利用 Universal Transformer,翻译将无往不利!
文 / Google Brain Team 的研究科学家 Stephan Gouws、阿姆斯特丹大学的 Mostafa Dehghani 博士生、谷歌研究实习生
去年,我们发布了 Transformer,这是一种新的机器学习模型,相较现有的机器翻译算法和其他语言理解任务,成效卓著。 在 Transformer 之前,大多数基于神经网络的机器翻译方法依赖于循环运算的递归神经网络(RNN),它们使用循环(即每一步的输出都进入下一步)按递归顺序运行(例如,逐字翻译句中的单词)。 虽然 RNN 在建模序列方面非常强大,但它们的顺序性本质意味着它们训练起来非常缓慢,因为长句需要更多的处理步骤,并且其繁复循环的结构也使训练难上加难。
相较于基于 RNN 的方法,Transformer 不需要循环,而是并行处理序列中的所有单词或符号,同时利用自醒机制将上下文与较远的单词结合起来。 通过并行处理所有单词,并让每个单词在多个处理步骤中处理句子中的其他单词,使 Transformer 的训练速度比起复制模型要快得多。 值得注意的是,与此同时其翻译结果也比 RNN 好得多。 然而,在更小、更结构化的语言理解任务中,或是简单的算法任务诸如复制字符串(例如,将 “abc” 的输入转换为 “abcabc”)上,Transformer 则表现欠佳。 相比之下,在这方面表现良好的模型,如神经 GPU 和神经图灵机,在大规模语言理解任务(如翻译)中溃不成军。
在《Universal Transformer》一文中,我们使用新颖高效的时间并行循环方式将标准 Transformer 扩展为计算通用(图灵完备)模型,从而可在更广泛的任务中产生更强的结果。我们将模型建立在 Transformer 的并行结构上,以保持其快速的训练速度。但是我们用单一的时间并行循环的变换函的多次应用代替了 Transformer 中不同变换函数的固定堆叠(即,相同的学习转换函数在多个处理步骤中被并行应用于所有符号,其中每个步骤的输出馈入到下一个步骤中)。关键在于,RNN 逐个符号(从左到右)处理序列,而 Universal Transformer 同时处理所有符号(像 Transformer 一样),随后使用自醒机制在可变数量的情况下并行地对每个符号的解释进行细化。 这种时间并行循环机制比 RNN 中使用的顺序循环更快,也使得 Universal Transformer 比标准前馈 Transformer 更强大。
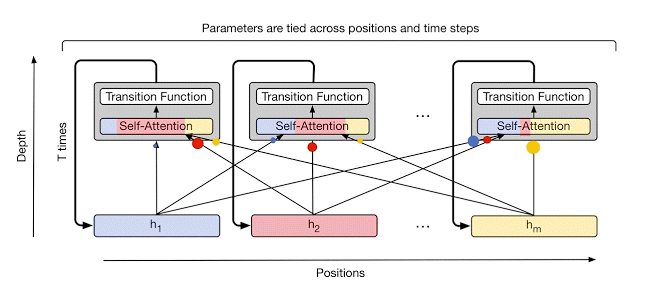
Universal Transformer 模型通过自醒机制结合不同位置的信息,应用循环转换函数,以并行化方式重复为序列的每个位置细化一系列向量表征(显示为 h1 到 hm)。 箭头表示操作之间的依赖关系
在每个步骤中,利用自醒机制将信息从每个符号(例如,句中的单词)传递到其他符号,就像在原始 Transformer 中一样。 但是,现在这种转换的次数(即循环步骤的数量)可以提前手动设置(比如设置为某个固定数字或输入长度),也可以通过 Universal transformer 本身进行动态设定。 为了实现后者,我们在每个位置都添加了一个自适应计算机制,可以分配更多处理步骤给较模糊或需要更多计算的符号。
我们用一个直观的例子来说明这是如何起效的,比如 “I arrived at the bank after crossing the river 我穿过河流终于抵达岸边” 这句话。 在这个案例中,与没有歧义的 “I 我” 或 “river 河流” 相比,推断 “bank” 一词最确切的含义需要用到更多的语景信息。 当我们使用标准 Transformer 对这个句子进行编码时,我们需要把同样的计算量无条件地应用于每个单词。 然而, Universal Transformer 的自适应机制允许模型仅在更模糊的单词上花费更多的计算,例如, 使用更多步骤来整合消除 “bank” 的歧义所需额外的语境信息,而在那些比较明确的单词上则花费较少的步骤。
起初,让 Universal Transformer 仅重复应用单一学习函数来处理其输入似乎是有限制性的,尤其是与学习应用固定序列的不同函数的标准 Transformer 相比。但是,学习如何重复应用单一函数意味着应用程序的数量(处理步骤)现在是可变的,而这是一个很重要的区别。综上所述,除了允许 Universal Transformer 对更模糊的符号应用更多的计算之外,它还允许模型根据输入的整体大小来调整函数应用的数量(更长的序列的更多步骤),或者根据训练期间学习到的其他特性来动态地决定将函数应用到输入的任何给定部分的频率。这使得 Universal Transformer 在理论意义上更加强大,因为它可以有效地学习将不同的变换应用于输入的不同部分。这是标准 Transformer 无法做到的事情,因为它是由只应用一次的学习变换块的固定堆叠组成。
尽管 Universal Transformer 在理论上更强大,但我们也关心实验性能。我们的实验结果证实,Universal Transformers 确实能够从样本中学习如何复制和反转字符串,以及如何比 Transformer 或 RNN 更好地执行整数加法(尽管不如神经 GPU 那么好)。此外,在各种具有挑战性的语言理解任务中,Universal Transformer 的泛化效果明显更好,且在 bAbI 语言推理任务和很有挑战性的 LAMBADA 语言建模任务上达到了当前最优性能。但或许最令人感兴趣的是,Universal Transformer 在与基础 Transformer 使用相同数量的参数、训练数据以相同方式进行训练时,其翻译质量比后者提高了 0.9 个 BLEU 值。去年 Transformer 发布时,它的性能比之前的模型提高了 2 个 BLEU 值,而 Universal Transformer 的相对改进量是去年的 50%。
因此,Universal Transformer 弥补了大规模语言理解任务(如机器翻译)上具有竞争力的实际序列模型与计算通用模型(如神经图灵机或神经GPU)之间的差距,计算通用模型可使用梯度下降来训练,用于执行随机算法任务。 我们很高兴看到时间并行序列模型的最新进展,以及处理深度中计算能力和循环的增加,我们希望对此处介绍的基本 Universal Transformer 的进一步改进将有助于我们构建更多,更强大的,更能高效利用数据的算法功能,泛化性能超越当前最优算法。
如果您想要亲身体验,可以在开源的 Tensor2Tensor 存储库中找到用于训练和评估 Universal Transformers 的代码。
注:代码链接
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/research/universal_transformer.py
鸣谢
执行本项研究的人员 Mostafa Dehghani,Stephan Gouws,Oriol Vinyals,Jakob Uszkoreit 和 Łukasz Kaiser。 另外还要感谢来自 Ashish Vaswani,Douglas Eck 和 David Dohan 富有成效的意见建议和灵感。
更多 AI 相关阅读:






