原创 | Attention Modeling for Targeted Sentiment
作者:黑龙江大学nlp实验室研究生赵光耀

一、导读
本文主要重现了论文'Attention Modeling for Targeted Sentiment'。这篇论文由Jiangming Liu创作并发表在EACL2017。通过阅读本文,你将会学习到:
如何去建立target实体和它上下文(context)的关系
三种不同的Attention模型的对比
如何用Pytorch实现该论文
二、问题
Targeted Sentiment Analysis是研究target实体的情感极性分类的问题。只根据target实体,我们没有办法判断出target实体的情感极性,所以我们要根据target实体的上下文来判断。那么,第一个要解决的问题就是:如何建立target实体和上下文之间的关系。
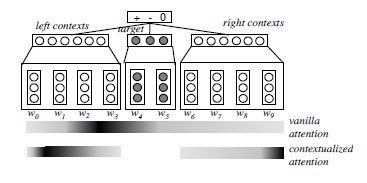
在这篇论文之前,已经有了很多种做法。在Vo and Zhang(2015)的论文中提出的方法是:把一个句子拆分成了三部分,target部分,left context部分和right context部分(如图一所示)。在Zhang et al.(2016)的论文中提出,用三个gate神经元来控制target,left context和right context之间的交互。在Tang et al. (2016)的论文中提出的方法是:把target的embedding向量与它的上下文的embedding向量连接成为一个特殊的向量,然后使用循环神经网络分别对left context和right context进行编码。
以上两种方法都对解决第一个问题作出了很大的贡献,但是以上方法仍然没有明确的表示出每一个单词对target实体情感极性贡献的大小。所以第二个问题就是让机器学习到上下文中每个词对target实体的情感极性的贡献度。
先简单的介绍一下注意力机制。从视觉的角度来说,注意力模型就无时不刻在你身上发挥作用,比如你过马路,其实你的注意力会被更多地分配给红绿灯和来往的车辆上,虽然此时你看到了整个世界;比如你很精心地偶遇到了你心仪的异性,此刻你的注意力会更多的分配在此时神光四射的异性身上,虽然此刻你看到了整个世界,但是它们对你来说跟不存在是一样的。那么在判断target实体的情感极性上,如下面这句话:
She began to love [miley ray cyrus]1 since 2013 :)
首先分析这句话,miley ray cyrus就是target实体,1代表情感是积极的。假设我们的视线是一种资源,我们只能把资源分配给更能表达情感的词上面。‘since 2013’对情感的表达没有任何意义,我们把资源分给没有任何意义的词就是一种浪费,也是十分的不合理的。而‘love’和‘:)’这种能表达情感的词就会吸引我们更多的注意力。于是left context和right context就可以由加权和来表示:


就如同图一所示,我们的注意力应当聚焦于颜色很深的词上,颜色越深,代表它的贡献度越大。
三、注意力机制模型
注意一下:'·'代表矩阵相乘,'
论文中提到了三种模型(接下来将要使用的三种不同的attention模型)。这三种模型都需要经过embedding层和BILSTM层:
首先经过embedding层得到
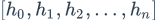
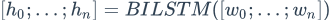
target 用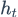

left_context就是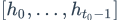
right_context就是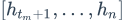
1.Vanilla Attention Model (BILSTM-ATT)
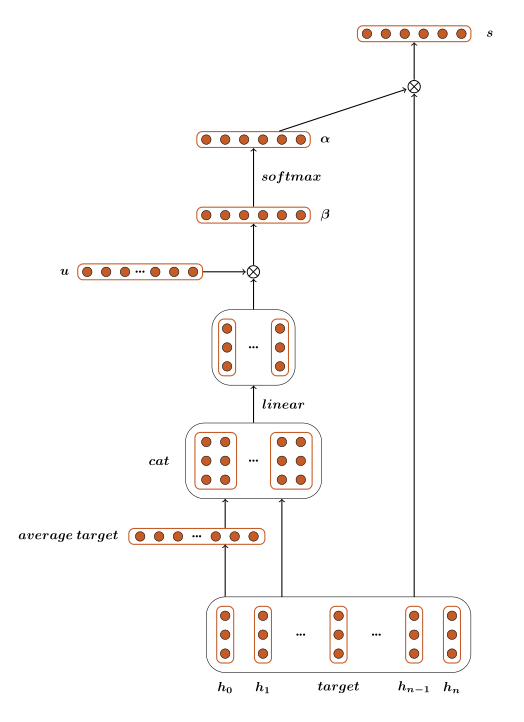
第一个attention模型是Vanilla attention model。首先通过计算每一个词的权重α(α是一个标量),与每一个词的向量表示相乘后再求和,最后得到整句话s的向量表示:

求α的公式:

β的值是由target和上下文单词共同决定的。从下面公式可以看出,每个词与target相连接,经过一个线性层与tanh激活函数,然后与张量U相乘得到一个标量。公式如下:

通过以上公式,能求得该句子的最后表示s,然后用s来预测情感标签可能的分布p,最后经过一个线性层和一个softmax激活函数得到预测值p。求p公式如下:
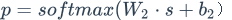
模型流程图如下:
2.Contextualized Attention Model (BILSTM-ATT-C)
Contextualized Attention Model是在Vanilla Model的基础上衍生的一个模型。这个模型将上下文拆分成两部分,分别为left_context和right_context。然后对left_context和right_context分别做与Vanilla Attention Model一样的操作。即:
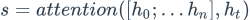
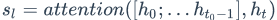
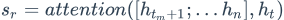
这三个向量经过线性层的和,再经过softmax,得到预测值p。公式如下:

3.Contextualized Attention with Gates (BILSTM-ATT-G)
受到LSTM中gate的启发,BILSTM-ATT-G摒弃了BILSTM-ATT-C中直接过线性层的方法,采取了gate的方法。考虑到代表情感的特征可以在左边语境(left_context)中或者右边的语境(right_context)中,于是采用了gate的方法控制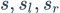
gate分别是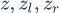
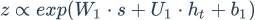
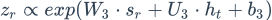
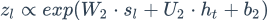
并且
接下来gate与数据流按位相乘得到最后的向量表示:
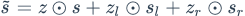
最后经过一个线性层和softmax得到预测值p:
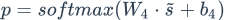
四、编码
程序使用的Pytorch框架,因为Pytorch框架有以下优点:
使用python语言,张量和动态神经网络都能使用GPU加速。
具体代码详解:
Vanilla Model不用把句子分割成left_context和right_context。因此很容易实现batch_size > 1的设计。主要的层次有embedding层,dropout层,双向lstm层,线性层linear_2。linear_1层和参数u主要是为了计算的。
class Vanilla(nn.Module):
def __init__(self, embedding):
super(Vanilla, self).__init__()
self.embedding = nn.Embedding(embed_num, embed_dim)
self.embedding.weight.data.copy_(embedding)
self.dropout = nn.Dropout(dropout)
self.bilstm = nn.LSTM(embed_dim,hidden_size,dropout)
self.linear_1 = nn.Linear(hidden_size,attention_size,bias=True)
self.u = Parameter(torch.randn(1,attention_size),
self.linear_2 = nn.Linear(hidden_size,label_num,bias=True)
def forward():
passBILSTM-ATT-C和BILSTM-ATT-G模型需要把句子分割成left_context和right_context。编程上很难设计出很好的batch_size > 1的方法,因此使用的是batch_size = 1的方法。这两个模型是Vanilla Model的衍生,所以在代码上有所依赖,因此设计了一个Attention Class,作用是为了计算s。这个类是计算图的一部分,输入是context和target,输出是s。
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.linear = nn.Linear(input_size * 2, output_size, bias=True)
self.u = Parameter(torch.randn(output_size, 1)) def forward():
passBILSTM-ATT-C模型会用到Attention类。
BILSTM-ATT-G模型中的操作,使用softmax函数实现该操作。
# cat z_all, z_l, z_r
z_all = torch.cat([z_all, z_l, z_r], 1)
# softmax
z_all = F.softmax(z_all)详细代码参考代码在github上:
https://github.com/vipzgy/AttentionTargetSentiment
五、实验结果与结论
本文实现了3种模型,并在2种数据上进行了三分类的实验。
1.数据
数据集的来源:
实验的两个数据集,一个是Tang et al. (2016) (T-Dataset)的叫做benchmark training/test dataset,另外一个the training/dev/test dataset of Zhang et al. (2016) (Z-Dataset),包含MPQA corpus2 and Mitchell et al. (2013)’s corpus3。
Z-Dataset:
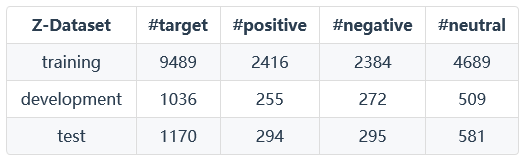
T-Dataset:
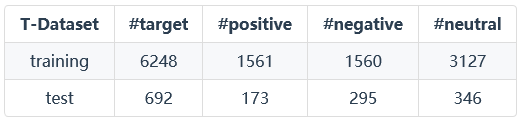
2.实验结果
Z-Dataset上的实验结果:
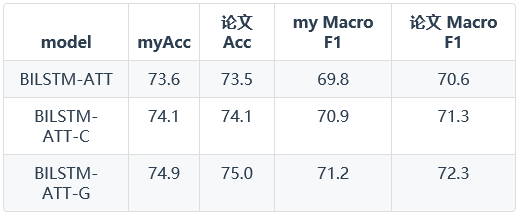
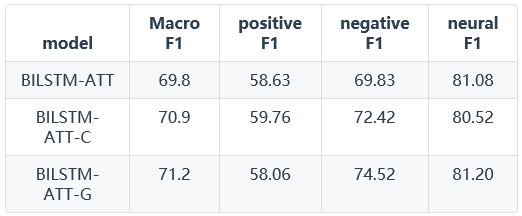
T-Dataset上的实验结果:
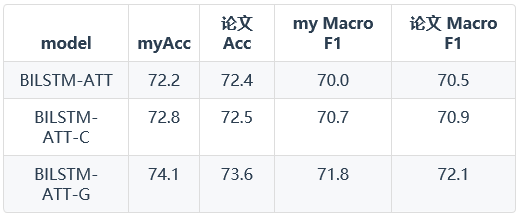
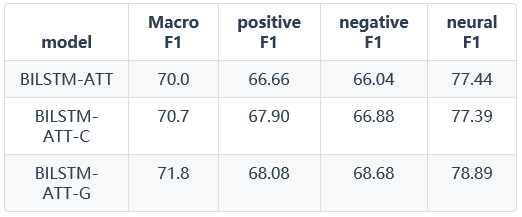
由以上结果可以得知,使用attention model在情感分类任务上取得了更好的效果。在Vanilla Attention Model、Contextualized Attention Model和Contextualized Attention with Gates三种模型上,使用门的思想提升了程序的精确度,达到了更好的效果。
六、引用
Jiangming Liu and Yue Zhang. 2017. Attention modeling for targeted sentiment. EACL 2017
Meishan Zhang, Yue Zhang, and Tin Duy Vo. 2015.Neural networks for open domain targeted sentiment. Association for Computational Linguistics
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classifi- cation. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Meishan Zhang, Yue Zhang, and Duy-Tin Vo. 2016. Gated neural networks for targeted sentiment analysis. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12-17, 2016, Phoenix, Arizona, USA.
声明:此文章为本实验室原创,如需转载文章,请注明出处。






