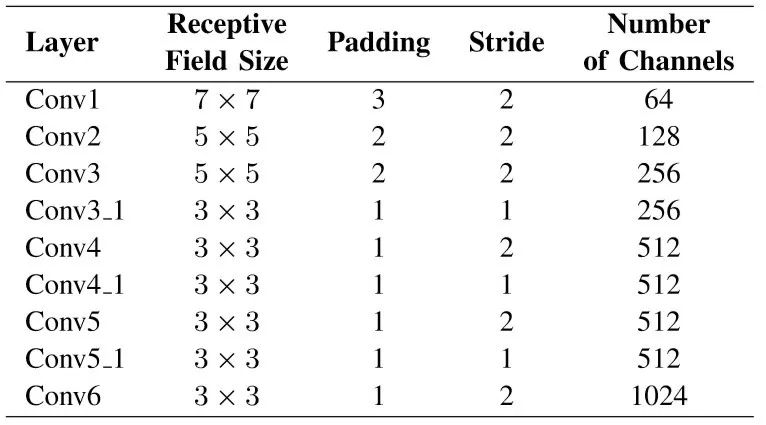
表1 CNN的配置
3. 基于序列建模的RNN
在CNN之后,设计一个RNN来运行序列的学习,即在CNN特征序列中对运动模型和数据关联模型进行隐式建模。因为RNN不适合直接学习来自高维原始数据的序列表示,所以本文提出的系统采用CNN特征作为RNN架构的输入。在时间k给出一个卷积特征xk,一个RNN更新:
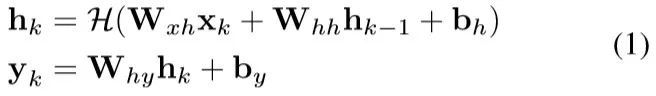
其中hk和yk分别表示在时间k的隐藏状态和输出,W表示相关权重矩阵,b表示偏差矢量,H表示逐元素非线性激活函数,比如sigmoid或者hyperbolic tangent。
为了找到和应用长距离影像之间的关联性,我们RNN采用可以学习长期依赖的LSTM。它可以明确地确定哪些先前隐藏状态可以丢弃或者保留来更新当前状态,可在位姿估计时学习运动。折叠的LSTM和它随时间的展开如图3所示,还有一个LSTM单元的内部结构。
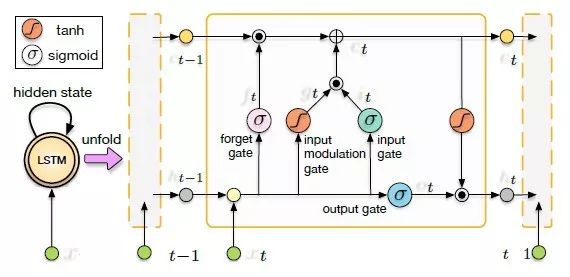
图3 折叠的和展开的LSTMs和它单元体的内部结构。
LSTM在时间k的更新:
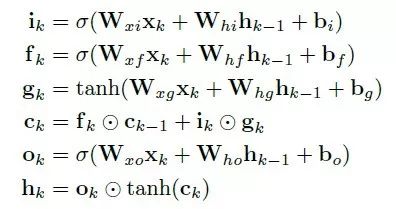
尽管LSTM可以处理长期性依赖和具有深度时间结构,它仍然需要网络层的深度来学习高阶的表示和模型化复杂的动态。因此本文将两个LSTM层堆叠在一起构建一个深度RNN,基于从CNN获取的视觉特诊,在每个时间间隔输出一个位姿估计。整个过程随着相机运动和影像获取进行。
4. 代价函数和优化
提出的基于VO系统的RCNN可以看作是计算一组给出的单目RGB影像Xt=(x1,…,xn)的位姿Yt=(y1,…,yn)随时间的条件概率:
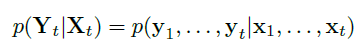
在深度RCNN中实现进建模和概率推断。为了找到VO的优化参数θ*,DNN最大化:
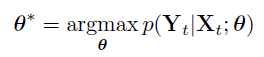
为了学习DNNs的参数θ,最小化在时间k的地面真实位姿(pk,φk)和它们的估计值之间的欧式距离。损失函数由所有的位置p和方向φ的均方差(MSE)组成:
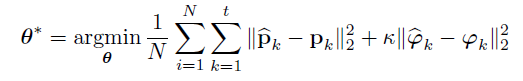
主要结果
1、 训练和测试
图2总结了所有15个试验的结果。这表明所提出的系统可以在没有事先初始化的情况下通过定制的传感器配置正常工作。
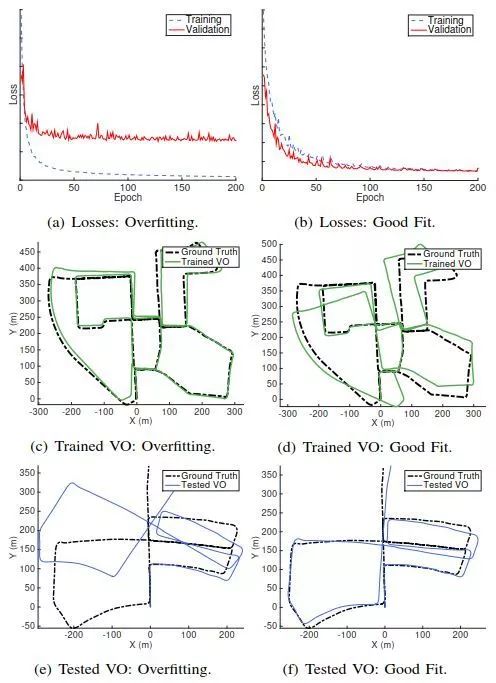
图4 训练losses和两个模型的VO结果
2、VO结果
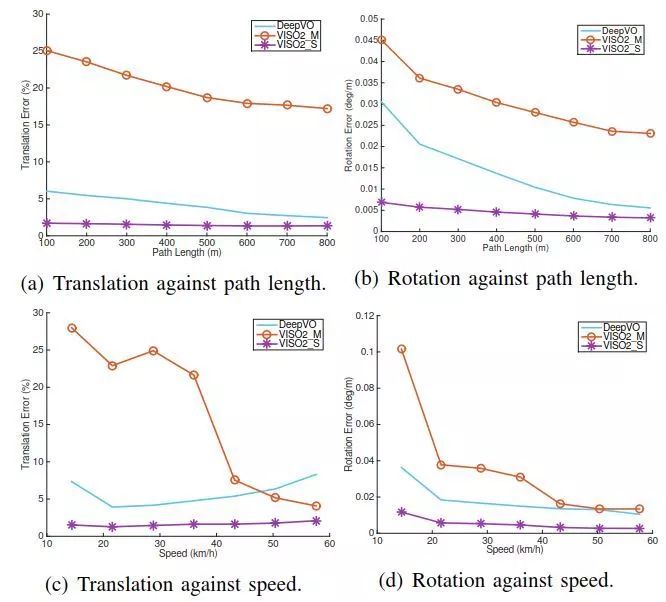
图5 不同路径长度和速度的平移和旋转平均误差。DeepVO模型是在序列00,02,08和09上训练的。
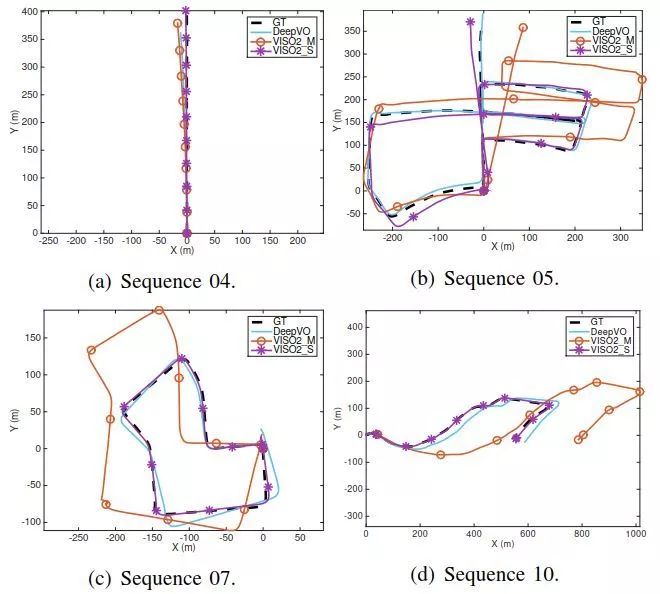
图6 在序列04,05,07和10上的VO测试结果轨迹。DeepVO模型是在序列00,02,08和09上训练的。
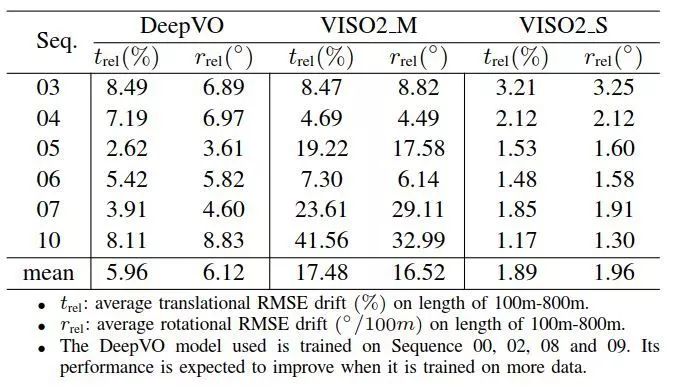
表2 测试序列结果
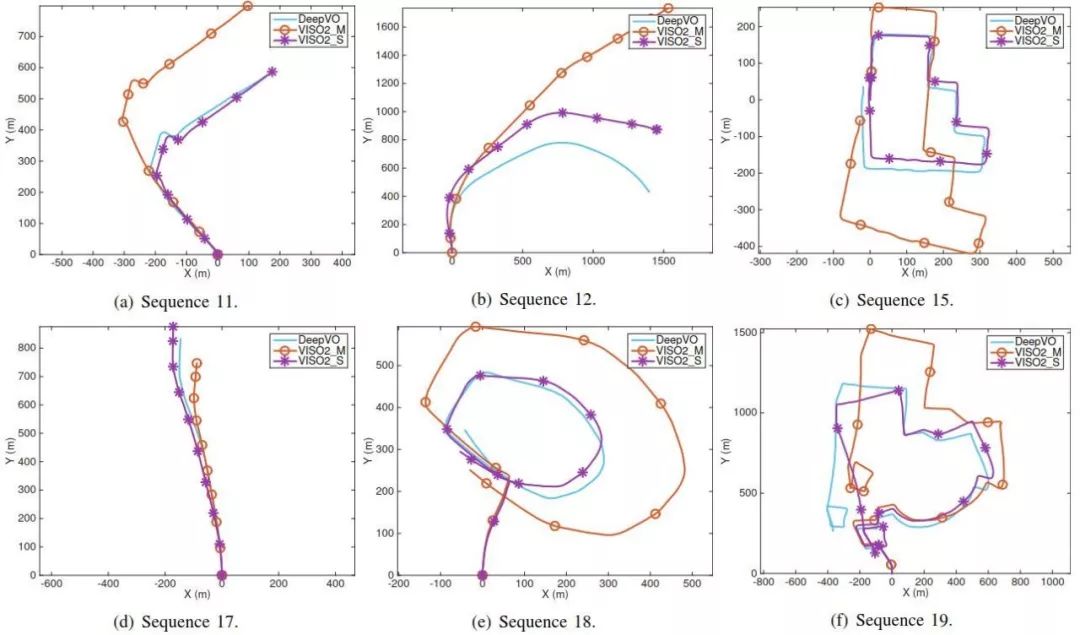
图8 在KITTI VO基准序列11,12,15,17,18和19(这些测试序列没有真值)上VO测试的轨迹。 使用的DeepVO模型是在KITTI VO的整个训练数据集上训练的。

Abstract
This paper studies monocular visual odometry (VO) problem. Most of existing VO algorithms are developed under a standard pipeline including feature extraction, feature matching, motion estimation, local optimisation, etc. Although some of them have demonstrated superior performance, they usually need to be carefully designed and specifically fine-tuned to work well in different environments. Some prior knowledge is also required to recover an absolute scale for monocular VO. This paper presents a novel end-to-end framework for monocular VO by using deep Recurrent Convolutional Neural Networks (RCNNs) 1. Since it is trained and deployed in an
end-to-end manner, it infers poses directly from a sequence of raw RGB images (videos) without adopting any module in the conventional VO pipeline. Based on the RCNNs, it not only automatically learns effective feature representation for the VO problem through Convolutional Neural Networks, but also implicitly models sequential dynamics and relations using deep Recurrent Neural Networks. Extensive experiments on the KITTI VO dataset show competitive performance to state-of-the-art methods, verifying that the end-to-end Deep Learning technique can be a viable complement to the traditional VO
systems.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



