EMNLP 2019丨微软提出显式跨语言预训练模型CMLM,显著提升无监督机器翻译性能
编者按:现有预训练模型的跨语言信息只通过共享 BPE 空间得到,这样得到的跨语言信号隐式而且受限。微软亚洲研究院提出了一种跨语言掩码语言模型(Cross-lingual masked language model,CMLM),可以显式地将跨语言信息作为训练信号,显著提升预训练模型的跨语言建模能力,进而提升无监督机器翻译的性能。
对于无监督机器翻译而言,跨语言预训练模型(XLM[1])已被证实是有作用的。但是现有的工作中,预训练模型的跨语言信息只是通过共享 BPE[2] 空间得到。这样得到的跨语言信号非常隐式,而且很受限,对于语系不同的语言对来说(比如中-英),BPE 符号只有少量是共享的。为解决该问题,我们提出了一种新的方法,即跨语言掩码语言模型(Cross-lingual masked language model,CMLM),它可以将显式的跨语言信息作为训练信号,更好地训练跨语言预训练模型。实验证明我们提出的预训练方法可以显著提升预训练模型的跨语言建模能力,进而提升无监督机器翻译的性能。
训练方法
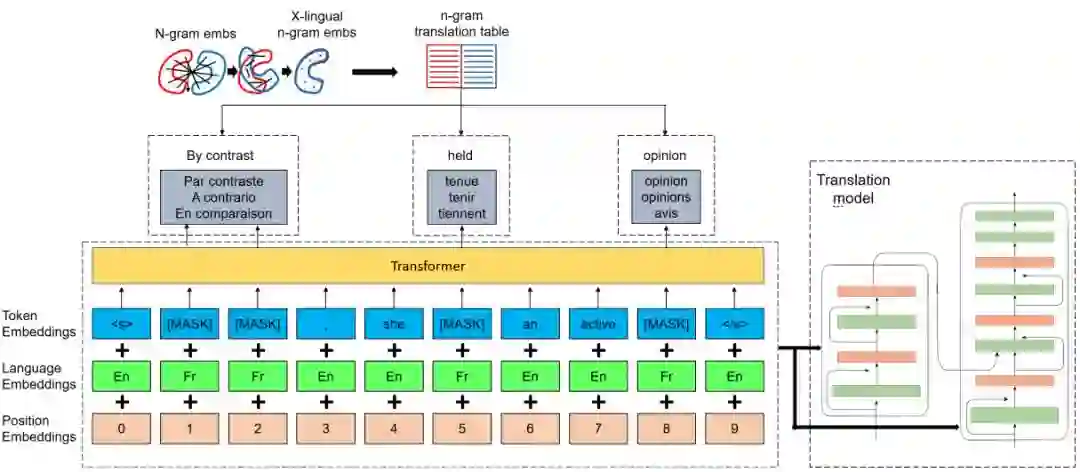
图1:方法概览
我们的方法共分为3步:
1. 由 n-gram 向量推断得到 n-gram 翻译表。
给定两种语言后,我们用这两种语言的单语语料通过 fasttext[3] 分别训练单语的 n-gram 向量,之后通过无监督跨语言词向量的方法(vecmap[4]),得到跨语言 n-gram 向量,并由两种语言 n-gram 向量的相似度推断得到两种语言 n-gram 之间的翻译表。两种语言 n-gram 之间的相似度通过以下公式得到:
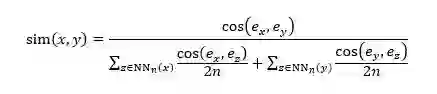
其中 x 和 y 分别是两种语言的 n-gram,e_x 和 e_y 分别是他们的跨语言 n-gram 向量。NN_n (x) 是 x 在向量空间的 n 近邻。
2. 在 n-gram 翻译表的辅助下,用我们提出的新的训练任务 CMLM 进行跨语言预训练。
输入某个语言的句子后,我们的 CMLM 较之 BERT[5] 和 XLM[1] 有两点改进:(1)我们随机 mask 掉 n-gram 的字符,而不是随机 mask 掉单个字符;(2)在模型的输出端,我们让其预测被 mask 的 n-gram 字符对应的几个翻译候选,而不是预测其本身,该翻译候选是通过第1步的翻译表得到的。这里有个问题是 n-gram BPE 字符的长度与其对应的翻译候选可能不一样。为了解决这个问题,我们借助 IBM Model 2[6] 的思想进行了改进。具体而言,CMLM 的损失函数定义为:
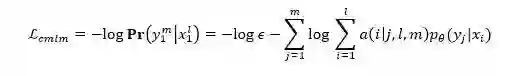
其中 x_1^l 表示长度为 l 的源语言 n-gram 字符,y_1^m 表示其对应的长度为 m 的目标语言 n-gram 翻译候选。a(i│j, l, m) 为 y_1^m 中第 j 个 BPE 字符是由 x_1^l 中第 i 个 BPE 字符翻译过来的概率,p_θ (y_j |x_i) 为 y_1^m 中第 j 个 BPE 字符与 x_1^l 中第 i 个 BPE 字符的翻译概率。让 L_cmlm 对 θ 求导,得到:
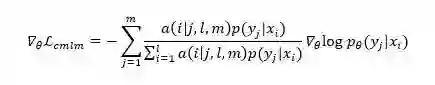
其中 p(y_j |x_i) 由模型的输出层得到,a(i│j,l,m) 我们定义为 sim(x_i,y_j),由两种语言的跨语言 BPE 向量计算相似度得到。
在训练时,我们交替使用提出的 CMLM 损失函数与 BERT 原始的 MLM 损失函数进行训练。
3. 用预训练的模型初始化翻译模型的编码器和解码器,进行无监督机器翻译模型的训练。
第2步之后,我们用得到的跨语言预训练模型分别作为翻译模型的编码器和解码器,然后随机初始化两者之间 attention 部分的参数。之后给定两种语言的单语语料,我们通过去噪自编码器(denosing autoencoder)和交替回译(iterative back-translation)进行无监督机器翻译模型的训练。
1. 主要结果
我们用截至2018年的 NewsCrawl 单语数据,分别进行了英语-法语(en-fr)、英语-德语(en-de)和英语-罗马尼亚语(en-ro)的实验。对于 en-fr,测试集是 newstest2014,对于 en-de 和 en-ro,测试集是 newstest2016。实验结果如表1所示(表中数据为 BLEU,XLM:Lample and Conneau, 2019):
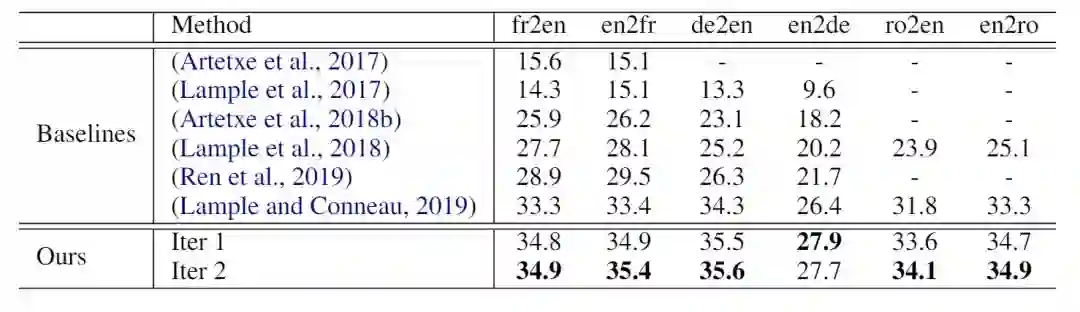
表1:无监督机器翻译实验结果
“Iter 2”代表在完成第一步迭代后,我们又用模型翻译一批单语数据得到伪双语语料,之后再用 GIZA 抽取了新的 n-gram 翻译表,将上面的过程再迭代了一次。表1的结果表明通过显示跨语言预训练,可以显著提升无监督机器翻译模型的性能。
2. 预训练模型的跨语言能力实验
除了无监督机器翻译之外,我们还进行了两项其他实验,用来说明我们的预训练模型有更强的跨语言建模能力。
(1)词对齐任务
我们选用 HLT/NAACL 2003 词对齐任务的 en-fr 数据集。给定两种语言的互译句对,该任务是要找到其中词与词的对应关系。在实验中我们略去了 OOV 词以及被 BPE 操作拆开的词。实验结果如下所示,表中 P 为准确率,R 为召回率,F 为 F score,AER 为对齐错误率,均为官方测试脚本运行得到。
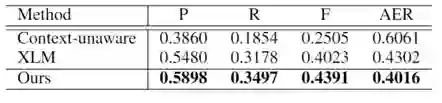
表2:词对齐任务实验结果
(2)跨语言分类
我们在预训练模型的第一个输出层后添加一个线性分类器,再用 XNLI 的 en 数据进行模型微调,之后进行 fr 和 de 的零样本分类实验。实验结果如下图所示:
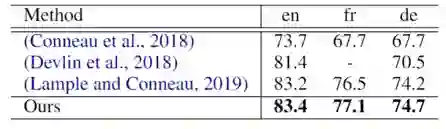
表3:跨语言分类实验结果
以上两个实验均表明用我们的方法训练得到的预训练模型较之 XLM,有更强的跨语言建模能力。
3. 对比试验(ablation study)
为了检验我们的方法各组成部分的作用,我们进行了如下的对比试验。实验结果取自第一轮迭代后的 en-fr 和 en-de 的实验结果。表中 CMLM 表示我们只用 CMLM 的损失函数进行预训练。“-translation prediction”表示我们预测 n-gram 字符本身而不是其翻译候选,“-- n-gram mask”表示在上一步的基础上,我们只是 mask 单个的 BPE 字符,而不是 mask n-gram,此时模型退化为 XLM。结果表明,每一部分对于最终的性能提升都有作用。
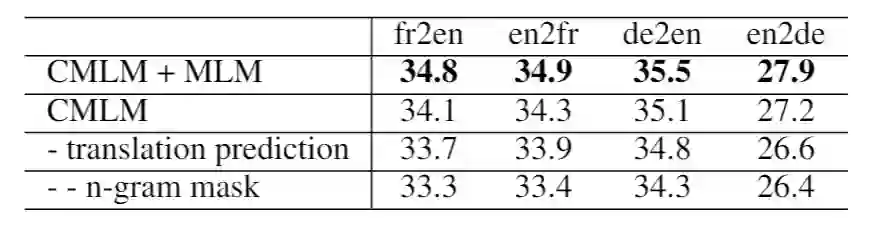
表4:对比实验结果
参考文献:
[1] Lample, Guillaume, and Alexis Conneau. "Cross-lingual language model pretraining." arXiv preprint arXiv:1901.07291 (2019).
[2] Sennrich, Rico, Barry Haddow, and Alexandra Birch. "Neural machine translation of rare words with subword units." arXiv preprint arXiv:1508.07909 (2015).
[3] Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. "Enriching word vectors with subword information." Transactions of the Association for Computational Linguistics 5 (2017): 135-146.
[4] Artetxe, Mikel, Gorka Labaka, and Eneko Agirre. "A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings." arXiv preprint arXiv:1805.06297 (2018).
[5] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[6] Brown, Peter F., Vincent J. Della Pietra, Stephen A. Della Pietra, and Robert L. Mercer. "The mathematics of statistical machine translation: Parameter estimation." Computational linguistics 19, no. 2 (1993): 263-311.
你也许还想看:







