【综述】深度学习攻防对抗在图像数据、图数据以及文本数据上的应用
【导读】深度神经网络(DNN)在不同领域的大量机器学习任务中取得了前所未有的成功。然而,对抗性例子的存在引起了人们对将深度学习应用于对安全性有严苛要求的应用程序的关注。因此,人们对研究不同数据类型(如图像数据、图数据和文本数据)上的DNN模型的攻击和防御机制越来越感兴趣。近期,来自密歇根州立大学的老师和同学们,对网络攻击的主要威胁及其成功应对措施进行系统全面的综述。特别的,他们在这篇综述中,针对性的回顾了三种流行数据类型(即、图像数据、图数据和文本数据)。
文章地址:
https://www.zhuanzhi.ai/paper/89d1d390e7bb8de650fc374141101374
arxiv地址:
https://arxiv.org/pdf/1909.08072.pdf
【简介】
深度神经网络在许多机器学习任务中越来越受欢迎和成功。它们已在图像、图形、文本和语音等领域应用于不同的识别问题,取得了显著的成功。在图像识别领域,他们能够以接近人类水平的精度识别物体(Krizhevsky et al., 2012;He et al.,2016)。它们还用于语音识别(Hinton et al., 2012)、自然语言处理(Hochreiter & Schmidhuber, 1997)和游戏(Silver et al.,2016a)。
由于这些成就,深度学习技术也被应用于对安全有严苛要求的任务上。例如,在自动驾驶汽车中,深度卷积神经网络(CNNs)被用于识别路标(Cires An et al., 2012)。这里使用的机器学习技术需要高度精确、稳定和可靠。但是,如果CNN模型不能识别路边的“STOP”标志,而车辆继续行驶,那该怎么办呢?这将是一个危险的局面。同样,在金融欺诈检测系统中,企业经常使用graph convolutional networks (GCNs) (Kipf & Welling, 2016)来判断客户是否值得信任。如果有欺诈者为了逃避公司的检测而隐藏自己的身份信息,将会给公司带来巨大的损失。因此,深度神经网络的安全问题成为人们关注的焦点。
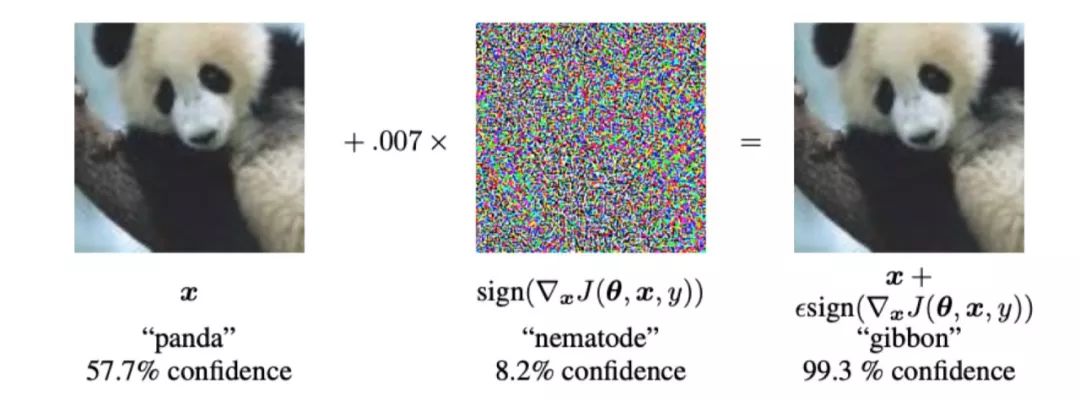
近年来很多工作(Szegedy et al., 2013; Goodfellow et al., 2014b; He et al., 2016b)都已经表明,DNN模型容易受到对抗性样本的攻击,对抗性样本的正式定义为:“对抗性样本是机器学习模型的输入,攻击者故意设计这些输入来导致模型出错。“在图像分类领域,这些含有对抗性的样本是有意合成的图像,看起来几乎与原始图像完全相同(见图2),但可能误导分类器提供错误的预测输出。”
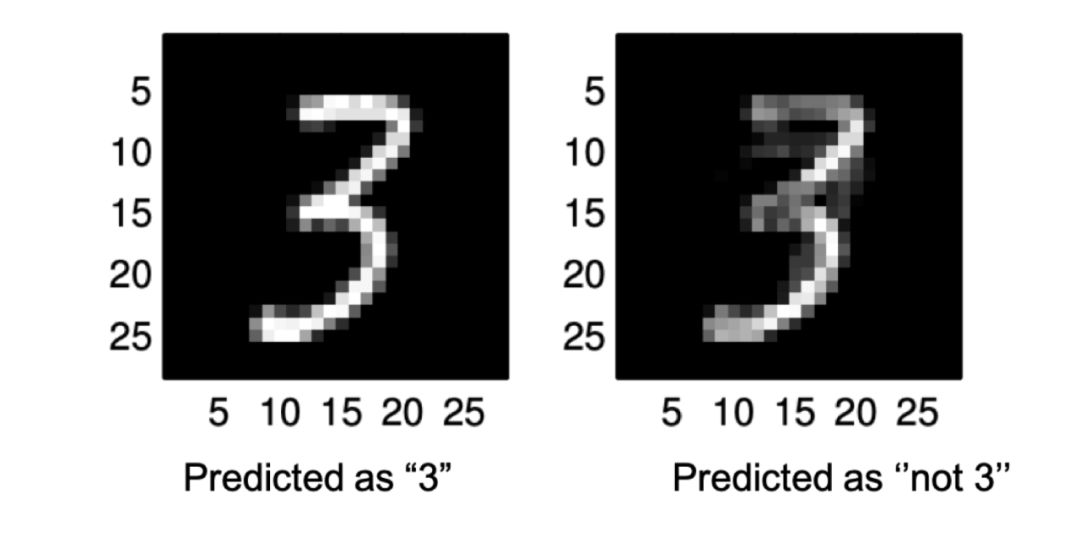
对于MNIST数据集上训练良好的DNN图像分类器,几乎所有的数字样本都可以在原始图像上添加一个不易察觉的扰动。
同时,在其他涉及图数据、文本或音频的应用领域,也存在类似的对抗性攻击方案来混淆深度学习模型。例如,仅扰动几个边就可以误导图神经网络(Z¨ugner et al., 2018),而在一个句子中插入拼写错误可以欺骗文本分类或对话系统(Ebrahimi et al., 2017)。因此,在所有应用领域中都存在对抗性的例子,这提醒了研究人员不要在对安全性有要求的机器学习任务中直接采用DNNs。
为了应对对抗样本的威胁,许多为了保护深层神经网络而开发的工作也陆续被发表出来。这些方法可以大致分为三种主要类型:
Gradient Masking 梯度掩蔽 (Papernot et al., 2016b; Athalye et al., 2018):由于大多数攻击算法都是基于分类器的梯度信息,掩盖或模糊梯度会混淆攻击机制。
Robust Optimization 鲁棒优化(Madry et al., 2017;Kurakin et al. 2016b): 这些研究试图训练一个鲁棒的分类器,来正确地分类对抗样本。
Adversary Detection 对抗检测(Carlini & Wagner, 2017a; Xu et al. 2017):这些方法试图在将样本输入深度学习模型之前检查样本是良性的还是对抗性的。它可以被看作是一种针对性防范对抗样本的方法。
除了可以帮助建立安全可靠的DNN模型外,研究对抗样本及其应对措施也有助于我们了解DNN的性质,从而完善DNN模型。例如,对抗干扰对人眼来说是感知上难以区分的,但却可以影响DNN的检测。这表明,DNN的预测方法与人类推理不一致。有的工作(Goodfellow et al., 2014b; Ilyas et al., 2019)尝试解释为什么会有DNN的对抗样本的存在,这可以帮助我们对DNN模型有更多的了解。
在本文中,我们旨在总结和讨论主要研究涉及对抗样本和他们的防御方法的文章。我们系统和全面的总结了图像数据、图数据和文本数据领域的state-of-the-art对抗攻防算法。本次调查的主要结构如下: 在第二节中,我们将介绍一些在对抗攻击及其防御中经常使用的重要定义和概念。并提供了攻击和防御类型的基本分类。在第3节和第4节中,我们讨论了图像分类场景中的主要攻击和防御技术。我们用第5节来简要介绍一些试图解释对抗性样本现象的研究。第6节和第7节分别回顾了图数据和文本数据的研究。
【部分文章】










请关注专知公众号(点击上方蓝色专知关注)
后台回复“ASAD” 就可以获取深度学习攻防对抗综述的下载链接




