[机智的机器在学习] TensorFlow实现Kmeans聚类
[点击蓝字,一键关注~]
对于机器学习算法来说,主要分为有监督学习和无监督学习,前面有篇文章介绍过机器学习算法的分类,不知道的童鞋可以去看看。然后今天要讲的Kmeans算法属于无监督算法,也就是说它的输入只要训练集没有标签的。说到Kmeans, 就不得不提什么是聚类?简单说就是“合并同类项”,把性质相近的物体归为一类,就是聚类。这样就自然会产生两个问题,1,怎么确定分类的种类数目,也就是说,把所有的样本数据分为几类比较合适? 2,怎么衡量归在一类的样本“性质”是不是相近?如果解决了这两个问题,那么简单的聚类问题就解决了。
Kmeans是一种比较古老聚类算法,但是应用非常广泛。(鬼知道,反正我没怎么用过~)。Kmeans其实包含两个部分,一个是K,一个是means,我们分别来解释一下。首先对于n个样本属于R^n空间(也就是实数空间)中的点,K就是表示把样本分类多少类,K等于几,就分为几类。当我们做完聚类以后,每一类最中心的那个点,我们叫做聚类中心(centroids),聚类的过程或者目标是:每个类里面的样本到聚类中心的距离的平均值(menas)最小。注意理解一下这句话,通俗理解一下,假设分为3类,A, B, C三类,分别包含m,n,p个样本,聚类中心分别为M,N,P。那么对于A类来说,m个样本分别到点M的距离就有m个,这m个距离必然是不一样的,所以我们对着m个数求平均值,记做mean_1,如果聚类正确的话,则mean_1是所有聚类可能中距离的means最小的那个。Kmeans就是这样的。。。。
下面是kmeans的目标函数,C是聚类中心,卡方是所有训练数据。
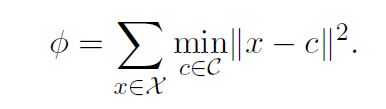
Kmeans算法的步骤:
随机选择k个初始聚类中心
计算所有样本到每个聚类中心的距离,使得样本点到ci的距离比到cj的距离要更近,当i不等于j的时候。
更新聚类中心C,使得ci是所有附近点的中心。
重复2,3,知道聚类中心不再变化。
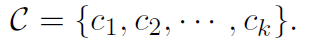
下面我们用TensorFlow来实现以下Kmens算法,数据还是iris数据。
正式实战开始之前,有几个tf的函数需要简单说一下,大家可能没有见过的,主要是:
tf.unsorted_segment_sum
tf.slice
tf.tile
tf.control_dependencies
tf.group
## tf.unsorted_segment_sum
tf.unsorted_segment_sum和tf.segment_sum类似,而tf.segment_sum和tf.reduce_sum类似,reduce系列之前讲过,不清楚的同学可以翻一下历史消息。然后我们看个栗子。其实说到这里,也是想告诉大家一个学习TensorFlow的方法,就是当你不知道某个函数怎么用的时候,那就写个简单的栗子,自己随便编几个tensor,去试一试就知道怎么回事了。
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
def tf_segment():
sess = tf.InteractiveSession()
seg_ids = tf.constant([0, 1, 1])
tens1 = tf.constant([[2, 5, 3, -5],
[0, 3, -2, 5],
[4, 3, 5, 3]])
print sess.run(seg_ids)
print ' - * - ' * 3
print sess.run(tens1)
print ' - * - ' *3
print tf.segment_sum(tens1, seg_ids).eval()
print ' - * - ' *3
print tf.unsorted_segment_sum(tens1,
seg_ids, num_segments=3).eval()
if __name__ == "__main__":
tf_segment()
"""
[0 1 1]
- * - - * - - * -
[[ 2 5 3 -5]
[ 0 3 -2 5]
[ 4 3 5 3]]
- * - - * - - * -
[[ 2 5 3 -5]
[ 4 6 3 8]]
- * - - * - - * -
[[ 2 5 3 -5]
[ 4 6 3 8]
[ 0 0 0 0]]
"""
这里除了segment_sum还有类似Reduce系列的其他segment,可以自己去试试。unsort的区别不大,主要在于seg_ids可以是无序的。
## tf.slice
slice的函数原型如下:
def slice(input_, begin, size, name=None):
其中的input_,就是要处理的输入,begin表示开始的位置,size表示处理后input_的大小shape。
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
def slice_tf():
import tensorflow as tf
import numpy as np
x = [[1, 2, 3], [4, 5, 6]]
y = tf.constant([[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]],
[[13, 14, 15],
[16, 17, 18]]])
sess = tf.Session()
begin_x = [1, 0]
size_x = [1, 2]
begin_y = [1, 0, 0]
size_y = [1, 2, 2]
x_out = tf.slice(x, begin_x, size_x)
y_out = tf.slice(y, begin_y, size_y)
print sess.run(x_out)
print "- * - " * 5
print sess.run(y_out)
if __name__ == "__main__":
slice_tf()
"""
[[4 5]]
- * - - * - - * - - * - - * -
[[[ 7 8]
[10 11]]]
"""
## tf.tile
这个函数的作用是拼接tensor的,第一个参数是输入的tensor,第二个参数是指定拼接的维度。看栗子。
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
def tile_tf():
y = tf.constant([[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]],
[[13, 14, 15],
[16, 17, 18]]])
sess = tf.Session()
out = tf.tile(y, [1, 2, 1])
print y.get_shape().as_list()
print "- * - " * 5
print sess.run(out)
print "- * - " * 5
print sess.run(out).shape
if __name__ == "__main__":
tile_tf()
"""
[3, 2, 3]
- * - - * - - * - - * - - * -
[[[ 1 2 3]
[ 4 5 6]
[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]
[ 7 8 9]
[10 11 12]]
[[13 14 15]
[16 17 18]
[13 14 15]
[16 17 18]]]
- * - - * - - * - - * - - * -
(3, 4, 3)
"""
## tf.control_dependencies
这个函数的目的是为了控制tensorflow计算图的计算顺序的,一般会写在一个with语句里面,我们知道python中with语句也叫“上下文管理器”,比如:
def contr(a, b):
with tf.control_dependencies(control_inputs=[a,b]):
c = 1
这里将先计算a,b的值,然后在返回c的值。就是这么简单。
## tf.group
文档中是这样解释的:
Create an op that groups multiple operations. When this op finishes, all ops in `input` have finished. This op has no output
创建一个操作op,这个op对于多个op可以分组,当group这个op结束的时候,输入的op也都结束了。
它的返回值是An Operation that executes all its inputs, 一个op,可以执行全部的输入。
好了,有了这些,下面看下Kmeans的实现代码:
# coding: utf-8
import tensorflow as tf
import numpy as np
import time
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
import sys
f = open("log", 'w')
sys.stdout = f
print "- * - " * 20
print '\n' * 3
def make_iris():
iris = datasets.load_iris()
x = pd.DataFrame(iris.data)
x.to_csv("iris_x.csv", sep=',',
header=None, index=None)
# 计算类内平均值函数
def bucket_mean(data, bucket_ids, num_buckets):
# 第一个参数是tensor,第二个参数是簇标签,
# 第三个是簇数目
total = tf.unsorted_segment_sum(
data, bucket_ids, num_buckets)
count = tf.unsorted_segment_sum(
tf.ones_like(data), bucket_ids, num_buckets)
return total / count
def f():
sample_number = 150
variables = 4
kluster_number = 3
MAX_ITERS = 10000
centers = [(1, 1), (2, 2), (3, 3)]
data = pd.read_csv("iris_x.csv",
header=None).values
points = tf.Variable(data)
cluster_assignments = tf.Variable(
tf.zeros([sample_number],
dtype=tf.int64))
centroids = tf.Variable(
tf.slice(
points.initialized_value(),
[0, 0],
[kluster_number,
variables]))
rep_centroids = tf.reshape(
tf.tile(centroids, [sample_number, 1]),
[sample_number, kluster_number, variables])
rep_points = tf.reshape(
tf.tile(points, [1, kluster_number]),
[sample_number, kluster_number, variables])
distance = tf.square(rep_points - rep_centroids)
sum_squares = tf.sqrt(
tf.reduce_sum(distance,
reduction_indices=2))
best_centroids = tf.argmin(sum_squares, 1)
did_assignments_change = tf.reduce_any(
tf.not_equal(best_centroids,
cluster_assignments))
means = bucket_mean(points, best_centroids, kluster_number)
with tf.control_dependencies([did_assignments_change]):
do_updates = tf.group(
centroids.assign(means),
cluster_assignments.assign(best_centroids))
print do_updates
changed = True
iters = 0
fig, ax = plt.subplots()
colourindexes = [2, 1, 4]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while changed and iters < MAX_ITERS:
fig, ax = plt.subplots()
iters += 1
[changed, _] = sess.run(
[did_assignments_change,
do_updates])
[centers, assignments] = sess.run(
[centroids,
cluster_assignments])
print "means: "
print sess.run(means)
print "rep_centroids: "
print sess.run(rep_centroids)
print "rep_points: "
print sess.run(rep_points)
print "best_centroids: "
print sess.run(best_centroids)
ax.scatter(sess.run(points).transpose()[0],
sess.run(points).transpose()[1],
marker='8', s=200,
c=assignments)
ax.scatter(centers[:, 0], centers[:, 1],
marker='^', s=550, c=colourindexes)
ax.set_title('Iteration ' + str(iters))
plt.savefig("kmeans_" + str(iters) + ".png")
ax.scatter(sess.run(points).transpose()[0],
sess.run(points).transpose()[1],
marker='o', s=200, c=assignments)
plt.savefig("s.png")
print centers
print assignments
if __name__ == "__main__":
f()
最后经过12轮迭代,得到下面下面这个分类结果,当然这里只取了两维,对于高维数据的可视化,有兴趣的童鞋可以去看看t-SNE方法, 恩, 我就是说说。这里不考虑效果怎么样~,就是学习。
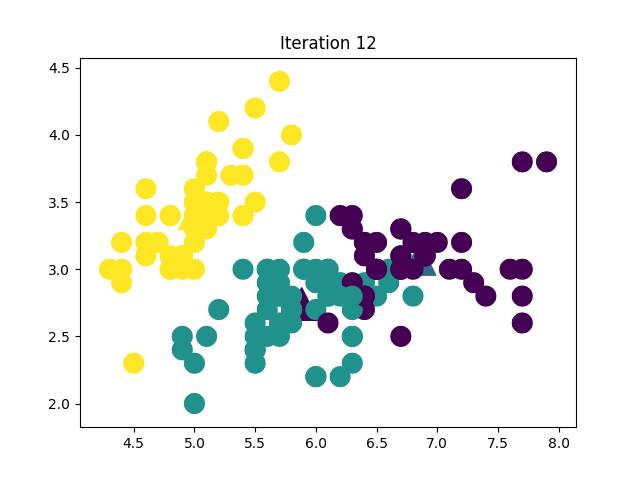
好了,今天就到这里了,周末愉快~。我以后可能会保持在一周1篇的速度吧,如果以后事情不多的话,会慢慢增加,如果我做的工作能帮到你一点点点,那我就很满足了,谢谢!
参考文献
[1] David Arthur and Sergei Vassilvitskii, k-means++: The Advantages of Careful Seeding
============End============


