笔记 | Sentiment Analysis

本文来源:徐阿衡博客
博客链接:http://www.shuang0420.com/
本文为Stanford Dan Jurafsky & Chris Manning: Natural Language Processing 课程笔记。
Sentiment Analysis 有许多别称,如 Opinion extraction/Opinion mining/ Sentiment mining/Subjectivity analysis,都是同一个意思,不过隐含着不同的应用场景。大致来说,情感分析有以下的应用:
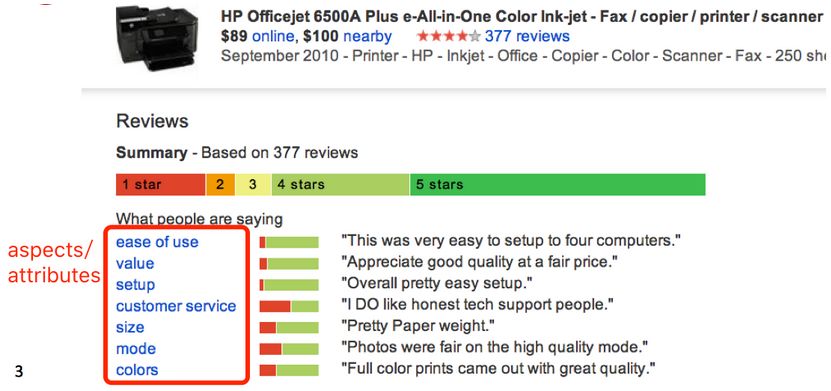
Products: 产品评价,不仅仅是简单的好评差评,情感分析还能分析人们对具体产品的具体属性的具体评价,如下图,对 product review 抽aspects/attributes,判断 sentiment,最后 aggregate 得出结果。
Public sentiment: 公众意见(public opinion),比如说分析消费者信息指数,股票指数等。之前就有人做过用 CALM 来预测道琼斯指数(Bollen et al. 2011 Twitter mood predicts the stock market),算法也应用到了工业场景。
Politics: 公共政策,看公众对候选人/政治议题的看法。
Prediction: 预测选举结果,预测市场趋势等等。
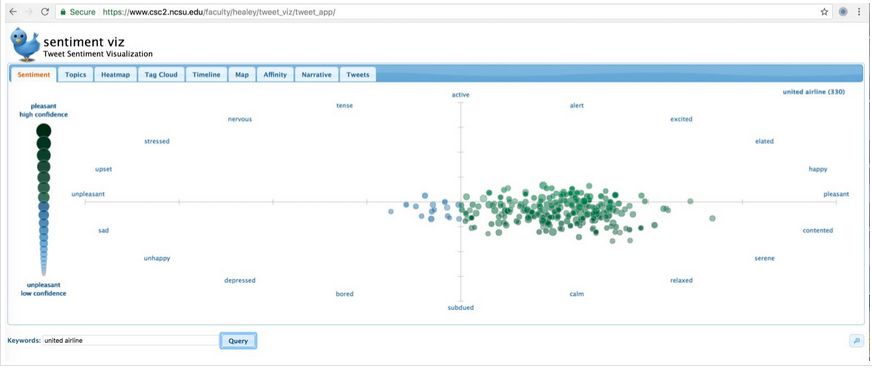
一个成熟的产品Twitter Sentiment App,能够通过 Twitter 数据来分析人们对某个品牌/话题的情感。
Attitudes: “enduring, affectively colored beliefs, dispositions towards objects or persons”
Sentiment analysis 说白了就是来分析人们对一个事物的态度(attitudes),包含下面几个元素(以 Mary likes the movie 为例)
Holder (source) of attitude
持有态度的人: MaryTarget (aspect) of attitude
对象: the movieType of attitude
态度类型: like
From a set of types: Like, love, hate, value, desire, etc.
Or (more commonly) simple weighted polarity: positive, negative, neutral, together with strengthText containing the attitude
文本: Mary likes the movie
Sentence or entire document
最简单的情感分析任务,或者说在情感分析方向的 baseline model,是分析/预测电影评论是 positive 还是 negative 的。
常用到的语料库 IMDB Polarity Data 2.0,
目的: polarity detection: is this review positive or negative?
步骤:
Tokenization
Feature Extraction
Classification using different classifiers
Naive Bayes
MaxEnt
SVM
1.1Sentiment Tokenization
除了正常 tokenization 要注意的问题如处理 HTML/XML markup 外,情感分析还可能需要处理
twitter markup(hashtag 等)
Capitalization: 大小写通常会保留,大写字母往往反映强烈的情感
Emotions(表情符号)

有用的 Tokenizer 代码
Christopher Potts sentiment tokenizer
Brendan O’Connor twitter tokenizer
1.2Extracting Features
关于特征提取,两个重要的问题,一是怎么来处理否定词(negation),二是选什么词作为特征。
Negation
I didn't like this movie
I really like this movie
didn't like this movie, but I
=>
didn't NOT_like NOT_this NOT_movie but I
具体见:
Das, Sanjiv and Mike Chen. 2001. Yahoo! for Amazon: Extracting market sentiment from stock message boards. In Proceedings of the Asia Pacific Finance Association Annual Conference (APFA).
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. 2002. Thumbs up? Sentiment Classification using Machine Learning Techniques. EMNLP-2002, 79—86.
Words to use
一般两种方案,一是仅仅使用形容词(adjectives),而是使用所有的单词(all words),通常而言,使用所有的词的效果会更好些,因为动词(verbs)、名词(nouns)会提供更多有用的信息。
1.3Classifier
作为 Baseline model,这里会使用 Naive Bayes,没啥悬念,计算如下
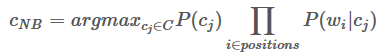
Prior: how likely we see a positive movie review
Likelihood Function: for every review, how likely every word is expressed by a positive movie review
采用 Laplace/Add-one Smoothing
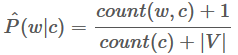
一个变种或者改进版是Binarized(Boolean feature) Multinomial Naive Bayes,它基于这样一个直觉,对情感分析而言,单词是否出现(word occurrence)这个特征比单词出现了几次(word frequency)更为重要,举个例子,出现一次 fantastic 提供了 positive 的信息,而出现 5 次 fantastic 并没有给我们提供更多信息。boolean multinomial Naive Bayes 就是把所有大于 1 的 word counts 压缩为 1。
算法如下

也有研究认为取中间值 log(freq(w)) 效果更好一些,相关论文如下:
B. Pang, L. Lee, and S. Vaithyanathan. 2002. Thumbs up? Sen+ment Classification using Machine Learning Techniques. EMNLP-‐2002, 79—86.
V. Metsis, I. Androutsopoulos, G. Paliouras. 2006. Spam Filtering with Naive Bayes – Which Naive Bayes? CEAS 2006 -‐ Third Conference on Email and Anti‐Spam.
K.-‐M. Schneider. 2004. On word frequency informa+on and negative evidence in Naive Bayes text classifica+on. ICANLP, 474-‐485.
JD Rennie, L Shih, J Teevan. 2003. Tackling the poor assumptions of naive bayes text classifiers. ICML 2003
当然在实践中,MaxEnt 和 SVM 的效果要比 Naive Bayes 好的多。
1.4Problems
有些句子里并不包含情感词(sentiment word),如下面一句是 negative 的态度,然而并不能通过情感词来得出
“If you are reading this because it is your darling fragrance, please wear it at home exclusively, and tape the windows shut.”
还有一个问题是排序问题(Order effect),尽管前面堆砌了很多情感词,但最后来个全盘否定,显然 Naive Bayes 没法处理这种问题
例如

看一下目前已经有的 Lexicons,
The General Inquirer
List of Categories
Spreadsheet
LIWC(Linguistic Inquiry and Word Count)
MPQA Subjectivity Cues Lexicon
Bing Liu Opinion Lexicon
SentiWordNet
看下各个词库的 disagreements between polarity lexicons
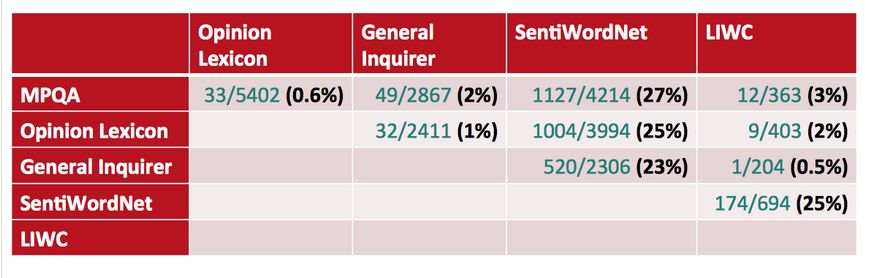
那么怎么来分析 IMDB 里每个单词的 polarity 呢?
How likely is each word to appear in each sentiment class?
likelihood:
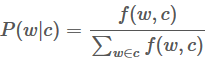
Make them comparable between words - Scaled likelihood:
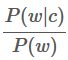
更多见 Potts, Christopher. 2011. On the negativity of negation. SALT 20, 636-‐659.
除了目前已有的 lexicon,我们还可以根据自己的语料库来训练自己的 sentiment lexicon。
2.1Semi-supervised learning of lexicons
基于少量的有标注的数据+人工建立的规则,采用 bootstrap 方法来学习 lexicon
Hatzivassiloglou and McKeown intuition for identifying word polarity
论文: Vasileios Hatzivassiloglou and Kathleen R. McKeown. 1997. Predicting the Semantic Orientation of Adjectives. ACL, 174–181
基于这样的假设:
用 AND 连起来的形容词有着相同的 polarity
fair and legitimate, corrupt and brutal用 BUT 连起来的形容词则相反
fair but brutal
论文方法:
1. 对 1336 个形容词形成的种子集合进行标注,657 个 positive,679 个 negative
2. 通过 google 搜索来查询 conjoined 形容词,eg. “was nice and”
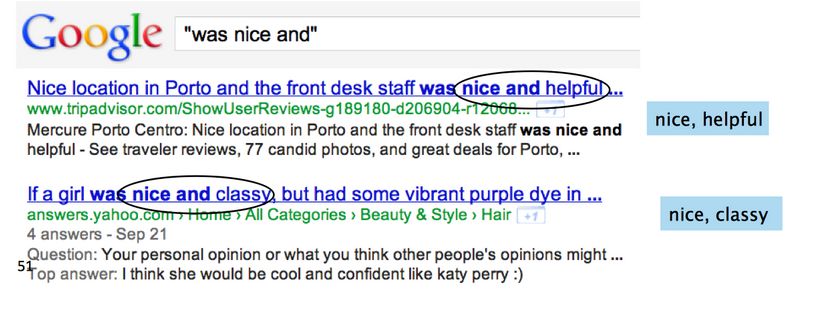
3. Supervised classifier 通过 count(AND), count(BUT) 来给每个词对(word pair)计算 polarity similarity
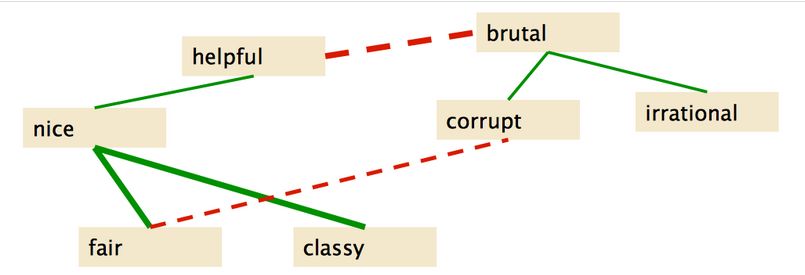
4. 将 graph 分区
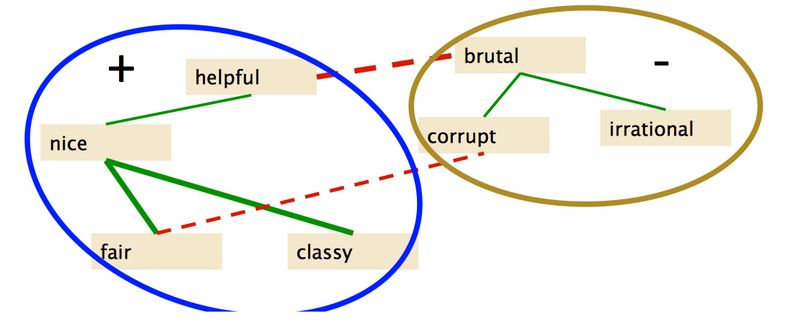
但是这种方法难以处理短语
Turnev Algorithm
论文: Turney (2002):Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews
步骤:
1. 从评论中抽取形容词短语(two-word phrase)
2. 学习短语的 polarity
如何衡量短语的 polarity 呢?
基于下面的假设
Positive phrases co-‐occur more with “excellent”
Negative phrases co-‐occur more with “poor”
用 PMI(Pointwise Mutual Information) 来计算 co-occurrence
Mutual information between 2 random variables X and Y
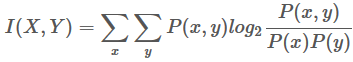
Pointwise mutual information: how much more do events x and y co-occur than if they were independent
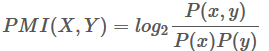
同样通过搜索引擎(Altavista)查询得到概率
P(word) = hits(word)/N
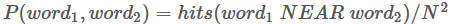
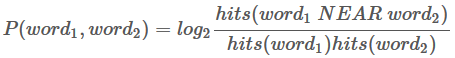

3. Rate a review by the average polarity of its phrases
一般来说 baseline 的准确率是 59%, Turney algorithm 可以提高到 74%。
Using WordNet to learn polarity
论文:
-
S.M. Kim and E. Hovy. 2004. Determining the sentiment of opinions. COLING 2004
-
M. Hu and B. Liu. Mining and summarizing customer reviews. In Proceedings of KDD, 2004
步骤:
有一小部分 positive/negative seed-words
从 WordNet 中找到 seed-words 的同义词(synonyms)和反义词(antonyms)
Positive Set: positive words 的同义词 + negative words 的反义词
Negative Set: negative words 的同义词 + positive words 的反义词重复 2 直到达到终止条件
过滤不合适的词
Summary
采用半监督方法来引入 lexicons,好处是:
can be domain-specific
can be more robust(for more/new words)
Intuition:
starts with a seed set of words(good,poor)
find other words that have similar polarity:
• Using “and” and “but”
• Using words that occur nearby in the same document
• Using WordNet synonyms and antonyms
4.1Finding aspects/attributes/target
论文:
M. Hu and B. Liu. 2004. Mining and summarizing customer reviews. In Proceedings of KDD.
S. Blair-‐Goldensohn, K. Hannan, R. McDonald, T. Neylon, G. Reis, and J. Reynar. 2008. Building a Sen+ment Summarizer for Local Service Reviews. WWW Workshop.
很多时候,一条评论并不能简单的被归为 positive/negative,它可能讨论了多个维度,既有肯定又有否定,如下面这个句子
The food was great but the service was awful!
这条评论就是对食物(food)持肯定态度(positive),对服务(service)持否定态度(negative),在这种情况下,我们不能简单的对这条评论进行 positive/negative 的分类,而要对其在 food,service 这两个维度上的态度进行分类。food,service 这些维度,或者说 attributes/aspects/target 从哪里来? 有两种方法,一种是从文本中抽取常用短语+规则来作为 attributes/aspects,另一种是预先定义好 attributes/aspects。
Frequent phrases+rules
首先找到产品评论里的高频短语,然后按规则进行过滤,可用的规则如找紧跟在 sentiment word 后面的短语,”…great fish tacos” 表示 fish tacos 是一个可能的 aspect。
Supervised classification
对一些领域如 restaurants/hotels 来说,aspects 比较规范,所以事实上可以人工给一些产品评论标注 aspect(aspects 如 food, décor, service, value, NONE),然后再给每个句子/短语分类看它属于哪个 aspect。
具体步骤:
从评论中抽取句子/短语
对句子/短语进行情感分类
得到句子/短语的 aspects
汇总得到 summary
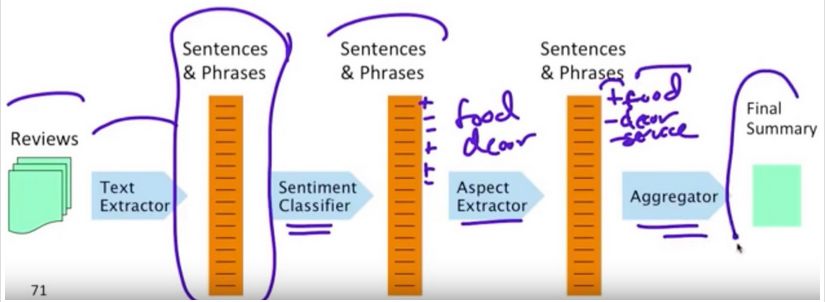
值得注意的是,baseline method 的假设是所有类别出现的概率是相同的。如果类别不平衡(在现实中往往如此),我们不能用 accuracy 来评估,而是需要用 F-scores。而类别不平衡的现象越严重,分类器的表现可能就越差。
有两个办法来解决这个问题
Resampling in training
就是说如果 pos 有10^6 条数据,neg 有 10^4 的数据,那么我们都从 10^4 的数据中来划分训练数据Cost-sensitive learning
对较少出现的那个类别的 misclassification 加大惩罚(penalize SVM more for misclassification of the rare thing)
4.2How to deal with 7 stars
论文: Bo Pang and Lillian Lee. 2005. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. ACL, 115–124
怎样来处理评分型的评论?
Map to binary
压缩到 positive/negative。比如说大于 3.5 的作为 negative,其他作为 positiveUse linear or ordinal regression
or specialized models like metric labeling
4.3Summary on Sentiment
通常被建立分类/回归模型来预测 binary/ordinal 类别
关于特征提取:
negation 很重要
对某些任务,在 Naive bayes 里使用所有的词汇表现更好
对其他任务,可能用部分词汇更好
Hand-built polarity lexicons
Use seeds and semi-supervised learning to induce lexicons
对其他任务也可以用相似手段
Emotion:
• Detecting annoyed callers to dialogue system
• Detecting confused/frustrated versus confident studentsMood:
• Finding traumatized or depressed writersInterpersonal stances:
• Detection of flirtation or friendliness in conversationsPersonality traits:
• Detection of extroverts
E.g., Detection of Friendliness
Friendly speakers use collaborative conversational style
- Laughter
- Less use of negative emotional words
- More sympathy
That’s too bad I’m sorry to hear that!
- More agreement
I think so too!
- Less hedges
kind of sort of a little …

推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Highway Networks For Sentence Classification
 欢迎关注交流
欢迎关注交流





