阅读理解先导篇

笔者最近开始接触阅读理解,因此做了一些调研,整理了目前公开的中文阅读理解数据集以及阅读理解处理的整体框架内容,在此与大家分享。由于阅读理解大家族过于庞大,本文仅关注基于文档的抽取式问答。
本文的主要内容为:
公开中文阅读理解数据集
阅读理解解决方案
Question预处理
文档段落检索
答案抽取
一、公开的阅读理解数据集
笔者整理了目前公开的中文阅读理解数据集,并附上了下载地址。每个数据集可能有着不同的阅读理解任务,大家按需自取。
NLPCC2016与2017
https://github.com/Erutan-pku/LCN-for-Chinese-QA
WebQA
https://spaces.ac.cn/archives/4338
Dureader
https://github.com/baidu/DuReader
Dureader_robust
https://github.com/PaddlePaddle/Research/tree/master/NLP/DuReader-Robust-BASELINE
DRCD
https://github.com/DRCKnowledgeTeam/DRCD
CRMC
2017
2018
2019
CJRC2019
http://cogskl.iflytek.com/2019/11/25/ccl-2019-%E4%B8%AD%E6%96%87%E6%B3%95%E5%BE%8B%E9%98%85%E8%AF%BB%E7%90%86%E8%A7%A3%E6%95%B0%E6%8D%AE%E9%9B%86cjrc/
C3
https://dataset.org/c3/
RECo
https://github.com/benywon/ReCO
https://github.com/ymcui/cmrc2017
https://worksheets.codalab.org/worksheets/0x92a80d2fab4b4f79a2b4064f7ddca9ce
https://hfl-rc.github.io/cmrc2019/
二、阅读理解解决方案
如下图所示是一个完整的阅读理解工程的整体架构[1],主要分为三部分:question预处理,文档段落检索,答案抽取。本节内容会针对这三方面展开,希望帮助大家对整个阅读理解解决方案有个大概的了解。
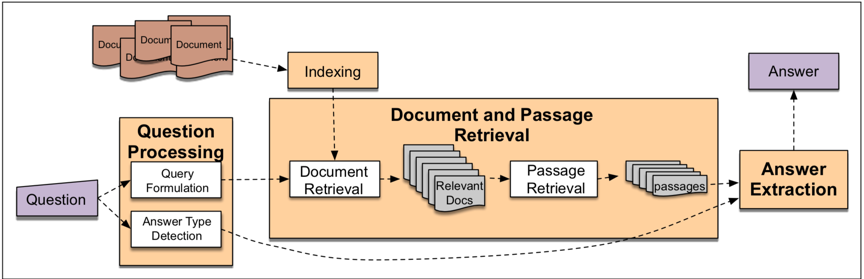
阅读理解工程整体架构
1. Question预处理
为了提高文档段落检索的有效性,我们往往需要对question做些预处理。预处理包括:
加形态学变体,这个主要面对英文单词,例如将进行时态的单词还原;
加同义词,以便提高检索的召回率;
设计规则将问题变成陈述句,例如:“青花瓷”是哪一年发行的,改成:青花瓷发行于**年。该做法是因为陈述句往往与原文的相似度更高;
分词,分词方法的选用需要同时考虑分词的正确性和分词粒度。
停用词处理
词项规范化处理:包括日期,度量单位等的格式规范化,词干还原(高高兴兴—>高兴)等
除了对问题做预处理,问题对应的答案实体类型也能给予我们很多信息。问题的实体答案类型可能是人名,地名,时间等等。具体的答案类型可以借助WordNet等进行自动化构建,或者直接手动构建。在构建好答案实体类别后,可以采用简单的基于规则的方法或者监督学习算法对答案实体类型进行分类。通常而言,question中会有一两个词语标志着答案的实体类型,这个词就相对而言比较重要,在一些方法中,该词可作为特征辅助文档问答。
2. 文档段落检索
文档段落检索部分的目标是从大量文档中抽取与问题相关的部分段落,以便缩小答案抽取的范围,提高文档问答的速度。目前使用的检索方法主要有:
倒排索引等信息检索方法。目前广泛使用的检索工具有Lucene, ElasticSearch, Solr等。
高维向量检索:事先将文档/段落编码成高维向量,然后对当前问题进行编码,再从文档段落向量中检索与当前问题向量最相似的文档/段落。在编码阶段,我们可以使用简单便捷的TF-IDF方法,或者使用准确率高但较为复杂的基于BERT的编码。在快速检索阶段,常用的方法有:空间切分类算法(例如KD树,局部敏感哈希算法等),基于有向图的检索等。基于有向图的检索首先会用K近邻图,k近邻图剪枝等构建一个有向图,然后用启发式搜索算法进行相似向量检索。启发式搜索的核心思想在于邻居的邻居很有可能是邻居。
传统监督学习算法:判断当前问题与各个文档是否相似。传统监督学习算法可使用的特征有:文档/段落中出现指定类型命名实体(此处的指定类型命名实体就是上文所说的问题对应的答案实体类型)的次数,问题关键词在段落中出现的次数,最长匹配序列长度,段落所属的文档的倒排索引排名,段落和问题的n-gram overlap等等。
基于BERT的检索:随着BERT预训练模型的兴起,目前已有一些文档检索场景下的BERT改进模型,例如DC-BERT[2]等。
3. 答案抽取
答案抽取主要使用端到端的神经网络模型,最典型的是基于BiLSTM和BERT两种,模型输入是question和段落,输出是段落中每个token是答案起始/结束的概率。
3.1 基于BiLSTM
基于BiLSTM的答案抽取算法的代表模型是DrQA[3]。如下图所示是DrQA模型的整体架构。Passage embdedding由四部分组成:
Word embedding
Token features:例如词性,命名实体标签等;
Exact match:词语是否有在question中出现过,标签为0/1
Aligned question embedding:加入与question的attention
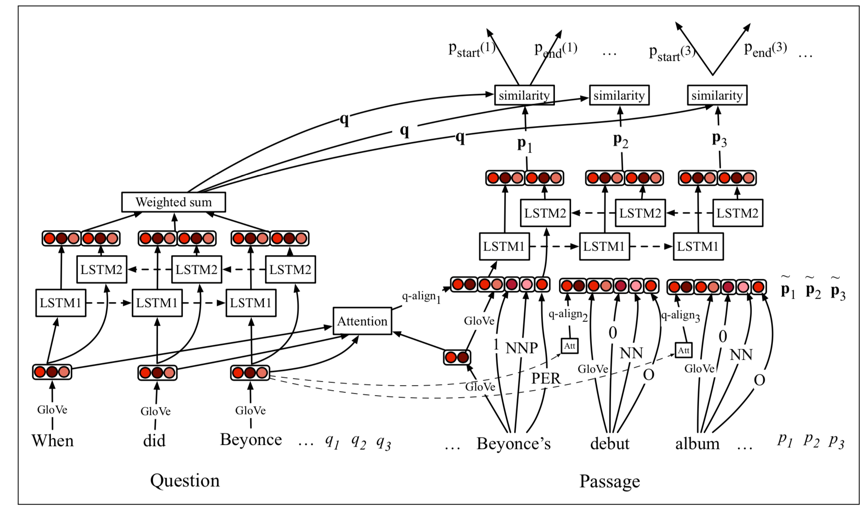
基于BiLSTM的阅读理解模型
3.2 基于BERT
由于预训练模型在自然语言处理任务上的卓越性能,BERT等预训练模型成为阅读理解研究者们的心头好。如下图所示是使用BERT模型做阅读理解任务的示意图[4]。
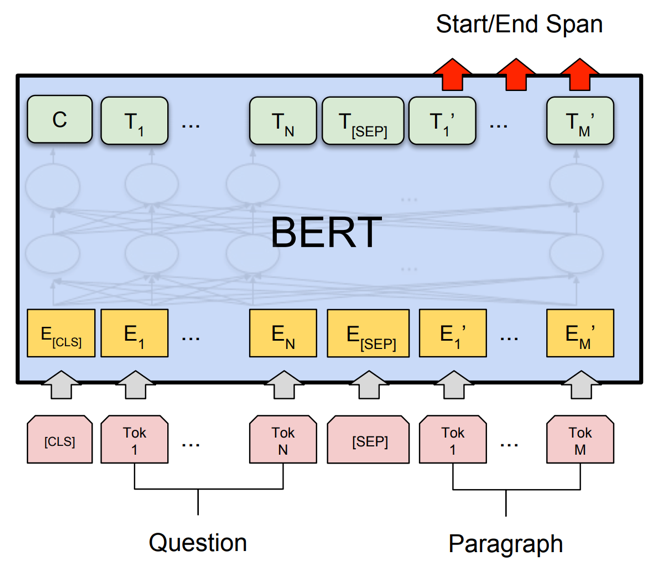
基于BERT的阅读理解模型
基于BERT的阅读理解模型的输入为:[CLS] + 问题 + [SEP] + 文档段落 + [SEP]。输出为段落中的每个token属于 答案start/end 的概率(如果是no answer,则「CLS」有着最大的start/end概率)
滑窗切割:由于BERT模型有着输入序列长度的限制,而文档往往比较长,因此必须对文档进行切割。在切割方式的选择上,一般使用滑窗切割的方式:以64/128为步长,滑窗地切割512长度的片段。
由于进行了滑窗切割,那么一个token会出现在多个切割片段里因此获得多个start/end概率,面对该问题,inference时怎么选出最终的答案?一种较为常用的做法是:找出概率最高的k个开始位置和结束位置,将这些开始和结束位置两两组合,留下符合要求(结束位置在开始位置的后面,答案长度不超过30等)的区间,再根据联合概率(起始和结束概率之和/积)选出最终区间作为答案。
当然,以上的做法只是一般的常用做法,面对具体数据集时,如果大家能够针对具体数据作出不一样的选择,也许些微的改变就能带来不少的提升。
三、小结
本文主要列出了一些公开的中文阅读理解数据集,以及简要介绍了阅读理解整体的解决方案,希望为想入门阅读理解的你提供一臂之力。
另外,我们后续也会继续分享阅读理解方面的优秀模型,希望大家持续关注~
参考文献

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





