知识图谱最新论文合辑:从 NeurIPS 2018 到 AAAI 2019

精选 5 篇来自 AAAI 2019、NeurIPS 2018、ISWC 2018 和 ESWC 2018 的知识图谱相关工作,带你快速了解知识图谱领域最新研究进展。
本期内容选编自微信公众号「开放知识图谱」。


■ 论文解读 | 康矫健,浙江大学硕士生,研究方向为知识图谱
摘要
近来,针对事件抽取的工作大都集中在预测事件的 triggers 和 arguments roles,而把实体识别当作是已经由专家标注好了的,然而实际情况是实体识别通常是由现有工具包预测出来的,而这将会导致实体类型预测产生的错误传播到后续任务中而无法被纠正。
因而,本文提出一种基于共享的 feature representation,从而预测实体类型,triggers,argumentsroles 的联合模型。实验表明我们的方法做到了 state-of-the-art。
模型介绍
概览
如图 1 所示,该模型由三个核心部分组成,分别是实体类型预测(Entity MentionDetection - EMD)、事件类型预测(Event Detection - ED)和语义角色类型预测(Argument RolePrediction - ARP)。
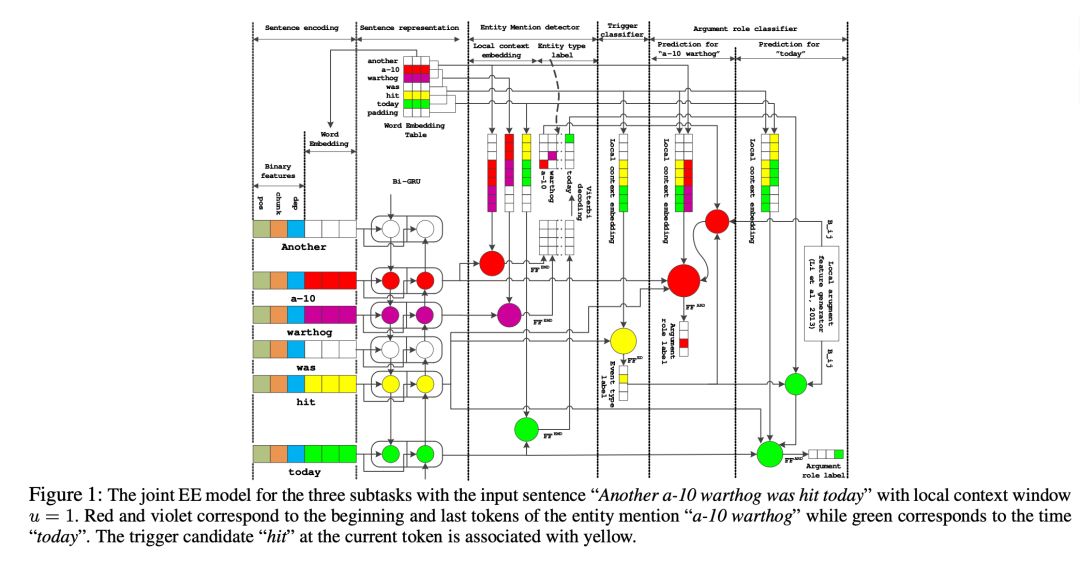
Sentence Encoding
句子中的每个词向量表示由两部分组成。一部分是由 word2vec 预先训练好的词向量;第二部分是 binary vectors,由 POS,chunk 以及 dependency 信息组成。之后将这两部分拼接在一起。
Sentence Representation
将 Sentence Encoding 中得到的词向量输入到 bi-GRU 中得到每个词的隐藏层表示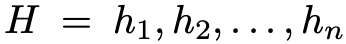
已经有实验表明 bi-GRU 可以 encode 非常丰富的上下文信息,这对事件抽取这个任务非常有效。之后,这个表示将作为 EMD、ED 以及 ARP 任务预测实体类型,trigger 类型和语义角色类型的 shared representation。
我们的目标就是最大化三个预测任务的联合概率:
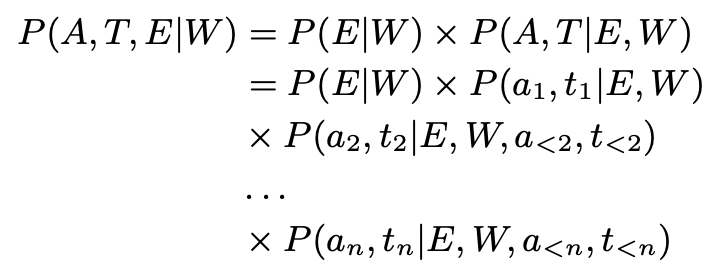
Entity Mention Detector
可以将实体类型检测的目标函数展开如下:
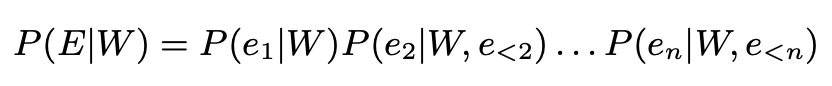
我们的目标是最大化这个概率,其中:
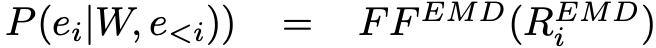
其中:
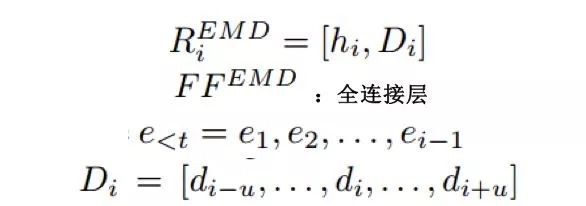
Trigger and Argument Prediction
可以将事件类型的检测和语义角色类型的预测展开成如下目标函数,我们的目标是最大化这个目标函数:
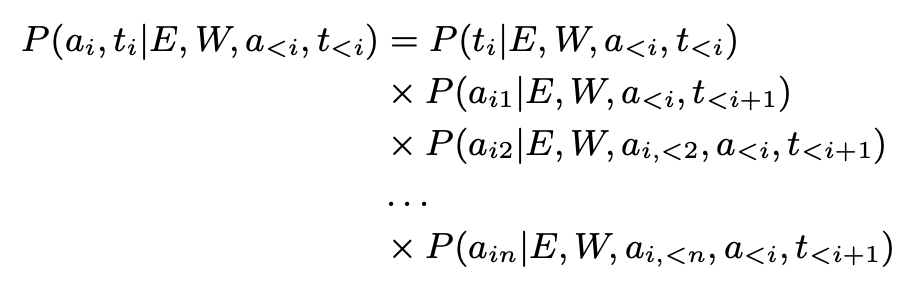
其中:
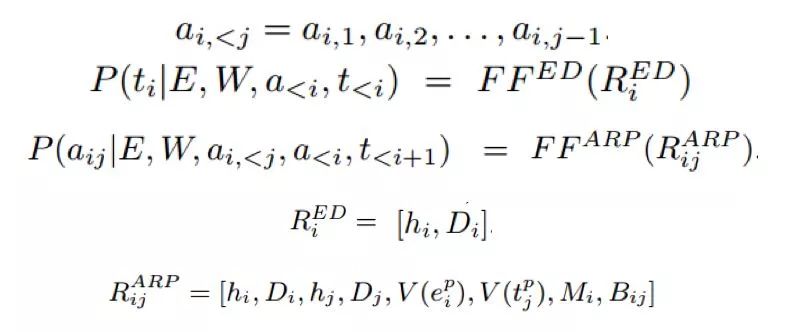
其中:

实验分析
Trigger和语义角色预测实验效果
可以看到,本文提出的联合训练模型在 event trigger identification、event trigger classification、event argument identification、event argument classification 上的 F1 值都达到了当前最优效果,具体结果如下:
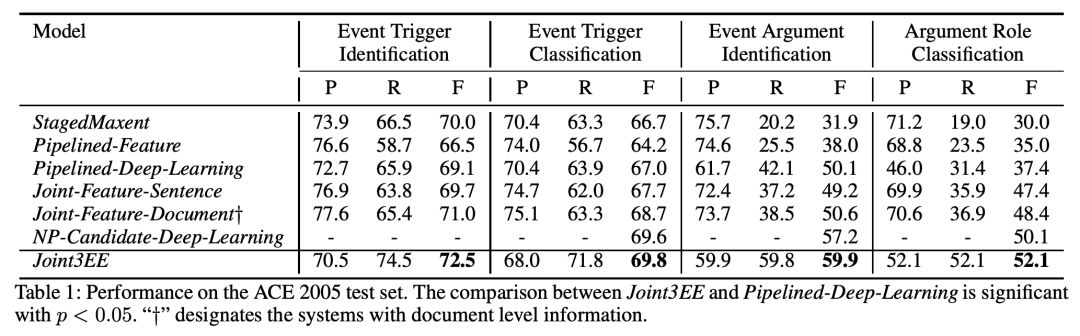
实体类型预测的结果
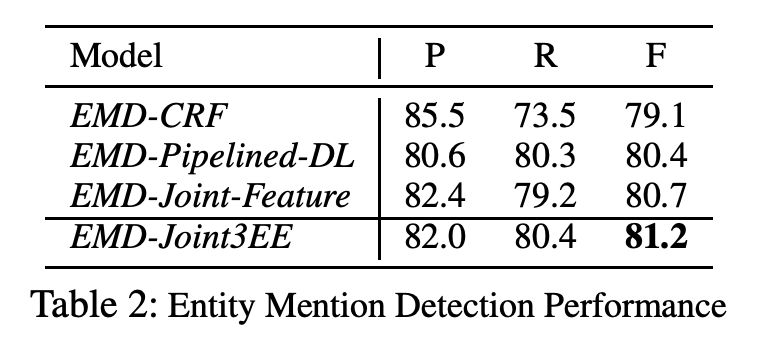
试验结果表明,本文提出的模型在实体类型检测上的 F1 值同样达到了最优,具体结果如下:
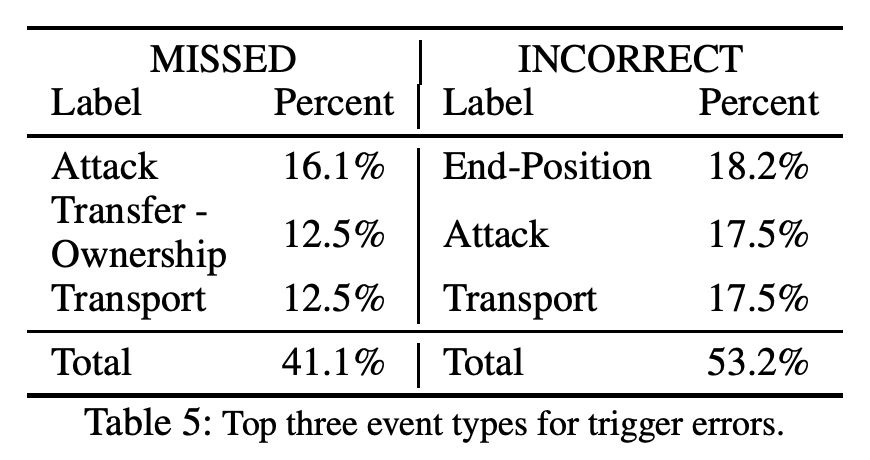
Error Analysis
可以看到 trigger classification(69.8%)和 trigger identification(72.5%)的效果相差不多,可见主要的错误来源于未能准确判断一个词属于 trigger word。
而通过对未能检测出来的 trigger word 的研究发现主要是由于在训练数据集上未出现过这个词,比如:
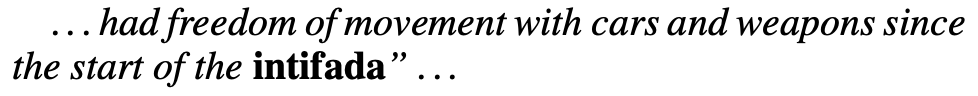
通过对检测出来是 trigger word 而未能正确预测其类型的词的研究发现,主要错误来源于该词附近出现了有误导性的上下文信息,而我们的模型不能很好地判别,比如,下面这句话的 fire 可能会由于 car 的出现而被错误判断未 Attack 的事件类型,这启发我们去研究一个更好的能够 encode 上下文的模型:



■ 论文解读 | 张清恒,南京大学硕士生,研究方向为知识图谱
摘要
近来,针对跨知识图谱(KGs)的实体对齐任务,研究者提出并改进了多种基于 embedding 的模型。这些模型充分利用实体与实体之间的关系以得到实体之间的语义相似度,换言之,这些模型更关注于关系三元组(relationship triple)。
本文发现 KG 中存在着大量的属性三元组(attribute triple),本文提出的模型利用属性三元组生成 attribute character embeddings,使其帮助不同 KG 中的实体映射到同一空间中。与此同时,模型还使用传递规则进一步丰富三元组。
实验结果表明,相比于现有方法,本文提出的模型在实体对齐任务上取得了较大的提升。
模型介绍
概览
如图 1 所示,该模型由三个核心部分组成,分别是谓词对齐(predicate alignment)、嵌入学习(embedding learning)和实体对齐(entity alignment)。
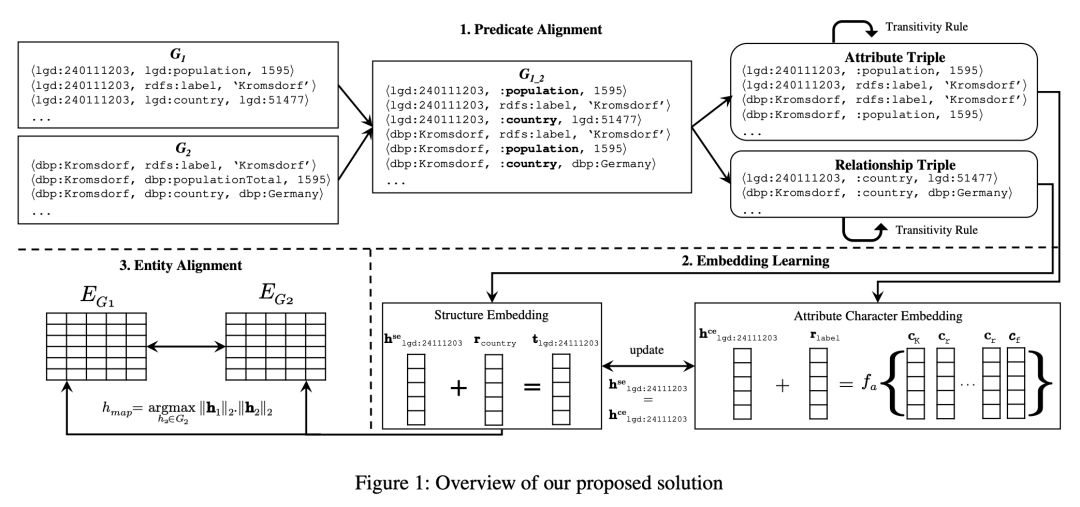
Predicate Alignment
该模块通过重命名潜在对齐的谓词将两个 KG 合并成一个 KG。通过计算谓词的名称(URI 的最后一部分)相似度,发现潜在对齐的谓词对,然后使用统一的命名格式将其重命名。例如,将对其的谓词对,“dbp:bornIn”和“yago:wasBornIn”重命名成“:bornIn”。
Embedding Learning
Structure Embedding
Structure embedding 模块采用 TransE 实现,与 TransE 不同的是,模型希望更关注已对齐的三元组,也就是包含对齐谓词的三元组。模型通过添加权重来实现这一目的。Structure embedding 的目标函数如下:
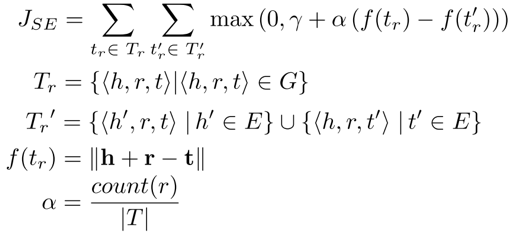
其中,count(r) 是包含的三元组的数量,表示合并之后的三元组集合。
Attribute Character Embedding
与 structure embedding 一样,attribute character embedding 也借鉴了 TransE 的思想,把谓词作为头实体与属性值之间的转换媒介。但与 structure embedding 不同的是,对于相同含义的属性值,在不同的 KG 中表现形式存在差别。
因此,本文提出了三种属性值组合函数。在组合函数编码属性值之后,模型希望属性三元组满足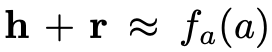
是组合函数,表示属性值的字符串
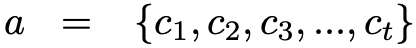
1. Sum compositional function (SUM)
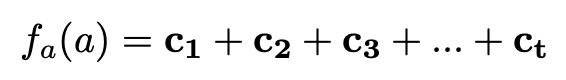
2. LSTM-based compositional function (LSTM)
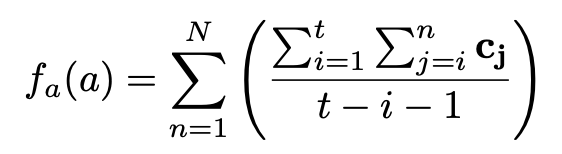
3. N-gram-based compositional function (N-gram)
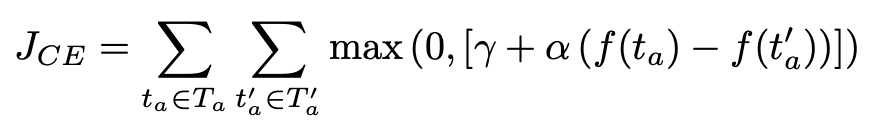
Joint Learning of Structure Embedding and Attribute Character Embedding
本文提出的模型旨在使用 attribute character embedding 帮助 structure embedding
在同一向量空间中完成训练,联合训练的目标函数如下:
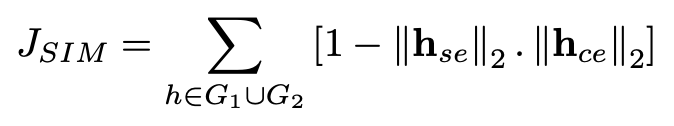
本文提出的模型的整体目标函数如下:
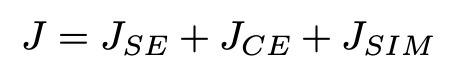
Entity Alignment
在经过上述训练过程之后,来自不同 KG 的相似的实体将会有相似的向量表示,因此可通过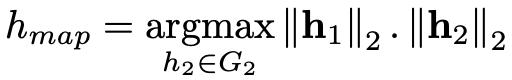
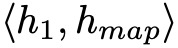
Triple Enrichment via Transitivity Rule
本文发现利用传递关系可以丰富三元组,从而提升实体对齐效果。给定三元组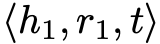
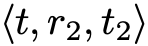
作为头实体 h1 和 h2 尾实体的关系,使其满足
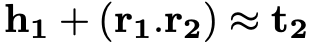
实验分析
数据集
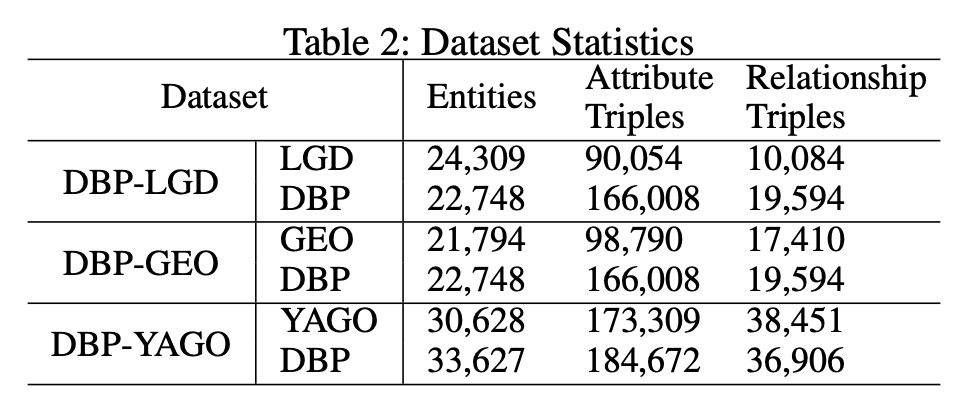
本文从 DBpedia (DBP)、LinkedGeoData (LGD)、Geonames (GEO) 和 YAGO 四个 KG 中抽取构建了三个数据集,分别是 DBP-LGD、DBP-GEO 和 DBP-YAGO。具体的数据统计如下:
实体对齐结果
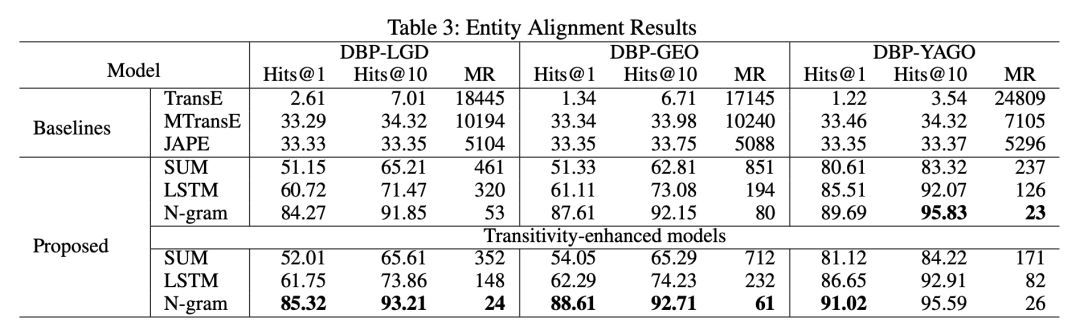
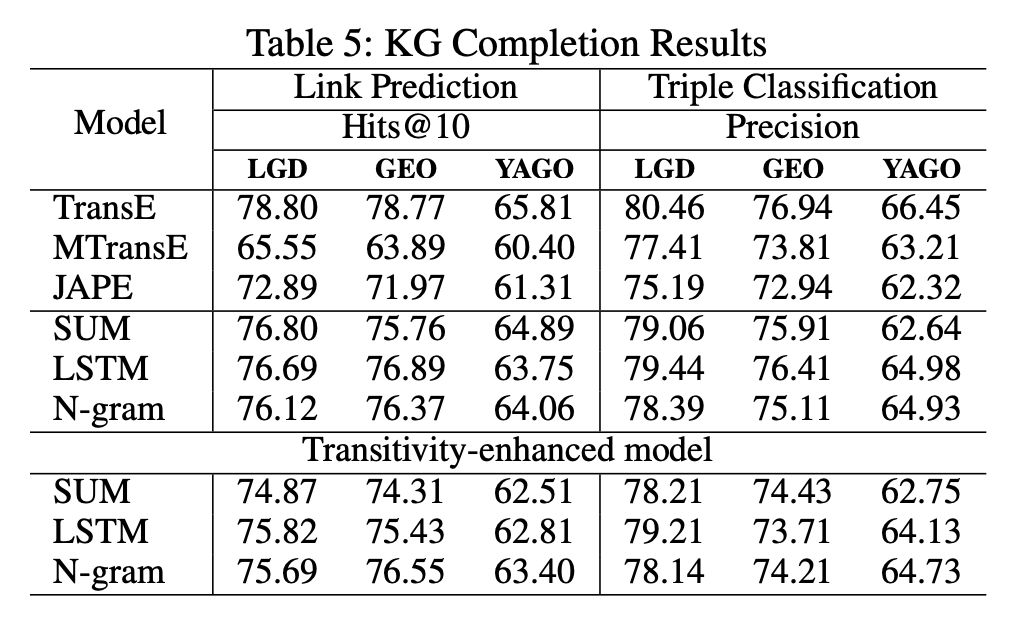
本文对比了三个相关的模型,分别是 TransE、MTransE 和 JAPE。试验结果表明,本文提出的模型在实体对齐任务上取得了全面的较大的提升,在三种组合函数中,N-gram 函数的优势较为明显。此外,基于传递规则的三元组丰富模型对结果也有一定的提升。具体结果如下:
基于规则的实体对齐结果
为了进一步衡量 attribute character embedding 捕获实体间相似信息的能力,本文设计了基于规则的实体对齐模型。
本实验对比了三种不同的模型:以 label 的字符串相似度作为基础模型;针对数据集特点,在基础模型的基础之上增加了坐标属性,以此作为第二个模型;第三个模型是把本文提出的模型作为附加模型,与基础模型相结合。具体结果如下:

KG补全结果
本文还在 KG 补全任务上验证了模型的有效性。模型主要测试了链接预测和三元组分类两个标准任务,在这两个任务中,模型也取得了不错的效果。具体结果如下:


■ 论文解读 | 黄佳程,南京大学硕士生,研究方向为知识图谱、实体消解
论文动机
张量分解方法被证明是一种有效的用于知识图谱补全的统计关系学习方法。最早提出的张量分解方法为 CP 分解(Canonical Polyadicdocomposition),这种方法为每个实体学习出一个头实体嵌入和一个尾实体嵌入,而头尾嵌入是独立的。这导致了该方法在补全上性能较差。SimplE 基于 CP 方法提出了一种张量分解方法,解决其训练中头尾无关的问题。
亮点
SimplE 的亮点主要包括:
1. SimplE 可以被看成一种双线性模型,与其他模型相比,它具有完全表达能力,同时冗余参数少;
2. SimplE 可以通过参数共享的方式将背景知识编码进嵌入中。
概念及模型
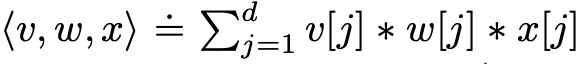
其中 v,w,x 为 3 个 d 维向量,v[j], w[j], x[j] 分别表示向量 v,w,x 的第 j 个分量。
图谱中的关系类型(ζ 表示正例,ζ’ 表示反例):
1. 自反性
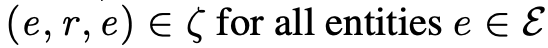
2. 对称性
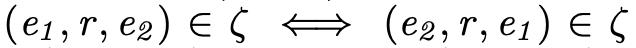
3. 反对称性
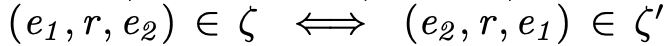
4. 传递性
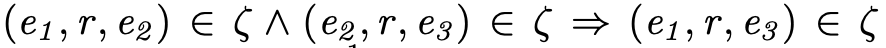
SimplE模型
a) 实体和关系的表示:每个实体 e 具有两个嵌入 h_e 和 t_e,分别表示其在头实体和尾实体中的表示,每个关系有两个表示;
b) 三元组 (e_i,r,e_j) 的打分函数:
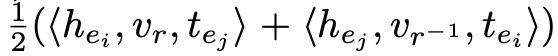
该打分函数可以看成 (e_i,r,e_j) 和 (e_j,r^-1,e_j) 的 CP 打分的平均值。
c) 在实验中,SimplE-ignr 的打分函数仅为第一项 CP 打分,作为一种对比方法。
SimplE 模型的学习过程:训练中使用随机梯度下降,返利生成方法和 TransE 相同。优化目标为带 L2 正则化的负对数似然函数:
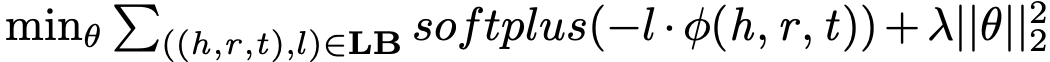
SimplE 利用背景知识的方法:
a) 对于自反的关系 r 和,可以通过绑定
和
两个参数;
b) 对于反对称关系,可以将绑定成-v_r;
c) 对于关系 r1,r2 使得 (e_i,r_1,e_j) 和 (e_j,r_2,e_i) 总是同时成立,可以绑定两个关系的和
两个参数。
理论分析
SimplE 模型的完全表达能力:当嵌入维数充分大时,SimplE 能够完全表示 ground truth。

FSTransE 嵌入模型中:1)自反关系总是对称的;2)自反关系总是传递的;3)e1 和 Δ 的所有实体具有关系 r,e_2 和 Δ 中的一个实体具有关系 r,则 e2 和 Δ 中的所有实体具有关系 r。其他变体 TransE,FTransE,STransE,TransH 等也有同样的缺陷。
DistMult,ComplEx,CP 和 SimplE 都可以看作双线性模型(需要把 SimplE 的头尾表示拼接作为一个实体的单一嵌入),这时他们关系表示的参数如下图:
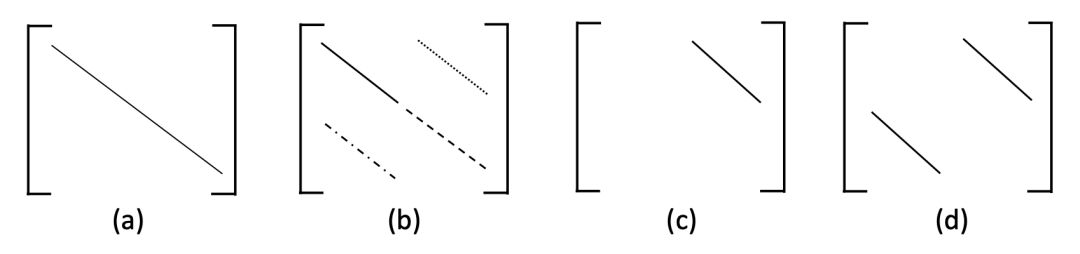
ComplEx 的参数规模为 SimplE 的 2 倍,并且存在冗余。
实验
实验结果
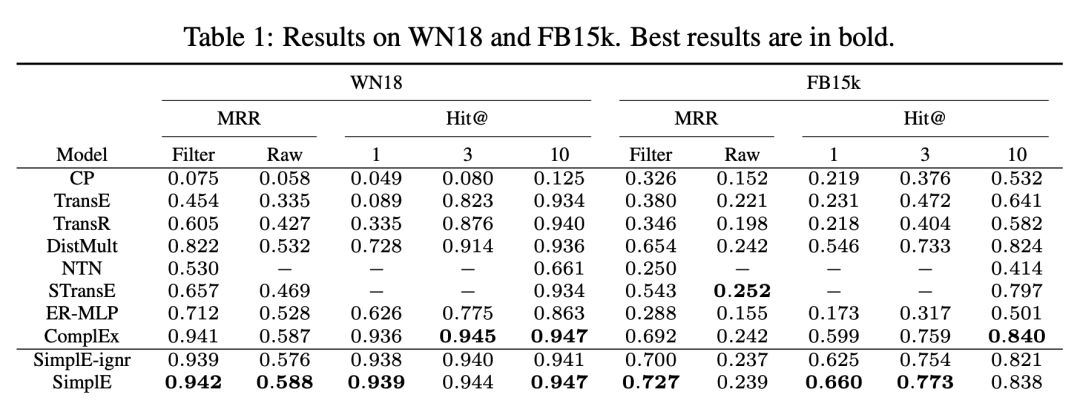
作者与 WN18 和 FB15K 在两个基准数据集上进行了比较,结果显示了 SimplE 都取得了较好的效果。
总结
本文提出了一种简单可解释且具有完全表达能力的双线性模型用于知识图谱补全。文章证明了 SimplE 模型在实验中性能良好,并且具有编码先验知识的能力。


■ 解读 | 张文,浙江大学博士生,研究方向为知识图谱的表示学习、推理和可解释
本文是我们于苏黎世大学合作的关注与知识图谱和文本对齐的论文,发表于 ISWC 2018。
文本和知识图谱都包含了丰富的信息, 其中知识图谱用结构化的三元组表示信息,文本用自由文本形式表示信息,信息表示的差异给知识图谱和文本融合对齐造成了困难,本文关注于如何将知识图谱于文本进行对齐,并提出了基于正则的多任务学习的对齐模型 KADE。
文本选择了将知识图谱的实体和描述实体的文本进行对齐,首先将文本和知识图谱都通过表示学习映射到向量空间,学习到文本和实体的向量表示,在学习过程中加入正则约束使表示同一实体的实体向量和描述文本在向量空间中尽可能接近,知识图谱和文本的表示学习模型交替进行训练,从而在不影响文本和知识图谱各自的表示学习效果的情况下实现对齐。
KADE 的核心想法如下:
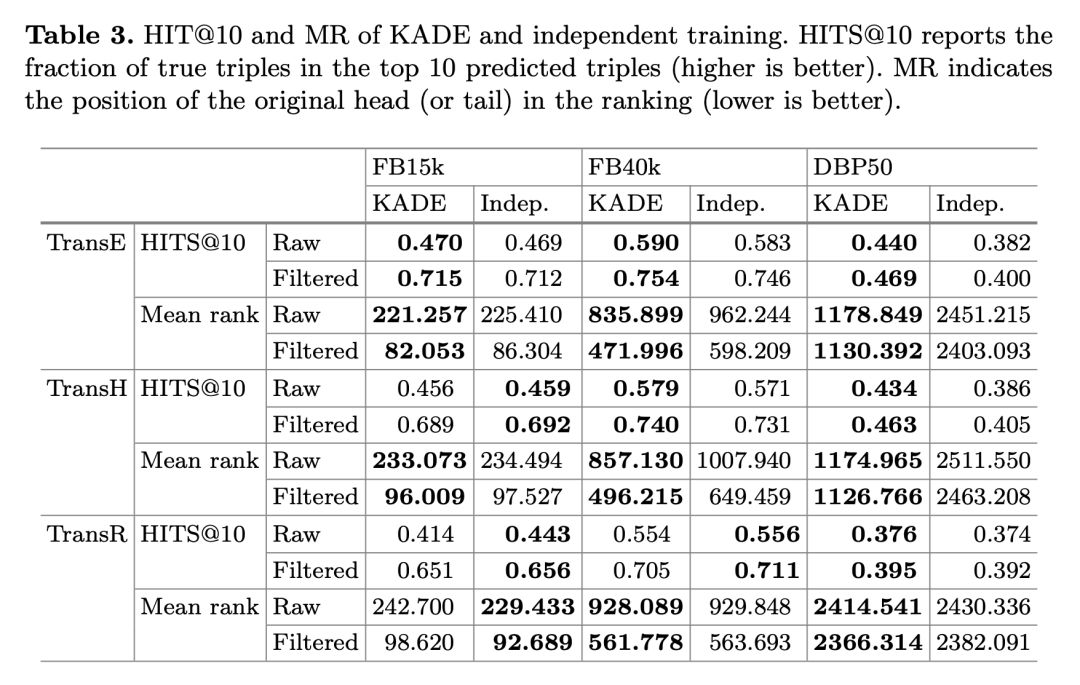
本文的实验主要采用了三个数据集,FB15k,FB40K 和 DBP50。实验中知识图谱表示学习采用了 TransE,TransH 和 TransD,并在链接预测任务上进行了测试,实验结果如下并表明了 KADE 对知识图谱表示学习模型本身的效果没有影响且稍有提升。
实验中文本表示学习模型采用了 PV-DM,并在文本分类任务上进行了测试,实验结果如下并标明了 KADE 对文本表示学习模型的效果没有影响且有明显提升。
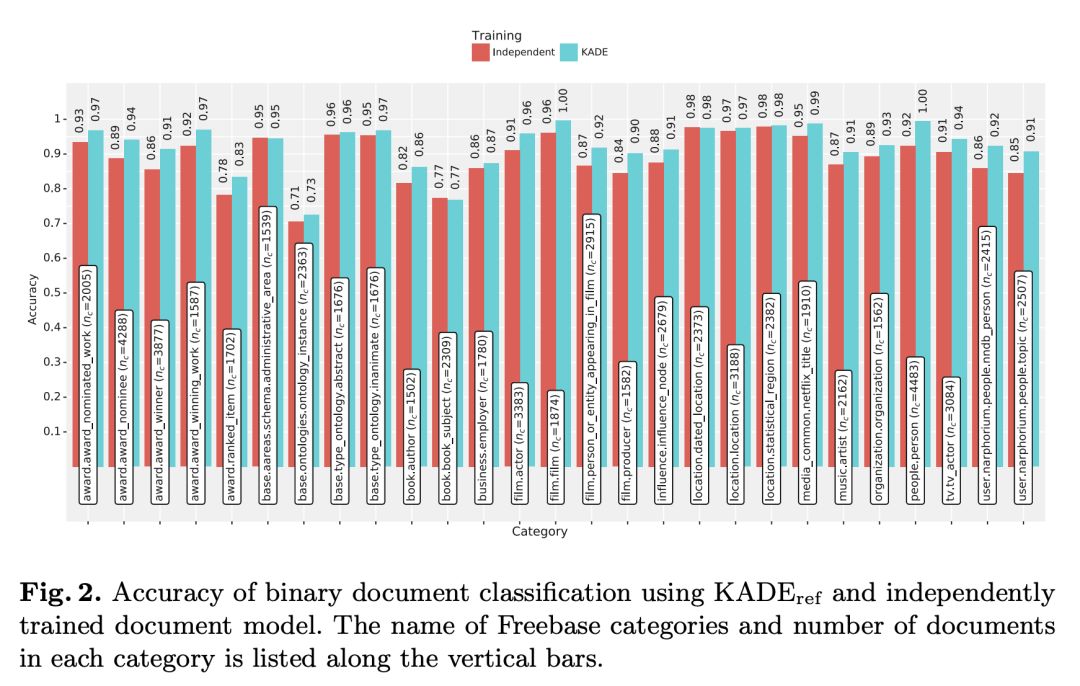
本文还验证了 KADE 的对齐效果,提出了一个评价对齐效果的指标 normalizedalignment score, 这是一个介于 0 到 1 之间的值且值越大说明对齐效果越好。
我们构造了一个对齐的 baseline 通过非线性函数实现文本表示学习向量空间和知识图谱表示学习向量空间的互相转换,实验结果如下:
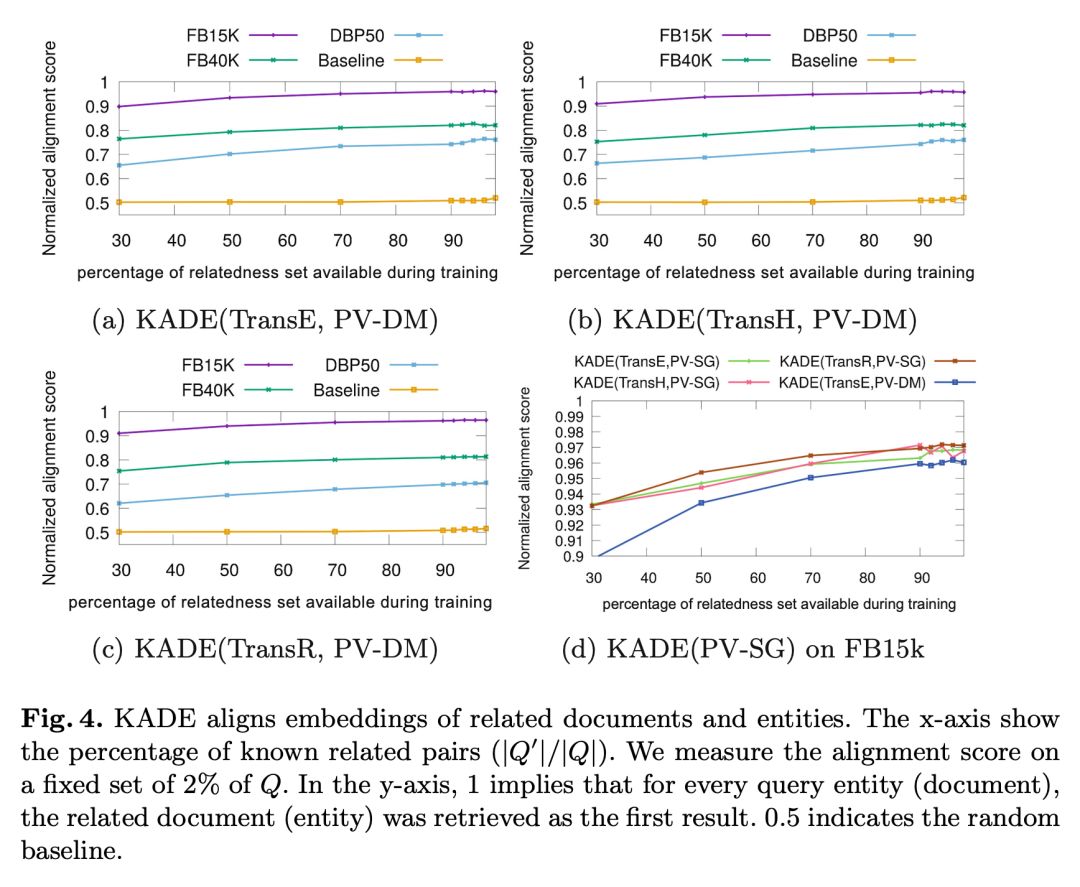
从上图的实验结果能够看出,简单了非线性空间映射几乎无法完成对齐任务,同时 KADE 实现了知识图谱实体和实体描述文本的对齐。


■ 论文解读 | 刘晓臻,东南大学本科生,研究方向为知识图谱
论文动机
QA 任务通常被划分为命名实体消歧(Named EntityDisambiguation, NED),关系提取(Relation Extraction, RE),以及查询生成(Query Generation,QG)几个子任务。但这种划分很少能够真正实现 QA 系统构造的模块化,这导致研究人员群体无法成功有效地将自己的研究建立在本领域之前的成果上。
虽然的确有诸如 OKBQA 的模块化框架的存在,但 OKBQA 对查询生成关注的太少,其 24 个可重复利用的 QA 组件中只有一个是查询生成器。而且,不断增加的问题复杂程度给查询生成任务带来了几个难点:
处理大规模的知识库;
识别问题类型,诸如布尔型;
处理有噪声的标注;
对一些需要特殊查询特性的复杂问题的支持,诸如聚集、排序和比较等;
输入问题存在句法上的不明确性,如语序可以颠倒等。
因此,针对以上的问题及难点,本文提出了 SPARQL 查询生成器(SPARQL Query Generator, SQG),一个能够超越现有最高水平的,用于 QA 任务工作流的模块化查询构造器。
SQG 使用基于树形 LSTM(Tree-LSTM)相似度的候选查询排名机制,能够处理含噪声的输入,且在基于 DBpedia 的大型 Q/A 数据集上经过评估。
贡献
文章的贡献有:
1. 给出了 KBQA 任务中 QG 任务的模块化、与其他子任务分开的正式定义。
2. 指出了影响 QG 任务性能的因素,并针对这些现有难点,提出了 SQG 这一模块化的、性能优良的查询生成器,并引入排名机制增强答案的准确度。
方法
任务定义及理论基础
定义查询生成如下:给出问题字符串s和一个知识图谱 K=(E,R,T),其中 E 为实体集合,R 为关系标签集合,为有序三元组集合。
在 QA 工作流的之前阶段已执行实体和关系的链接,即已给出一个从 s 的子串(话语串)到知识图谱中的 E 和 R 各自映射的集合 M。查询生成这一任务即用 s, D 和 M 来生成一个 SPARQL 查询(文中并未对 D 做出明确解释)。
由于 NED 和 RE 模块会为问题中的每一个话语串列出一些候选注释,因此这一注释任务在此就不那么重要。基于查询生成的定义,可以定义高级查询生成任务:条件是每一个子串 s 都已映射到 E 和 R 各自的一个非空子集上,即实体和关系都有一些候选注释。
例如,如图 1 所示,实体“artists”有多个候选注释,诸如“dbo:Artist”,“dbo:artists”等。本文的实验表明考虑多个候选注释而不是只选择得分最高的注释会提升表现。
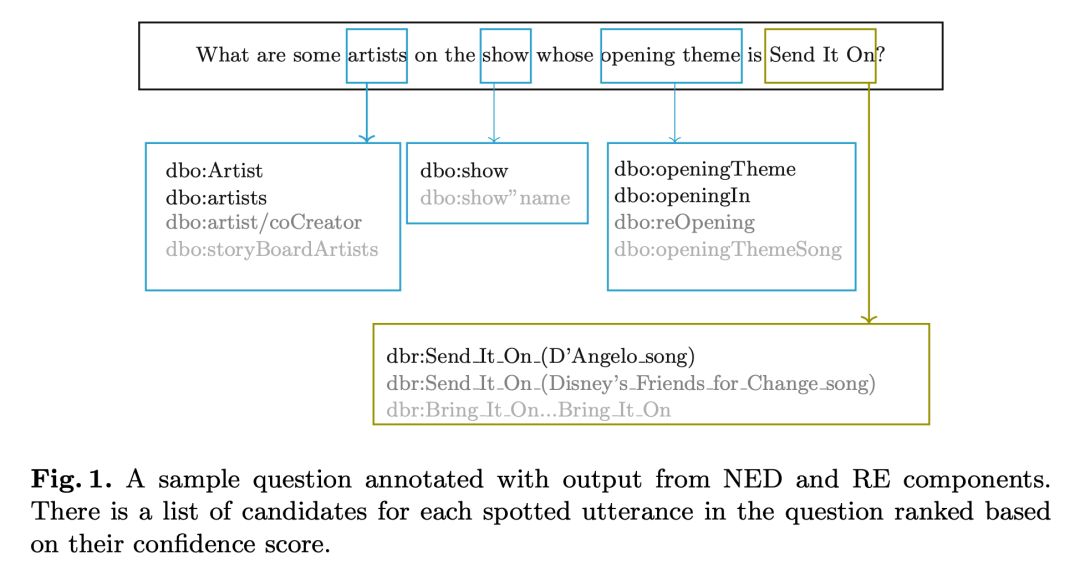
图 1 为一个经过 NED 和 RE 组件输出注释后的简单问题。对于问句中每个已识别的话语串,根据可行度得分排名列出一些候选注释。
本文猜想一个问题的形式化理解为知识图谱中的一个路径(walk)w,其只含有输入问题 s 的目标实体 E 和关系 R,以及答案节点。其中,知识图谱 K=(E,R,T) 中的一个路径定义为一串边和这些边连接的节点:W=(e0,r0,e1,r1,e2,…,ek-1,rk-1,ek),且对于 0≤i≤k-1,(ei,ri,ei+1)∈T。
就一个实体集合 E’ 和关系集合 R’ 而言,当且仅当一个路径 W 包含 E’ 和 R’ 中的所有元素时,此路径为有效路径,即 ∀e∈E’ : e∈W 且 ∀e∈R’ : e∈W。若一个节点 e∈W,但 e ∉ E’,此节点即为未连接的,未连接节点用来连接一个路径中其他的节点。
获取有效路径有两步:第一步,先确定问题的类型(例如为布尔型或计数型),根据类型来从知识图谱中抽取一些有效路径,但因为这些路径可能会无法正确获取问题背后的意图,大部分路径可能都是输入问题的错误映射。这时就需要第二步,根据候选路径和输入问题的相似度来对候选路径排名。
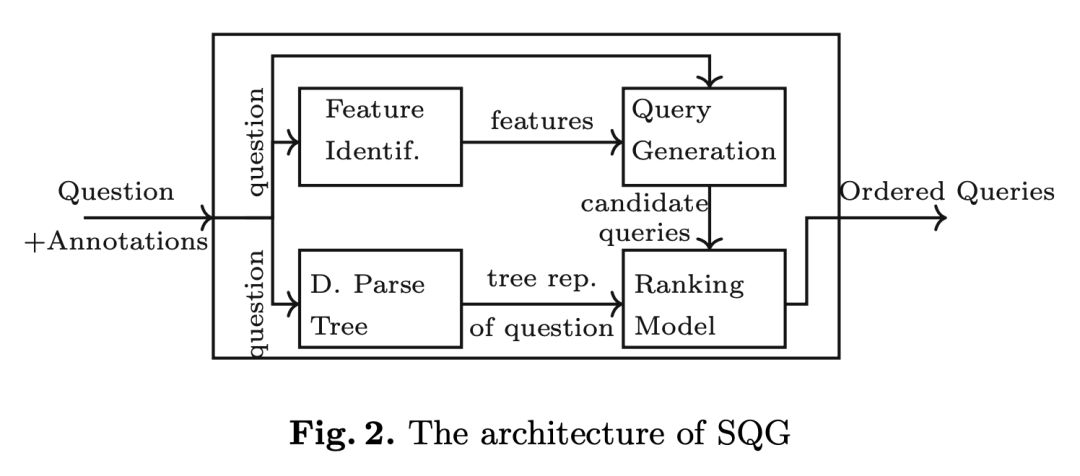
SQG 的大体框架如下图 2。
查询生成
将任务限制在含有所有链接实体和关系的子图中,在其中列举出候选路径并直接映射到 SPARQL 查询中。另外还需要识别问题类型才能从有效路径中创建结构正确的候选查询。
获取子图:从一个充满链接实体 E 作为节点的空子图开始,增加与在知识图谱中存在的链接关系 R 相对应的边,如图 3 中实线所示。
在这一步中,一个关系可能连接两个子图中已有的节点,也可能将一个实体与一个未连接的节点相连。这样一来这个子图就可能包含一些有效路径,但根据问题的意图,可能需要包含距离实体两跳(hop)的节点,故这些有效路径可能都不是正确的。
比如在图 3 中,由于答案节点“unbound1”距离实体“dbr:Send_It_On”两跳,就没有被包含在当前的子图(由实线连接)中。为了解决这个问题且避免在底层的知识图谱中搜索空间过大,本文的做法是用候选关系集合R来扩大子图中现有的边并且排除现有边代表的关系。
如图 3 所示,虚线代表扩展的边。获取子图的算法如算法 1 所示。
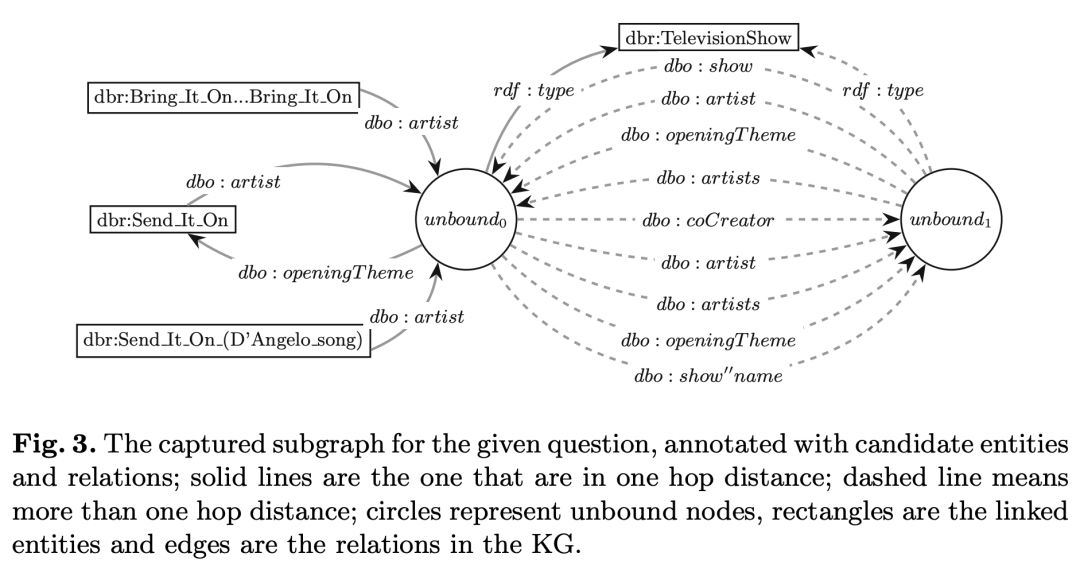
图 3 为已标注候选实体和关系的所给问题获取的子图;实线表示的是在一跳距离上的子图,虚线是在大于一跳距离上的子图,圆圈代表未连接节点,方框中是链接实体,边是知识图谱中的关系。

列出候选路径:获取覆盖了问题中所有实体和关系的子图之后,视每个未连接节点为潜在的答案节点,由此需要寻找有效路径,有效路径的定义上文已给出。
例如,图 4 中有四个有效路径。若子图中只有一个有效路径,映射该路径到 SPARQL 查询上并将其报告为所给问题对应的查询;若有不同类型的问题,比如要求计数或者是返回布尔值的问题,可能还需要进一步的扩大;若不只有一个有效路径,则需要执行如下文所示的排序任务。
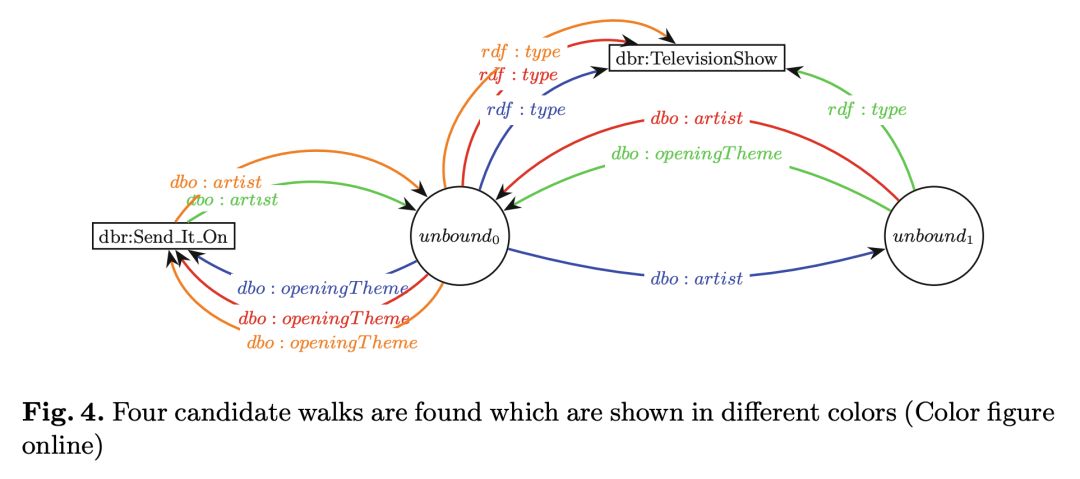
图 4 为找到的四个候选路径,分别用不同的颜色表示。
问题类型分类:SQG 支持简单和复合问题。为了支持诸如布尔型和计数型的问题,首先需要识别问题的类型。
本文的做法是训练一个 SVM 和朴素贝叶斯模型以根据问题的 TF-IDF 表示来将其分为布尔型、计数型或是列举型。给出问题的类型之后,查询生成器就可以根据类型来格式化查询。例如,查询生成器会为一个计数型查询的 SPARQL 查询输出变量增加相应的函数。
查询排名
本文猜想路径的结构是用来区分候选路径与输入问题之间相似度的一个重要特性。比如,图 7 中,已生成的四个路径有独特的结构。因此,排名模型就应该需要包含输入问题的结构。
本文给出的排名模型基于树形 LSTM(Tree-LSTM),该模型考虑候选路径关于问题句法结构上的树形表示,以此来计算相似度。树形 LSTM 旨在收纳在子节点中的信息,它考虑到子节点的状态来计算其内在状态和输出。这一结构使得树形 LSTM 能够轻松地涵盖本文中输入的树形结构。
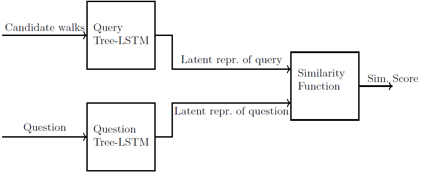
▲ 图5:排名模型结构
排名模型:图 5 展示了排名模型的架构,使用两个树形LSTM来将输入的路径和问题映射到一个潜在向量化的表达中。
之后采用一个相似度函数计算相似度并来排名。在处理问题的树形 LSTM 准备阶段,用一个占位符来代替实体的表面提及(surface mentions),在这之后创建一个依存分析树,如图 6。然后,查询树形 LSTM 接收候选路径的树形表示,如图 7,其中只有 7a 是输入问题的正确表达。
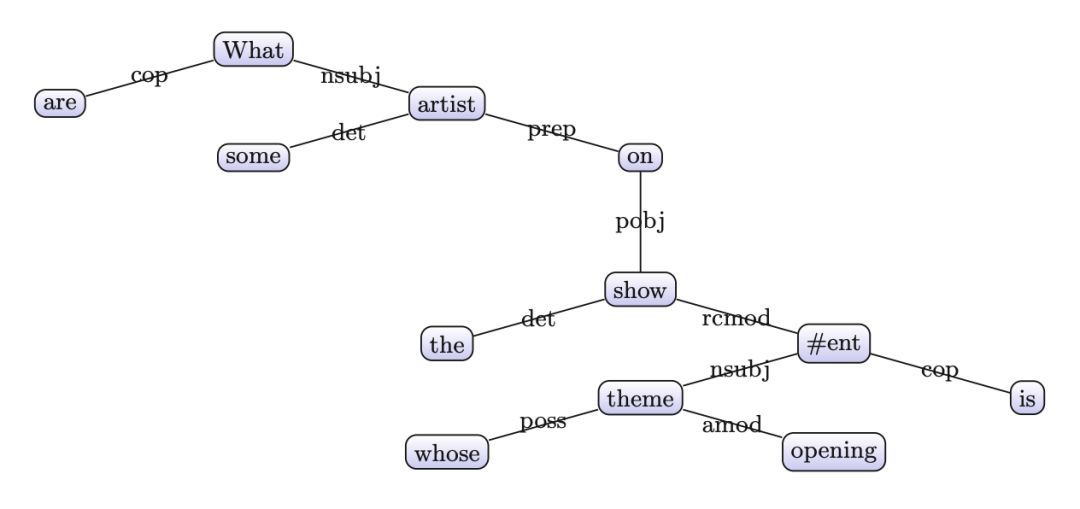
▲ 图6:问题“What are some artists on the show whose opening theme is Send It On? ”的依存分析树
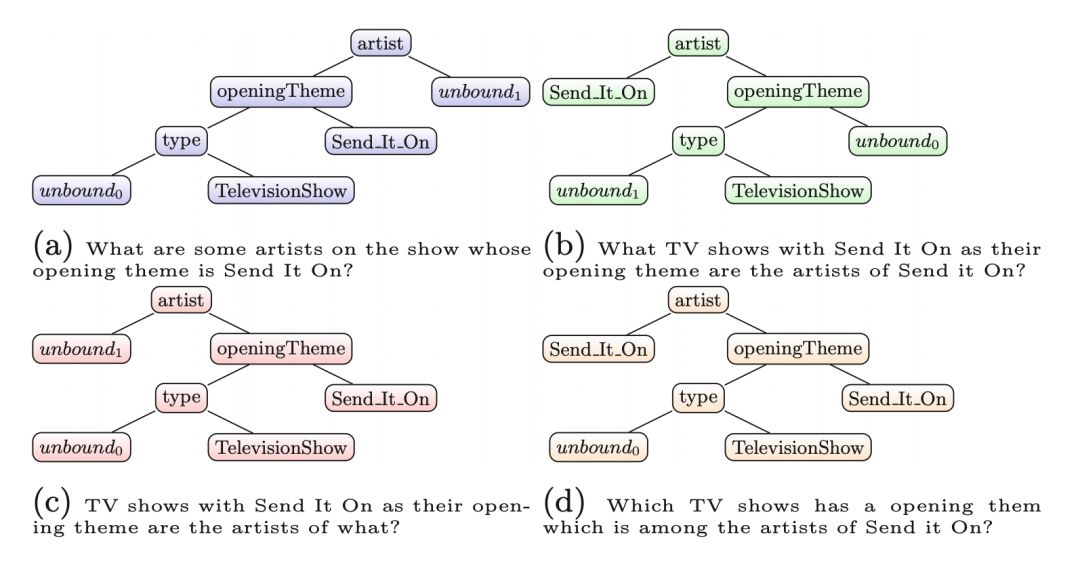
▲ 图7:候选路径的树形表示及其自然语言意思,其中颜色同图4
实验
实验相关细节
SQG 用 Python/Pytorch实现,其中排名模型中,单词表示采用 Glove 单词分词工具。实验的数据集为包含 5000 个问题-答案对的 LC-QuAD,不过实验时用的是其中的 3200 对。
对于排名模型的数据集生成,采用 Stanford 分析器来产生输入问题以及(查询生成步骤中生成的)候选查询的依存分析树,并将数据集划分成 70%/20%/10% 分别用于训练/开发/测试。
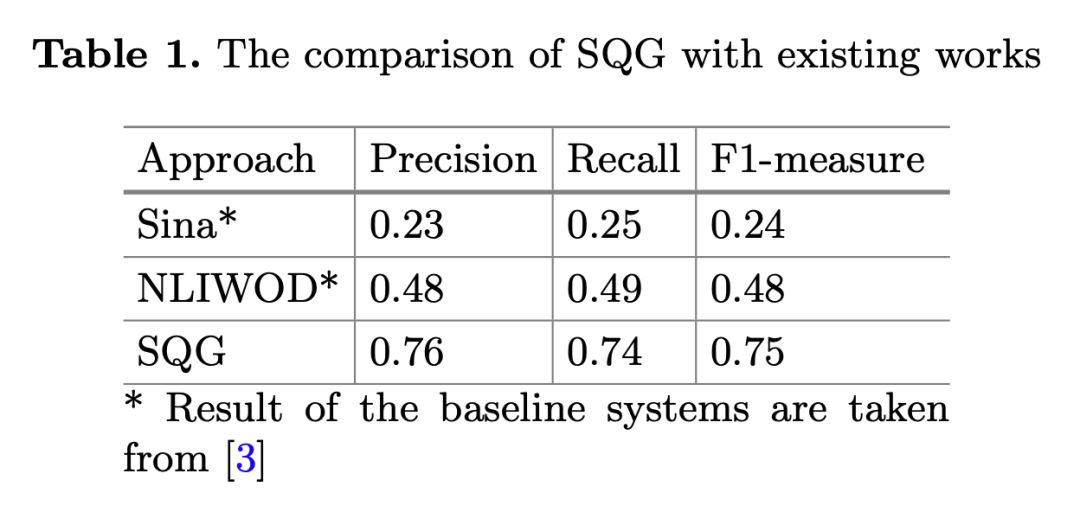
用精确率、召回率和 F1 值来衡量 SQG 的性能,基线系统为 Sina、NLIWOD。除此之外,本文还分别对 SQG 的子任务,即问题类型分类、查询生成及排名模型进行了评估。
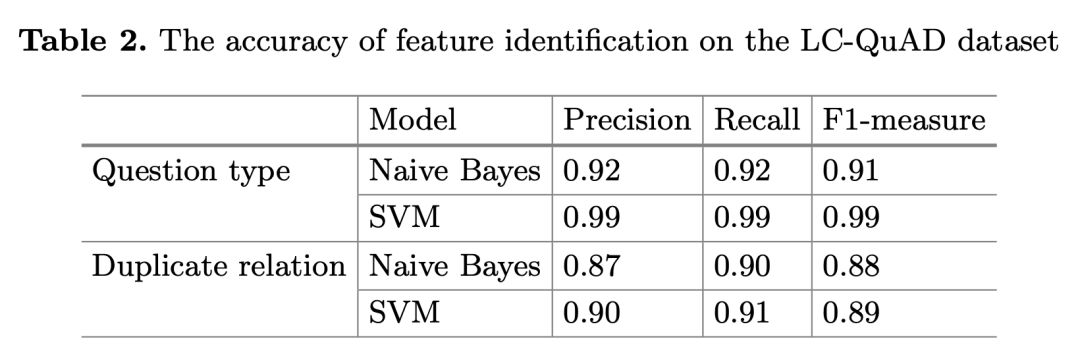
问题类型分类的评估中,评估结果独立于实体/关系链接模块,在数据集的 50% 上执行 k-折交叉验证,以训练模型并找到最优参数值然后用它评估分类器,分别评估了朴素贝叶斯和 SVM 的精确率、召回率和 F1 值。
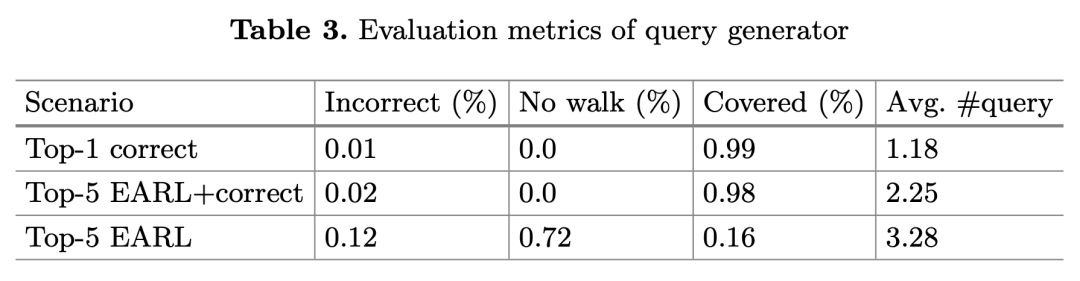
在查询生成器的评估中,引入三个评估情形。第一个是 Top-1 correct,只给出正确的链接实体/关系,以提供模型性能的上界估计。第二个是用于评估 SQG 健壮性的 Top-5 EARL+correct,EARL 是一个用于 NER 和 RE 任务的工具,此评估情形考虑来自于 EARL 的每个实体/关系的 5 个候选(查询)列表,为了评估 SQG 独立于链接系统之外的性能,当其不存在于列表中时,插入正确的目标实体/关系。第三个是 Top-5 EARL,用 EARL 的输出来评估 QG 组件在一个功能正常的 QA 系统中的性能。
对于排名模型,本文实验了两种计算相似度的函数,分别为余弦相似度和基于神经网络的函数,不过经测试神经网络的方法明显优于余弦相似度,因此结果中只分别评估三种情形下,神经网络方法计算相似度的结果。
实验结果
如下表 1 所示,SQG 表现明显优于基线系统。基线系统中有三个缺点,一是必须要接收正确的实体/关系输入;二是查询扩大的能力有限;三是缺少排名机制,这些问题在 SQG 中都得到了解决。
问题类型分类的评估结果如下表 2 所示,尽管模型简单,但大量的多样化训练数据确保了其优良性能。SQG 避免了手写模式集,因此它在不同环境下的应用性更强。
查询生成器的评估结果如下表 3 所示。在 Top-1 correct 中,由于只有真正的目标实体/关系被给到了查询生成器中,所以有效路径数量非常低。在 Top-5 EARL+correct 中,可看出查询生成器能够处理有噪声的输入,并能够涵盖 98% 的问题,并且平均每个问题生成的查询增加到了 2.25。
在 Top-5 EARL 中,表现显著下降,因为对于 85% 的问题,EARL 提供的是部分正确而不是完全正确的注释。如果只考虑 EARL 能够容纳所有正确目标链接的问题,覆盖率就能够达到 98%。
排名模型的数据集细节如下表 4。在 Top-1 correct 中,每个问题生成的查询数量是 1.18,因为没有很多可能的链接实体/关系的方式。表中第一行结果中正确/错误数据的不均衡导致排名模型接收的是一个不平衡的数据集,因为数据集中的样本大多是正例。
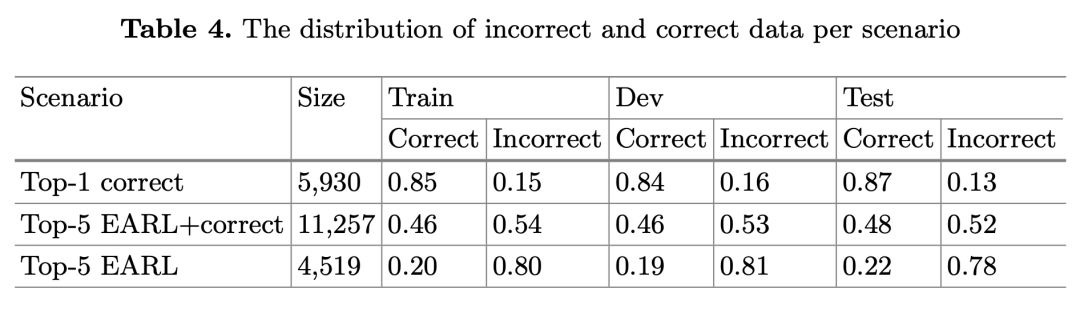
而在 Top-5 EARL+correct 中,生成的查询数量增加带来训练数据数量和多样性的增加,此时正确和错误数据的分布几乎是平衡的,这带来模型性能上的提升。
在 Top-5 EARL 中,尽管生成的查询的平均数相比前两种情形更高,但正确和错误数据的分布仍不均衡,这是因为 72% 的情况下没有路径被生成,导致生成的查询总数远比其他情形少。错误如此之高是因为 NED 和 RE 组件提供的错误注释。
排名模型的评估结果如下图 5。在 Top-1 correct 中,尽管数据集分布不均衡,排名模型也能达到 74% 的 F1 值,但由于此情形下平均查询数量只有 1.18,故此结果不能准确地反映模型的性能。
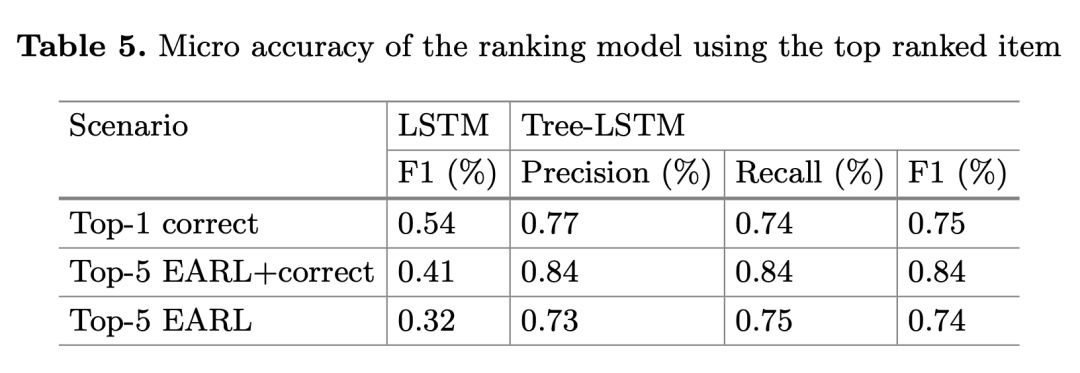
在 Top-5 EARL+correct 情形下,F1 值增加到 84%,表明模型相对于第一种情形,在数据集更大和更均衡的情况下表现更好。在 Top-5 EARL 中,微 F1 值下降到 74%。这是由于数据集的不平衡和数量小。
总结
本文探讨了 QA 系统中查询生成任务的难点,引入了可以轻松集成进 QA 工作流的模块化查询生成器 SQG,其先生成候选查询,再进行排名。实验表明 SQG 性能优于现有的查询生成方法。

点击以下标题查看更多相关文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐



