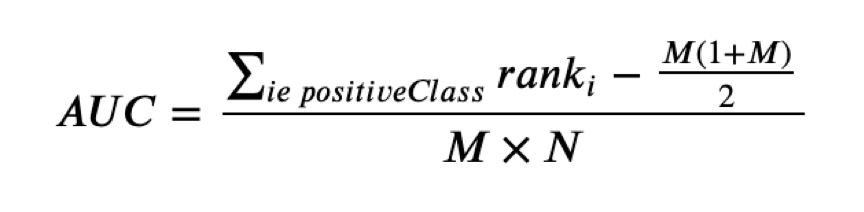![]()
2019 年 9 月,北京智源人工智能研究院联合知名的综合性社区平台知乎、数据评测平台 biendata,共同发布了近 200 万用户和 1000 万邀请数据的 Link prediction 大型数据集,并同步开放了评测竞赛(2019 年 9 月-11 月下旬),总奖金 10 万元。
本数据集包含知乎脱敏后的近 200 万用户数据、1000 万条邀请记录数据,以及 10 万个话题数据、180 万个问题和 475 万个回答数据,覆盖了问题话题文本、用户画像、行为历史、用户关系等多种不同的数据类型,聚焦于 Link prediction,专家发现和推荐系统等问题,以及这些问题在问答社区上的应用。
此外,依托本数据集,智源、知乎和 biendata 还联合发布了一次数据评测。评测将持续 3 个月时间,于 11 月下旬结束。评测总奖金为 10 万元人民币。比赛网址请见下方二维码或点击“阅读原文”链接。
![]()
比赛平台地址:
https://www.biendata.com/competition/zhihu2019/
知识分享服务已经成为目前全球互联网的重要、最受欢迎的应用类型之一。但是在知识分享或问答社区中,问题数远远超过有质量的回复数。因此,如何连接知识、专家和用户,增加专家的回答意愿,成为了此类服务的中心课题。本数据集和评测旨在解决这一问题。
知乎是中文互联网知名的综合性社区平台。知乎自 2011 年创办至今,已经成为一个拥有 2.2 亿用户,每天有数以十万计的新问题以及 UGC 内容产生的网站。其中,如何高效的将这些用户新提出的问题邀请其他用户进行解答,以及挖掘用户有能力且感兴趣的问题进行邀请下发,优化邀请回答的准确率,提高问题解答率以及回答生产数,成为知乎最重要的课题之一。
▶▷ 文本数据
文本数据主要包括知乎话题、问题,以及回答的文本数据。这些数据通过两种方式加密:
1)单字,以 64 维 embedding 的表示。单字包括单个汉字、中韩文字、英文字母、标点及空格等;词语包含切词后的中文词语、英文单词、标点及空格等。
2)词语,以 64 维 embedding 的表示。提醒:单字 ID 和词语 ID 存在于两个不同的命名空间,即词语中某个字或标点,和单字中的相同字符及相同标点不一定有同一个 ID。
▷▶ 问题数据(183万)
问题数据除了上述提到的问题标题和描述的单字编码、切词编码,绑定话题外,还包括提问时间和提问者 ID。
▷▶ 回答数据(475万)
回答数据包括:回复的问题 ID,回答创建时间;是否包括图片、视频,以及答案长度;回答内容的单字编码序列和切词编码序列;回答是否被标为优秀、推荐、被收入圆桌,以及回答的点赞数、评论数、被收藏数、感谢数、被举报数、反对数等。
用户性别、关键词、创作数量级、创作热度、注册类型和平台、访问频率,以及其他一些匿名特征(如所在省份等信息)。
▷▶ 邀请行为数据集(训练集1016万,验证集125.5万)
4)邀请是否被回答, 值为 1 表示被回答, 为 0 表示没有被回答。
▶▷ 任务描述
评测要求选手根据提供的数据集和 1000 万条带标签的邀请数据,预测验证集中用户是否会接受某个新问题的邀请。
使用 AUC 对参赛队伍提交的数据与真实的数据进行衡量评估:
![]()
LinkPrediction 和专家发现是数据挖掘、社交网络分析等领域的重要课题。
2015 年,香港科技大学的 Wilfred Ng、浙江大学的何晓飞和南京大学的张利军在 TKDE 上发表论文,他们抓取了国外著名问答网站 Quora 上 2012 年 9 月至 2013 年 8 月的 44 万个问题、88 万多个回答和近 9.6 万个用户的数据。在论文中,他们从缺失值估计的视角处理专家发现问题,并通过用户的社交网络和基于图的正则化矩阵补全算法(graph-regularized matrix completion algorithm)推断用户模型。此外,论文作者还提出了两个适合图正则化的优化算法
[1]
。
2016 年,浙江大学的庄越挺、何晓飞等人在 IJCAI 上也发表了一篇问答社区中专家发现的论文。他们把问题的语义表示和问答社区的网络结构整合成一个统一的框架,可以定量分析任意一个用户对任意一个问题回答的质量,然后又发明了一个基于随机游走的学习方法,通过深度递归神经网络学习定量问题和用户之间质量关系的嵌入表示,最终找到最适合回答某个问题的用户
[2]
。
此外,还有一些其他的研究也探索了相关问题
[3][4][5][6][7]
。
然而,除了找到问题最合适的用户,也需要那位用户对问题感兴趣才行。但上文提到的研究没有考虑专家的意愿
[8]
。2016 年,中国人工智能学会、字节跳动和 biendata.com 联合组织了一次评测,目标为预测专家对被推送问题的回答率。比赛吸引了超过一千名选手参加,在学术界和工业界都引发了广泛的影响。在学术领域,产生了基于该数据集的研究论文
[8]
,教育界也使用该数据作为课程项目
[9][10]
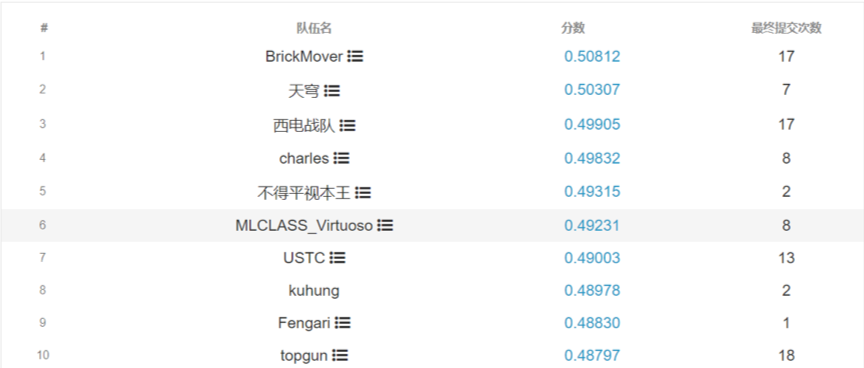
。该比赛增加了专家意愿数据,如回答历史纪录和回答内容质量,因此比赛获奖模型提升了性能,冠军团队的 NDCG@5 * 0.5 + NDCG@10 * 0.5 分数为0.50812
[8]
。
![]()
▲
图:2016 Byte Cup国际机器学习竞赛最终得分排名
与同类数据集相比,本次来知乎的数据集进一步提升了以下几方面:
1)数据集规模。知乎目前是中国乃至世界最大的知识分享社区。数据集中的用户数超过了类似数据集。其他方面的数据规模也比一般的同类数据大得多。
2)数据集维度。传统的社区数据集往往缺少隐性反馈行为(implicit feedback),影响了模型最后的性能。这一点在之前对该数据进行研究的文献中亦有提及 [1]。而本次知乎数据集包括了大量的隐性反馈行为信息,包括对不同话题、问题的关注,以及回答的文本等内容。
3)很多数据集缺乏文本信息,或采用了独特的文本加密方法,也没有提供额外的语料协助参赛者训练语言模型。而知乎数据集将提供大量文本数据供选手挖掘其中的语义。
[1]Zhou Zhao, Qifan Yang, Deng Cai, Xiaofei He, Yueting Zhuang., “Expert Finding for Community-Based Question Answering via RankingMetric Network Learning,” IJCAI 2016.
[2] Z.Zhao, X. He, D. Cai, L. Zhang, W. Ng, and Y. Zhuang., “Graph RegularizedFeature Selection with Data Reconstruction,” IEEE Transactions on Knowledge andData Engineering (TKDE), 28(3): 689 - 700, 2016.
[3] F. Riahi, Z. Zolaktaf, M. Shafiei, and E. Milios,“Finding expert users in community question answering,” Topic Models ExpertRecommender, pp. 791–798, 2012.
[4] Z. Zhao, Q. Yang, D. Cai, X. He, and Y. Zhuang,“Expert finding for community-based question answering via ranking metric network learning,” in International Joint Conference on ArtificialIntelligence, 2016, pp. 3000–3006.
[3] F. Han, S. Tan, H. Sun, M. Srivatsa, D. Cai, andX. Yan, “Distributed representations of expertise,” in Siam InternationalConference on Data Mining, 2016, pp. 531–539.
[5] K. Balog, Y. Fang, M. De Rijke, P. Serdyukov, andL. Si, “Expertise retrieval,” Foundations and Trends in Information Retrieval,vol. 6, no. 23, pp. 127–256, 2012.
[6] X. Liu, M. Koll, and M. Koll, “Finding experts incommunity based question-answering services,” in ACM International Conferenceon Information and Knowledge Management, 2005, pp. 315–316
[7] Yuan, S., Zhang, Y., Tang, J. et al. Artif IntellRev (2019). https://doi.org/10.1007/s10462-018-09680-6
[8] Saeed, M., Hundekar, M., Kothari A. CSCI567 Project:Byte Cup 2016 (2016).https://pdfs.semanticscholar.org/8213/6507ed7e400bc8e41a22d47ae13984e4e062.pdf
[9] Zhou, Q., Yang, L., Legassick, C. CS 567 ProjectReport (2016)
http://qijiazhou.me/pdf/bytecup-2016.pdf
智源研究院后续更多竞赛与活动,请关注研究院公众号(baaibjkw,二维码见下),以及大赛首页(
biendata.com/baai
)。
![]()
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
▽ 点击 | 阅读原文 | 报名参赛