关于Transformer和BERT,在面试中有哪些细节问题?

©PaperWeekly 原创 · 作者|海晨威
学校|同济大学硕士生
研究方向|自然语言处理
随着 NLP 的不断发展,对 Transformer 和 BERT 相关知识的研 (mian) 究 (shi) 应 (ti) 用 (wen),也越来越细节,下面尝试用 QA 的形式深入不浅出 Transformer 和 BERT。
Transformer 在哪里做了权重共享,为什么可以做权重共享? BERT 的三个 Embedding 直接相加会对语义有影响吗? 在 BERT 中,token 分 3 种情况做 mask,分别的作用是什么? 为什么 BERT 选择 mask 掉 15% 这个比例的词,可以是其他的比例吗? 为什么 BERT 在第一句前会加一个 [CLS] 标志? 使用 BERT 预训练模型为什么最多只能输入 512 个词,最多只能两个句子合成一句?
1. Transformer 在哪里做了权重共享,为什么可以做权重共享?
Transformer 在两个地方进行了权重共享:
2. Decoder 中 Embedding 层和 Full Connect(FC)层权重共享。
对于第一点,《Attention is all you need》中 Transformer 被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于 Encoder 和 Decoder,嵌入时都只有对应语言的 embedding 会被激活,因此是可以共用一张词表做权重共享的。
论文中,Transformer 词表用了 bpe 来处理,所以最小的单元是 subword。英语和德语同属日耳曼语族,有很多相同的 subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大 [1]。
但是,共用词表会使得词表数量增大,增加 softmax 的计算时间,因此实际使用中是否共享可能要根据情况权衡。
对于第二点,Embedding 层可以说是通过 onehot 去取到对应的 embedding 向量,FC 层可以说是相反的,通过向量(定义为 w)去得到它可能是某个词的 softmax 概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在 FC 层的每一行量级相同的前提下,理论上和 w 相同的那一行对应的点积和 softmax 概率会是最大的(可类比本文问题 1)。
因此,Embedding 层和 FC 层权重共享,Embedding 层中和向量 w 最接近的那一行对应的词,会获得更大的预测概率。实际上,Embedding 层和 FC 层有点像互为逆过程。
但开始我有一个困惑是:Embedding 层参数维度是:(v,d),FC 层参数维度是:(d,v),可以直接共享嘛,还是要转置?其中 v 是词表大小,d 是 embedding 维度。
查看 pytorch 源码发现真的可以直接共享:
fc = nn.Linear(d, v, bias=False) # Decoder FC层定义,无 bias
weight = Parameter(torch.Tensor(out_features, in_features)) # nn.Linear 的权重部分定义
对于这个非常有意思的问题,苏剑林老师给出的回答 [2],真的很妙:
Embedding 的数学本质,就是以 one hot 为输入的单层全连接。 也就是说,世界上本没什么 Embedding,有的只是 one hot。 现在我们将 token, position, segment 三者都用 one hot 表示,然后 concat 起来,然后才去过一个单层全连接,等价的效果就是三个 Embedding 相加。
因此,BERT 的三个 Embedding 相加,其实可以理解为 token, position, segment 三个用 one hot 表示的特征的 concat,而特征的 concat 在深度学习领域是很常规的操作了。
用一个例子理解一下:
假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。
对于一个字,假设它的 token one-hot 是 [1,0,0,0];它的 position one-hot 是 [1,0,0];它的 segment one-hot 是 [1,0]。
如此得到的 word Embedding,和 concat 后的特征:[1,0,0,0,1,0,0,1,0],再经过维度为 [4+3+2,768] = [9, 768] 的 Embedding 矩阵,得到的 word Embedding 其实就是一样的。
Embedding 就是以 one hot 为输入的单层全连接。
再换一个角度理解:
直接将三个 one-hot 特征 concat 起来得到的 [1,0,0,0,1,0,0,1,0] 不再是 one-hot 了,但可以把它映射到三个 one-hot 组成的特征空间,空间维度是 4*3*2=24 ,那在新的特征空间,这个字的 one-hot 就是 [1,0,0,0,0...] (23个0)。
此时,Embedding 矩阵维度就是 [24,768],最后得到的 word Embedding 依然是和上面的等效,但是三个小 Embedding 矩阵的大小会远小于新特征空间对应的 Embedding 矩阵大小。
BERT 的三个 Embedding 相加,本质可以看作一个特征的融合,强大如 BERT 可以学到融合后特征的语义信息的。
在 BERT 的 Masked LM 训练任务中, 会用 [MASK] token 去替换语料中 15% 的词,然后在最后一层预测。但是下游任务中不会出现 [MASK] token,导致预训练和 fine-tune 出现了不一致,为了减弱不一致性给模型带来的影响,在这被替换的 15% 语料中:
-
80% 的 tokens 会被替换为 [MASK] token -
10% 的 tokens 会称替换为随机的 token -
10% 的 tokens 会保持不变但需要被预测
The Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token.
If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words. The non-masked tokens were still used for context, but the model was optimized for predicting masked words. If we used [MASK] 90% of the time and random words 10% of the time, this would teach the model that the observed word is never correct. If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
第二点的随机替换,因为需要在最后一层随机替换的这个 token 位去预测它真实的词,而模型并不知道这个 token 位是被随机替换的,就迫使模型尽量在每一个词上都学习到一个全局语境下的表征,因而也能够让 BERT 获得更好的语境相关的词向量(这正是解决一词多义的最重要特性);
第三点的保持不变,也就是真的有 10% 的情况下是泄密的(占所有词的比例为15% * 10% = 1.5%),这样能够给模型一定的 bias ,相当于是额外的奖励,将模型对于词的表征能够拉向词的真实表征(此时输入层是待预测词的真实 embedding,在输出层中的该词位置得到的embedding,是经过层层 Self-attention 后得到的,这部分 embedding 里多少依然保留有部分输入 embedding 的信息,而这部分就是通过输入一定比例的真实词所带来的额外奖励,最终会使得模型的输出向量朝输入层的真实 embedding 有一个偏移)。
而如果全用 mask 的话,模型只需要保证输出层的分类准确,对于输出层的向量表征并不关心,因此可能会导致最终的向量输出效果并不好 [4]。
BERT 采用的 Masked LM,会选取语料中所有词的 15% 进行随机 mask,论文中表示是受到完形填空任务的启发,但其实与 CBOW 也有异曲同工之妙。
那从 CBOW 的滑动窗口角度,10%~20% 都是还 ok 的比例。
上述非官方解释,是来自我的一位朋友提供的一个理解切入的角度,供参考。
5. 为什么 BERT 在第一句前会加一个 [CLS] 标志?
BERT 在第一句前会加一个 [CLS] 标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
这里补充一下 bert 的输出,有两种:
一种是 get_pooled_out(),就是上述 [CLS] 的表示,输出 shape 是 [batch size,hidden size]。
一种是 get_sequence_out(),获取的是整个句子每一个 token 的向量表示,输出 shape 是 [batch_size, seq_length, hidden_size],这里也包括 [CLS],因此在做 token 级别的任务时要注意它。
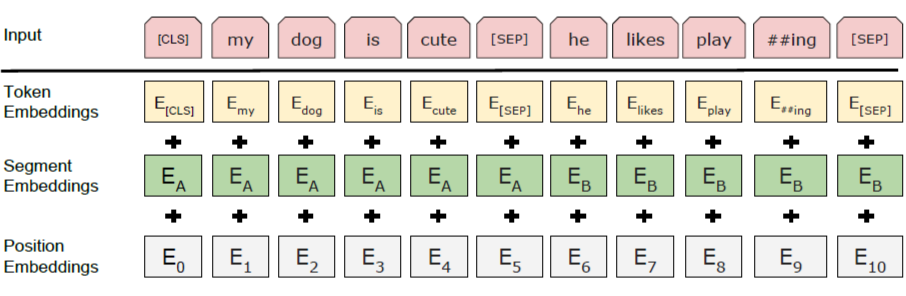
在 BERT 中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch 代码 [5] 中它们是这样的:
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
"max_position_embeddings": 512
"type_vocab_size": 2

参考文献
[1] https://www.zhihu.com/question/333419099/answer/743341017
[2] https://www.zhihu.com/question/374835153
[3] https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
[4] https://zhuanlan.zhihu.com/p/50443871
[5] https://github.com/hichenway/CodeShare/tree/master/bert_pytorch_source_code
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





