免费!速成!人气爆棚!国外最火的深度学习实践课新版发布,100%全新前沿内容
晓查 夏乙 假装发自 凹非寺
量子位 出品 | 公众号 QbitAI
好消息,又有新课程推荐!
国外最受好评、理论+实践相结合、完全免费的AI课程——“给程序员的实践深度学习课”,刚刚上线了全新的2019版!
课程出品方、fast.ai创始人Jeremy Howard介绍说,这次的课程,内容100%全新,还包括之前从未介绍过的一些新成果,以及它们的现实应用。
其中有些成果,甚至新到论文都还没发表。比如说,用迁移学习训练GAN,训练时间从几天缩短到了几小时。
整个课程一共7节,带你从理论到应用学成深度学习,计算机视觉、NLP、推荐系统等等一课打尽。
Jeremy发推宣布不到半天,600多人转发推荐,连机器学习顶会ICML官推都转了。

前两期课程的学生和各路网友都跑出来花式赞美,甚至有不少人直接说它是“最好的深度学习课程”。
web框架Django的开发者之一Simon Willison就曾经在博客上分享过自己学了一节课,训练最厉害的图像分类模型的经历。

还有学生上课成瘾,愿意一次又一次地回炉再深造。一位名叫ScoutOrgo的网友就是这么干的。他在极客扎堆儿的HackerNews社区评论说:
fast.ai课程每次迭代我都上,每次都觉得很值。最新的2019课程也好优秀,虽然里边的很多概念我都学过了,还是每节课都能学到一大堆东西。
课如其名,这套课程的核心是“实践”。前半部分,几乎完全集中在实战技巧上,对于理论只提到了实践中绕不开的那些;到了后半部分,才逐步深入地探讨了理论。
课程地址:
https://course.fast.ai/
更贴心的论坛,可搜索的视频
随着新版课程一起上线的,还有更国际化的课程社区。
Jeremy介绍说,他们为课程论坛添加了新功能,能按照时区、地点、语言给话题分类,想创建或者寻找同一地区、用母语讨论的学习小组更容易了。
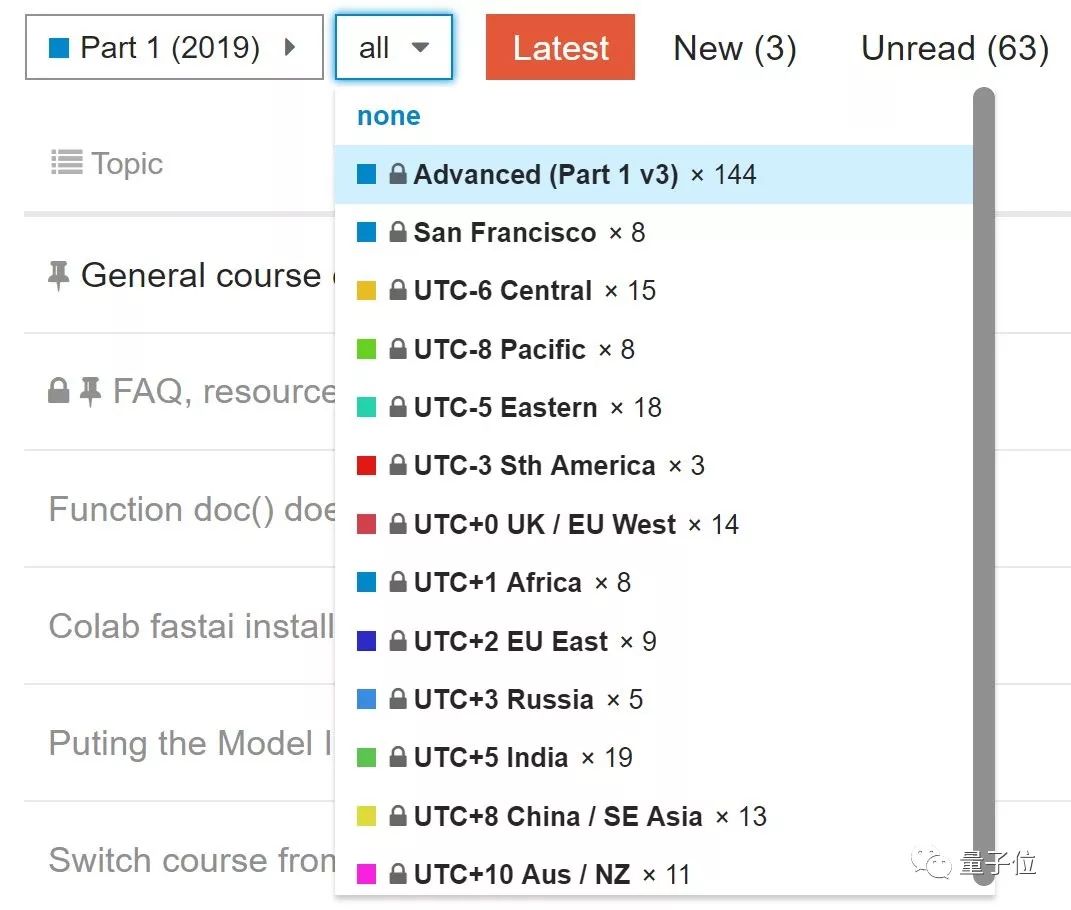
不过现在,这个功能似乎出了点小bug,暂时没上线。Jeremy也说正在修复,欢迎有同学试用成功了告诉我们。
参与到社区中,跟同学们讨论本来就是好好学习的一个重要环节,现在,连“让你和同胞用母语讨论”这样贴心的功能都来了,还有什么理由不好好学习呐?
论坛地址:
https://forums.fast.ai/c/part1-v3
除了各国人民跨语言跨时区讨论之外,可能两小时的视频也会成为很多同学的学习障碍。
因此,新版课程的播放器也是更新过的,非常强大,可以搜索课程内容,并直接跳转到你要找的视频部分。
△ 有可检索时间线的课程视频
图像、文本、协同过滤全精通
这套课程总共有七节,每节课除了上课两小时视频之外,课后还需要花大约10个小时完成作业。
从头到尾好好学习需要大约84小时。如果留到春节假期一天一节,就是一天12小时扑在学习上,比打麻将积极进取多了,还能避开询问你为何单身的亲戚。
上课前就要会的基础知识也不多:要有一年的编程经验,而且具有高中数学知识(课程中可能穿插了一些大学数学)。
因为是用PyTorch库教学,所以最好是Python上的编程经验。
84小时看起来很长,但如果你看看课程涉及的内容,会觉得这个时间,简直太“速成”了。
课程涉及的应用有四大类,从计算机视觉、NLP、到根据表格数据做预测、推荐系统都要学。具体是这样的:

计算机视觉(例如按品种分类宠物照片)
图像分类
图像定位(分割和激活图)
图像关键点NLP(例如电影评论情绪分析)
语言建模
文件分类表格数据(例如销售预测)
分类数据
连续数据协同过滤(例如电影推荐)
这些内容覆盖的基础概念也很多,包括参数和激活、随机初始化和迁移学习、卷积、Dropout、权重衰减等等:
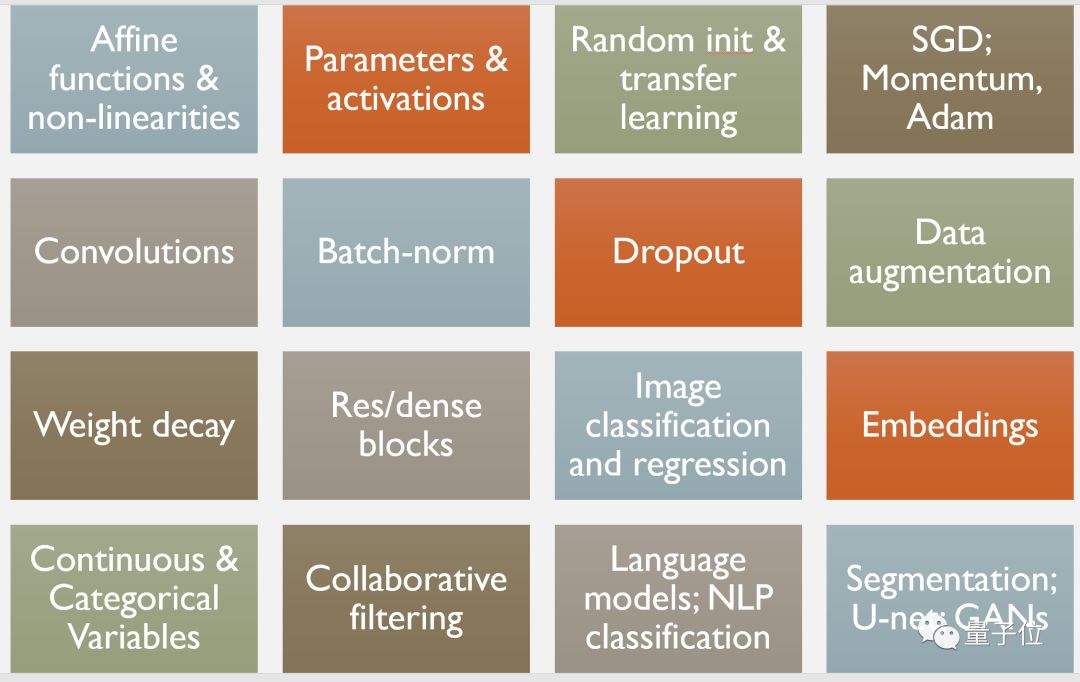
△ 课程涵盖的基础
这七节课,可以分为纯实践部分和比较深入的理论部分。
前四节课特别重实践。
第一课用迁移学习方法训练图像分类器;第二课开始自己请洗数据构建数据集;第三课从原来的单标签数据集过渡到多标签数据集,还要学习图像分割;第四课学习NLP和协同过滤,练习用算法给电影评论分类,再推荐电影。
后三节课相比之下就稍微重理论一点点。
第五课要从头开始搭建自己的神经网络,在这个过程中理解反向传播;第六课要学习各种改进训练防止过拟合的技术、理解卷积,还要讨论数据伦理;第七课要从头开始构建更复杂的ResNet和U-Net,研究各种损失函数,还要进入GAN的领域。
每一节课的具体内容是这样的:
第一课:图像分类
新人第一课,要训练一个图像分类器,能够以最高的准确度识别宠物品种。其中的关键是使用迁移学习,这也是本课程大部分内容的基础。
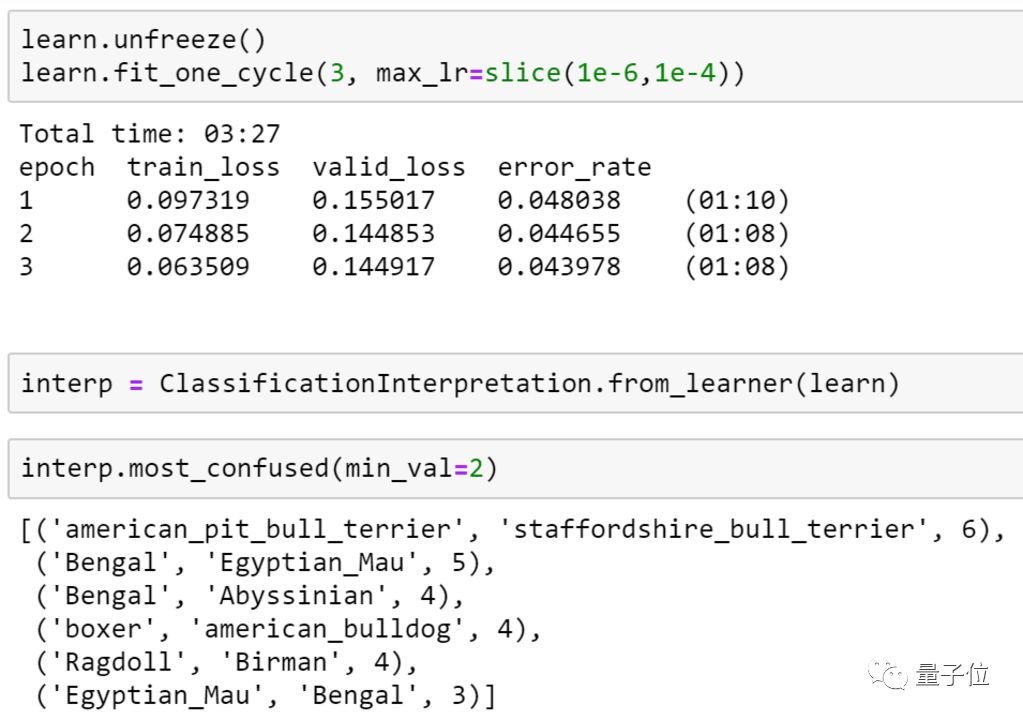
△ 训练和分析宠物品种分类器
我们将看到如何分析模型以了解其失效模式。在这一部分,我们会发现模型出错的地方与宠物育种专家可能犯错的地方相同。
最后,本节课还讨论了在训练神经网络时如何设置最重要的超参数:学习率。我们将看看标签这一重要但很少讨论的话题,并了解fastai提供的一些功能,这些功能可以轻松地将标签添加到图像中。
要注意的是,训练分类器需要连接到云GPU提供商,或者自己搭建一个合适GPU计算机,还需熟悉Jupyter Notebook环境的基础知识。
第二课:数据集的创建和清理、从头开始SGD
这部分内容是教授用户学习如何使用自己的数据搭建图像分类模型,包括以下主题:
图片集
并行下载
创建验证集
数据清理
Jeremy会教我们创建一个模型,用来区分泰迪熊和灰熊。
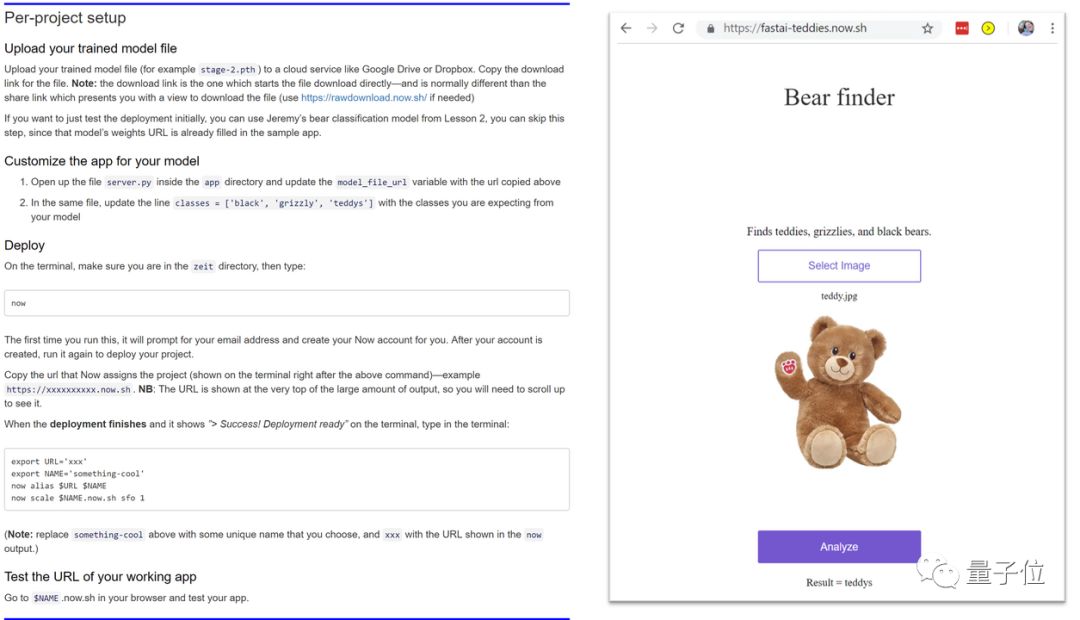
△ 图像分类器
这节课的后半部分,将从头开始训练一个简单的模型,创建我们自己的梯度下降回路。
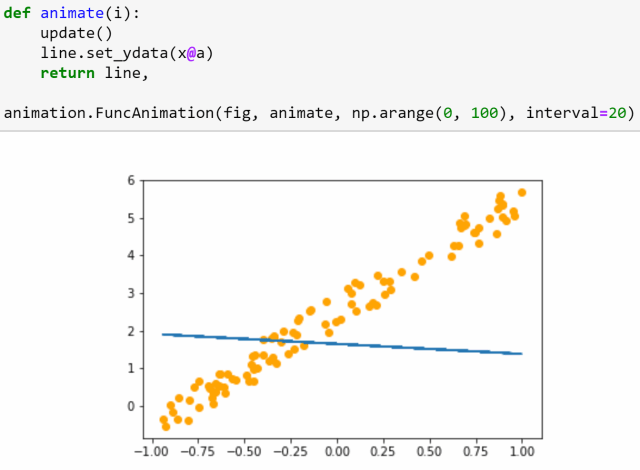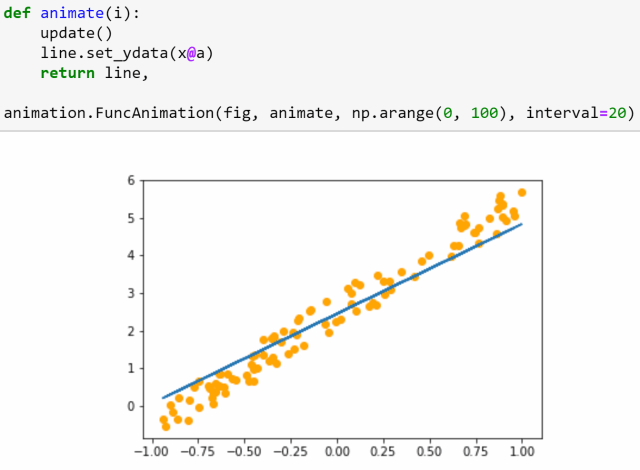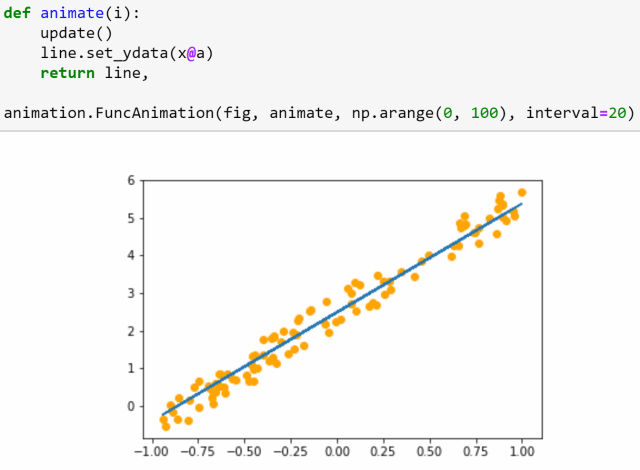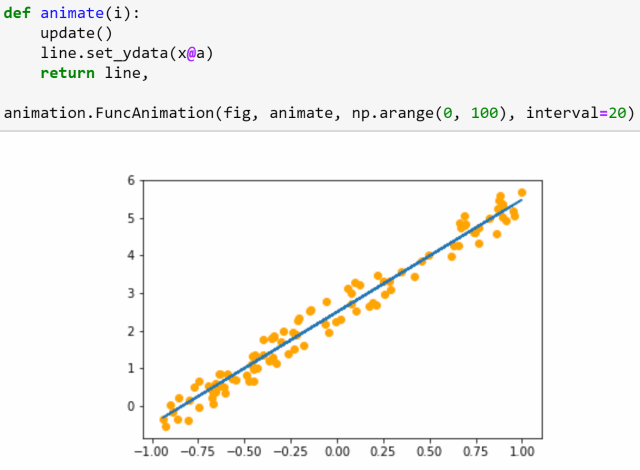
△ 梯度下降
第三课:数据块、多标签分类、分割
我们从第3课开始研究一个有趣的数据集:Planet的从太空了解亚马逊。
为了将这些数据转化为我们需要用于建模的形式,我们将使用fastai最强大的唯一工具:数据块API。这个API以后还要用很多次。
学完本课后,如果你准备学习更多关于数据块API的知识,请查看这篇文章:Wayde Gilliam的《Finding Data Block Nirvana》:
https://blog.usejournal.com/finding-data-block-nirvana-a-journey-through-the-fastai-data-block-api-c38210537fe4
Planet数据集是一个多标签数据集。也就是说:每个Planet图像可以包含多个标签,而我们看过的先前数据集每个图像只有一个标签。我们将看看我们需要对多标签数据集进行哪些更改。

△ 图像分割
接下来,我们将看一下图像分割。我们将使用与早期图像分类模型类似的技术,并进行一些调整。fastai使图像分割建模和解释与图像分类一样简单,因此不需要太多的调整。
本课程的这一部分使用的是CamVid数据集,它的误差远远低于其他任何学术论文中的模型。
第四课:NLP、表格数据、协同过滤、嵌入
在这节课中,Jeremy给我们制定的目标是,预测电影评论是积极的还是消极的,称之为情绪分析。我们将使用IMDb电影评论数据集深入研究自然语言处理(NLP)。
Jeremy将使用最初在2018年课程期间开发的ULMFiT算法,他说这是当今最准确的情绪分析算法。
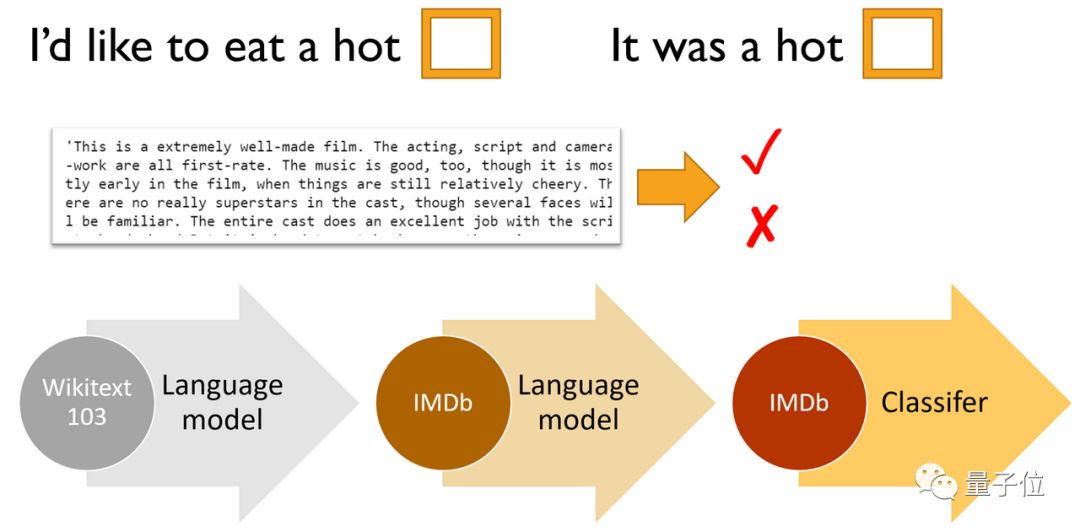
创建情绪分析模型的基本步骤是:
1、创建语言模型,在大型语料库(例如维基百科)上训练,这里的“语言模型”是学习预测句子的下一个单词的任何模型
2、使用目标语料库(IMDb电影评论)微调此语言模型
3、删除这个微调语言模型中的编码器,并用分类器替换它。然后,针对最终的分类任务微调这个情绪分析模型。
在进入NLP学习之后,我们将通过覆盖表格数据以及协同过滤来完成编码器深度学习的实际应用。
对于表格数据,我们将看到如何使用分类变量和连续变量,以及如何使用fastai.tabular模块来设置和训练模型。
然后,我们将看到如何使用类似于表格数据的想法来构建协同过滤模型。
在进入NLP学习之后,我们将通过覆盖表格数据以及协同过滤来完成编码器深度学习的实际应用。
对于表格数据,我们将看到如何使用分类变量和连续变量,以及如何使用fastai.tabular模块来设置和训练模型。
然后,我们将看到如何使用类似于表格数据的想法来构建协同过滤模型。
进入课程的中段,我们已经研究了如何在每个关键应用领域中创建和解释模型。在课程的后半部分,我们将了解这些模型是如何工作的,以及如何从头开始创建它们。
下面,我们将接触到以下概念:
激活
参数
图层
损失函数
第五课:反向传播、加速SGD、从头开始搭神经网络
在第5课中,我们将所有训练组合在一起,以便准确理解反向传播时发生了什么,并利用这些知识从头开始创建和训练一个简单的神经网络。
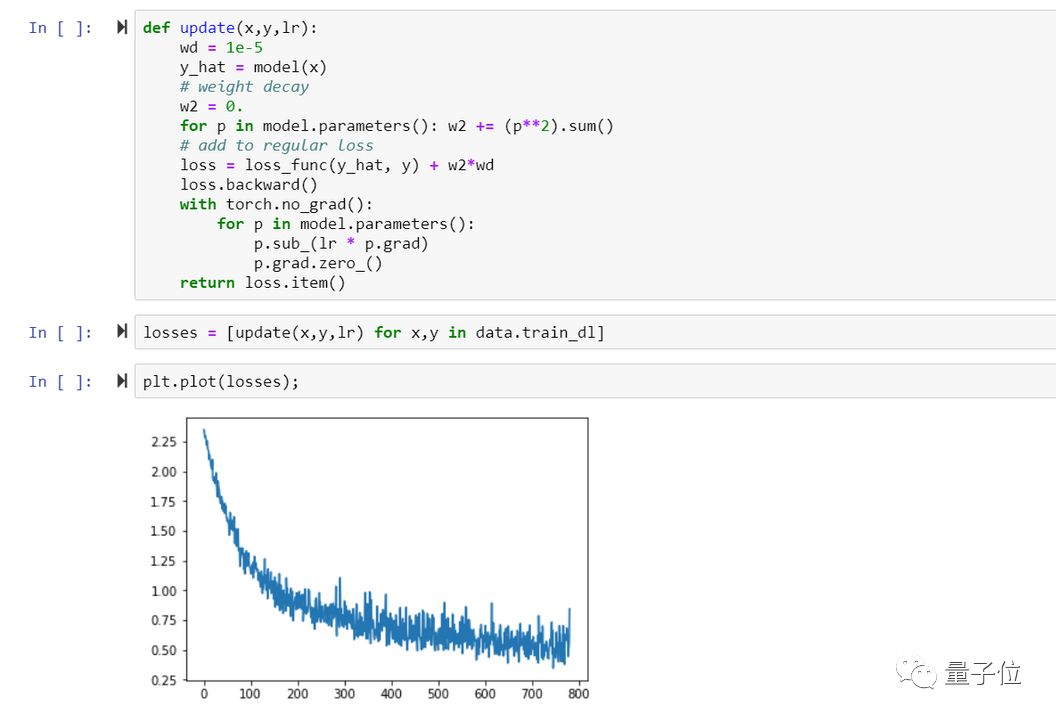
△ 从头开始训练的神经网络
我们还将看到如何查看嵌入层的权重,以找出电影评论解读模型对从分类变量中学到了什么,让我们避开那些烂片。
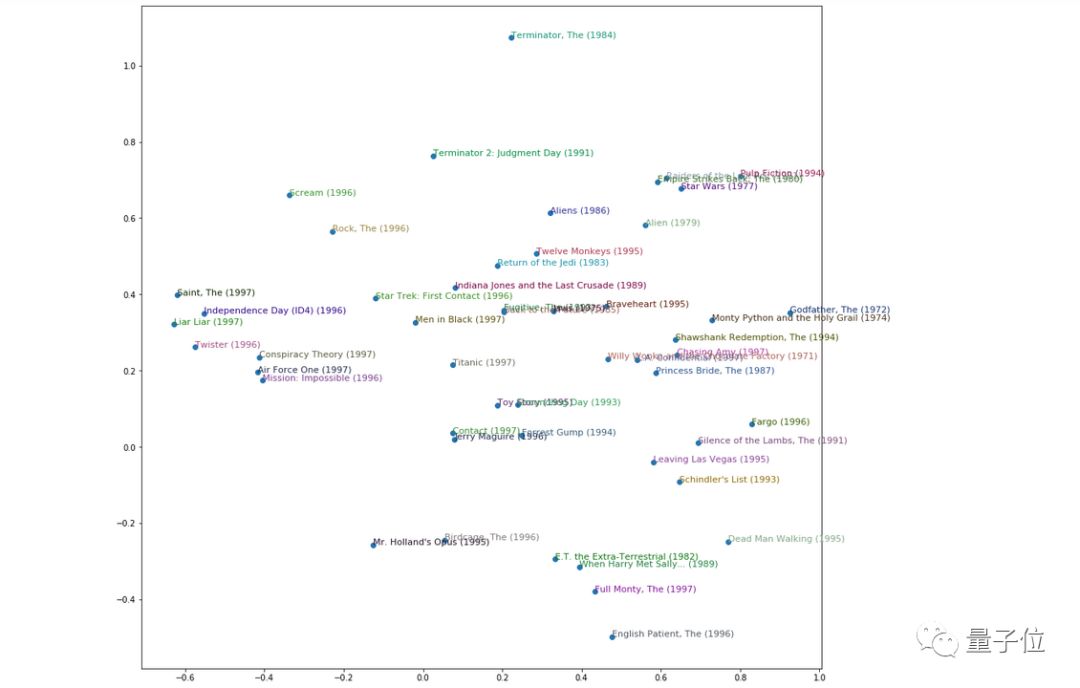
尽管嵌入在NLP的单词嵌入环境中最为广为人知,但它们对于一般的分类变量也同样重要,例如表格数据或协同过滤。它们甚至可以与非神经模型一起使用,并取得了巨大成功。
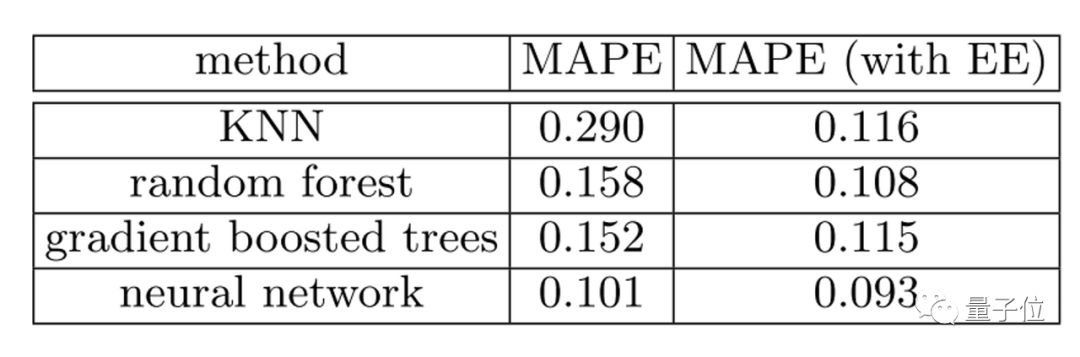
△ 常见的有嵌入和无嵌入模型性能比较
第六课:正规化、卷积、数据伦理
这节课将讨论一些改进训练和避免过度拟合的强大技术:
Dropout:在训练期间随机删除激活,使模型正规化
数据增强:在训练期间修改模型输入,有效地增加数据大小
批量标准化:调整模型的参数化,使损失表面更平滑。

△ 单个图像的数据增强示例
接下来,我们将学习卷积的所有知识,卷积可以被认为是矩阵乘法的一种变型,并且是现代计算机视觉模型的核心。
我们将利用这些知识创建一个类激活图,这是一个热图,显示图像的哪些部分在做出预测时最重要。
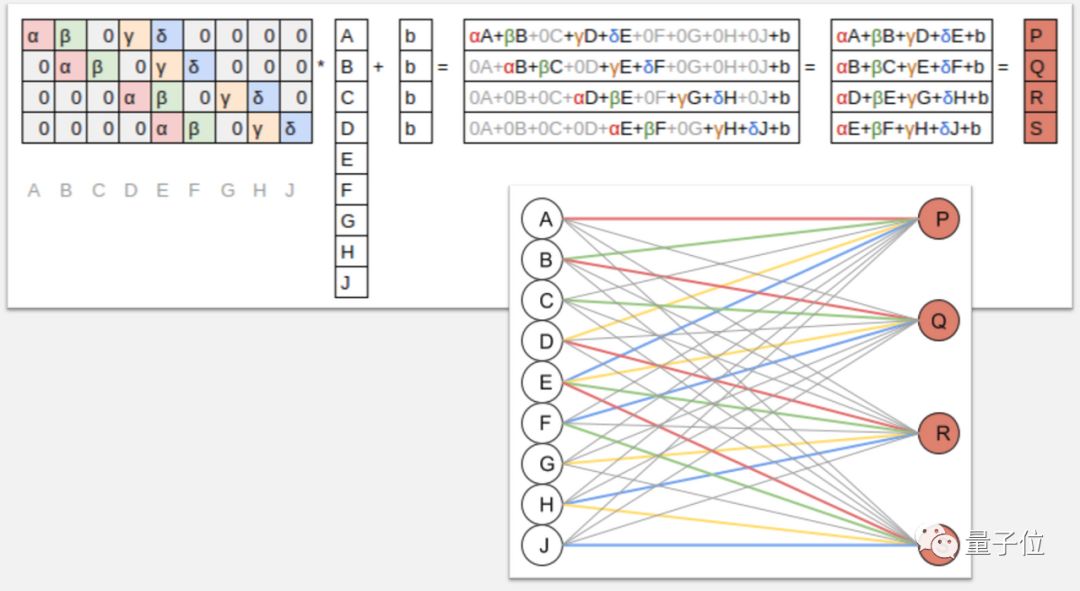
△ 卷积如何运作
最后,我们将讨论一个许多学生告诉我们的主题,这是课程中最有趣也是最令人惊讶的部分:数据伦理。
我们将了解模型可能出错的一些方式,特别关注反馈回路、它们导致问题的原因以及如何避免这些问题。
我们还将研究数据偏差会导致算法偏差的方式,并讨论数据科学家可以也应该提出的问题,以帮助确保他们的工作不会导致意外的负面结果。

△ 美国司法系统中算法出现偏差的例子
第七课:从头构建ResNet和U-Net、生成(对抗)网络
最后一节课了,要学习的第一项内容也是“现代架构中最重要的技术之一”:跳跃连接。
关于跳跃连接,这节课会讲到ResNet和U-Net架构。
ResNet是跳跃连接最知名的应用,整套课程讲图像识别时也是从头到尾都在用ResNet。
而U-Net用的是另一种跳跃连接,它的作用是优化分割结果,以及其他输出和输入结构差不多的任务。
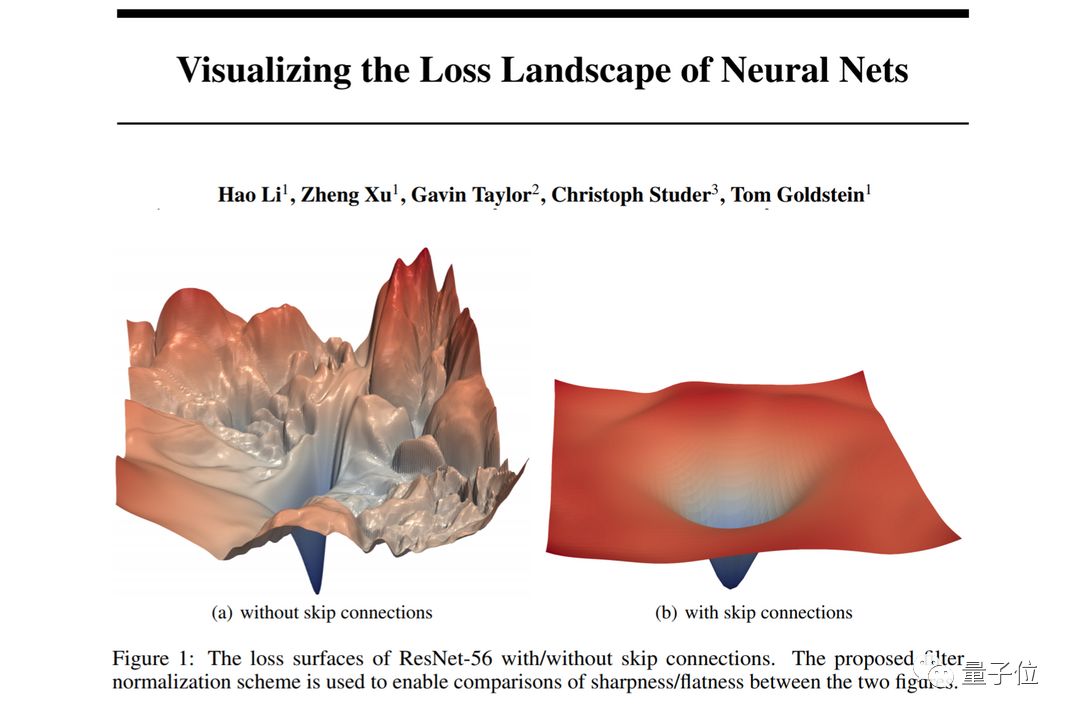
△ ResNet跳跃连接对损失表面的影响
学习了U-Net之后,就要用它训练一个超分辨率模型。这个模型不仅能把渣图变清晰,同时还能清除jpeg图片上的伪迹和文字水印。
为了让模型结果更好,这节课还会带着学生们结合特征损失(feature loss,或者叫感知损失perceptual loss)和gram损失,创建自定义的损失函数。这是图像上色等生成任务中常用的技术。

△ 用特征损失和gram损失得到的超分辨率结果
接下来,就要学习GAN里使用的生成对抗损失了,有些情况下它能牺牲一些速度,增强生成模型的质量。
这节课展示的一些技术来自未发表的研究,包括:
用迁移学习更快更可靠地训练GAN;
将架构创新和损失函数以前所未有的方式结合。
Jeremy在课程介绍中保证:结果惊艳,训练只需几小时,再也不用像以前一样花上好几天。
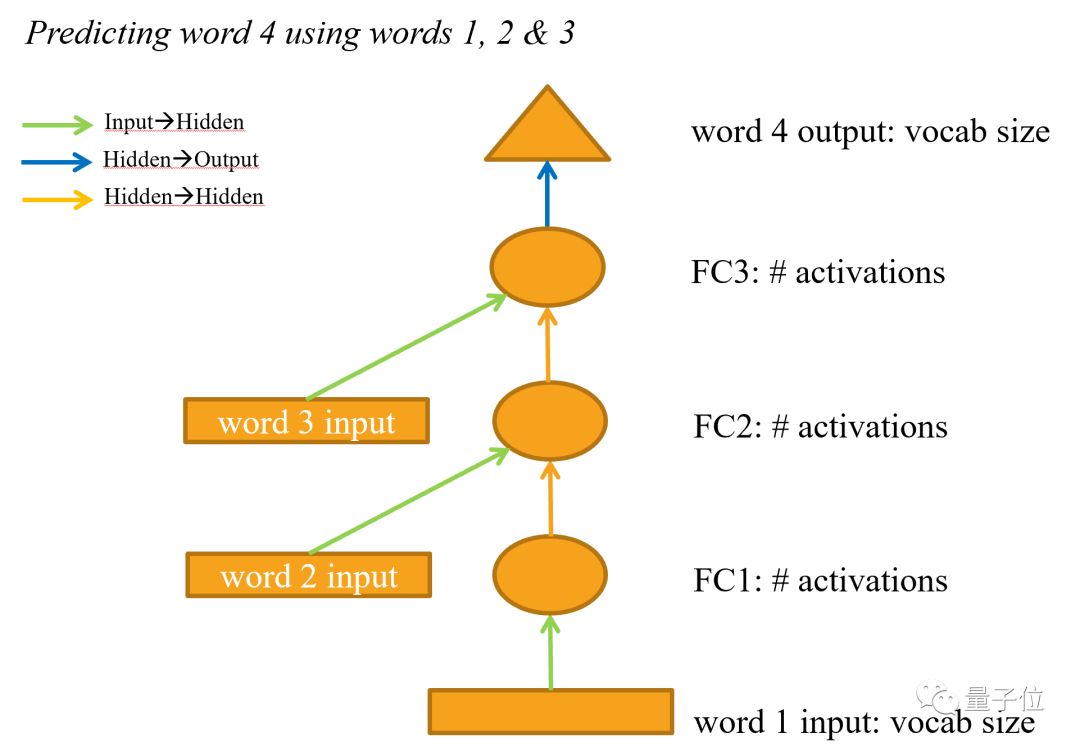
△ 一个循环神经网络
最后,这节课还要教你从头开始构建一个循环神经网络,也就是整套课程NLP内容都在用的基础模型。实际上,RNN是规则的多层神经网络的一个简单重构。
嫌吴恩达老气的另类“慈善机构”
这门课背后的fast.ai,在深度学习界算是独树一帜。
fast.ai由Kaggle大神Jeremy Howard、后悔读了博的数学博士Rachel Thomas、原本在巴黎教了7年书的Sylvain Gugger联合创办。
他们是真正的实践派,课程以“教实用的东西、高效解决问题”为核心追求,非常重视工程实现细节。
在去年发布更基础的“程序员的机器学习入门”课程(Introduction to Machine Learning for Codes)时,他们赞扬了吴恩达老师的入门课worderful之后就接了个“但是”:但是,它现在有显得太老气了,特别是作业还得拿Matlab写。
fast.ai的课程就非常紧跟程序员的实践潮流,用Python编程,用交互式的Jupyter Notebooks学习。
同时,他们也非常鼓励学生去参加Kaggle竞赛,检验自己的能力。
fast.ai不仅课程内容上新潮,还堪称“慈善组织”:
课程全都免费,连个“收费领取证书”的设定都没有。
Jeremy曾经说:“我们的商业模式就是:花自己个人的钱做点事情,帮人使用深度学习。”有人担心“商业模式”不可持续的时候,Jeremy还硬怼了回去:
Why not?我有足够的钱。
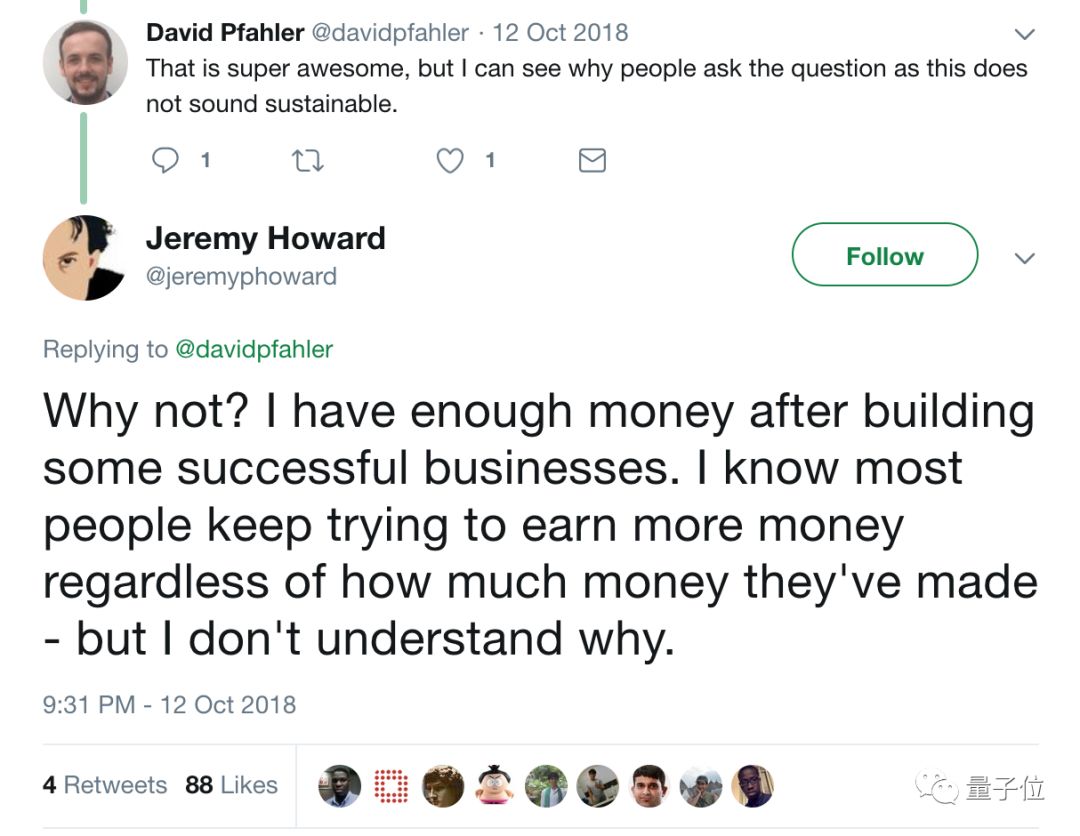
“完全独立,连捐款都不收”的fast.ai积攒了大量“自来水”。
学生们经常总结、分享课程经验。比如说,曾经学生总结了“称霸Kaggle的十大深度学习技巧”,广为流传。
写笔记总结经验还不是自来水的最高级形态,自古以来,“为母校争光”都是要做出新成就的。
fast.ai的学生Andrew Shaw就做到了。他和Jeremy老师、美国国防部的Yaroslav Bulatov就一起实现了低成本18分钟训练完ImageNet。
和那些大厂的“X分钟训练完ImageNet”不一样,他们的方法并没有堆积计算资源,用的云服务器成本还不到300块,称得上人人可用。
这个另类机构的其他成就还有:
配合PyTorch使用,一个API包揽常见深度学习应用的库:fastai;
https://docs.fast.ai/打响NLP迁移学习狂欢第一枪的ULMFiT;
http://nlp.fast.ai/category/classification.html
One More Thing
如果你达到了这门课的基本要求,有一年编程经验和高中数学基础,那么,挡在你和它之间的,可能就只剩一大障碍了:
英语。
这事儿靠自身努力也好解决。先看看前阿里人于江水的这份程序员的英语学习指南吧,GitHub上已经5000多星了。
— 完 —
2018中国人工智能明星创业公司

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !





