IJCAI 2020 | Mucko:面向视觉问答的多层次跨模态知识推理模型


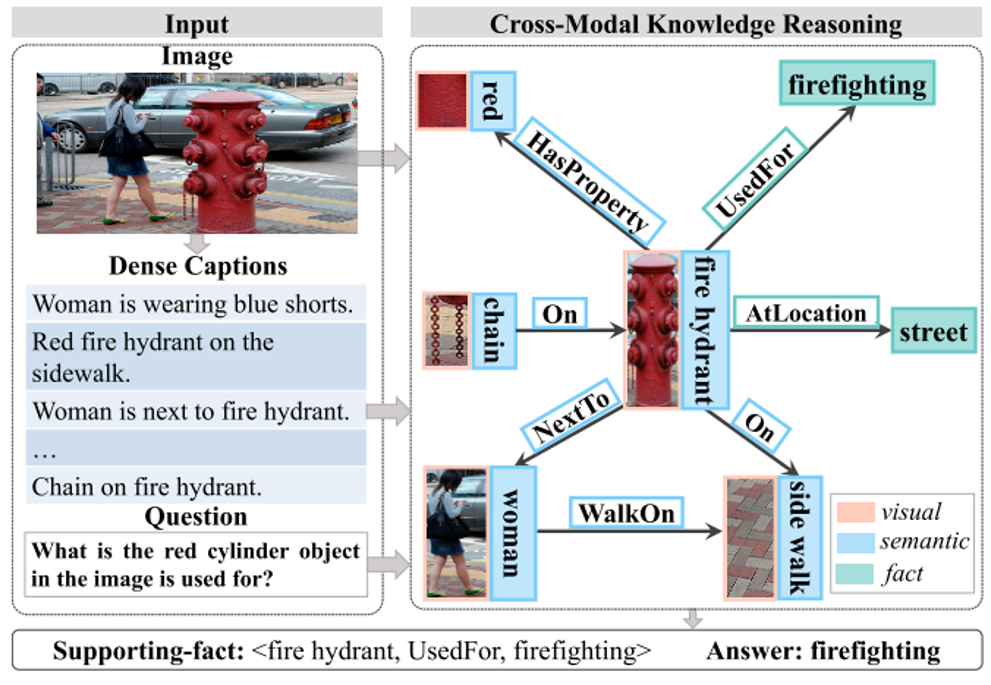
图1
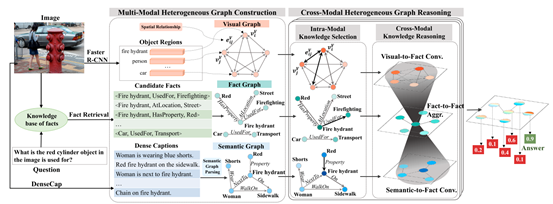
图2
1)视觉图构造
由于FVQA中的大部分问题都涉及到视觉对象及其关系,我们构建了一个全连通的视觉图,用来表示图像中物体的表层特征和关系。给定图像I,通过Faster-RCNN进行目标检测得到图像中物体的集合O,物体的数量设置成36,每个物体对应一个2048维的视觉特征v_i以及一个4维的检测框的位置信息b_i=[x_i,y_i,w_i,h_i]。在O的基础上构造视觉图G^V=(V^V,E^V),视觉图中每个节点对应着图像中检测到物体,每条边用两个物体的相对位置信息来表示。
这里之所以没有用场景图来表示。是因为我们想让模型自己学到重要的节点和边的信息。如果用场景图的话就会丢失掉对这个问题有用的视觉和关系信息。节点v_i^V用物体的视觉特征表示,边用5维的物体相对位置信息表示, r_ij^V=[(x_j-x_i)/w_i,(y_j-y_i)/h_i,w_j/w_i,h_j/h_i,w_jh_j/w_ih_i]。
2)语义图构造
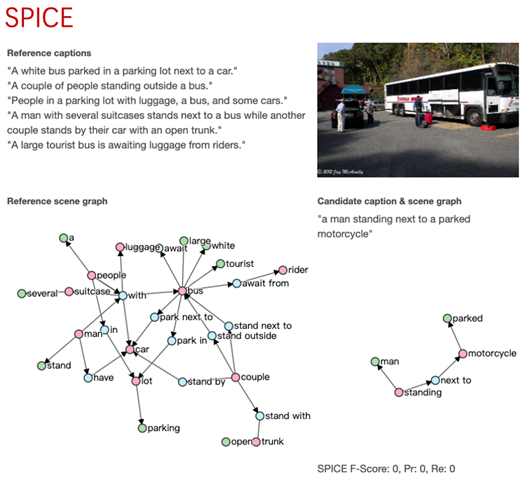
图3
3)事实图构造
2、模态内知识选择
1)Question-guided Node Attention
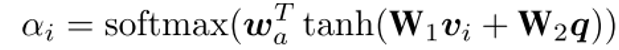
2)Question-guided Edge Attention
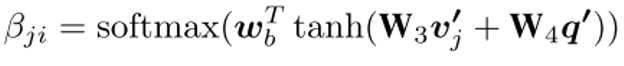
3)Intra-Modal Graph Convolution
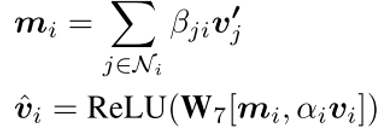
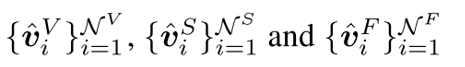
3、跨模态知识推理
1)Visual-to-Fact Convolution
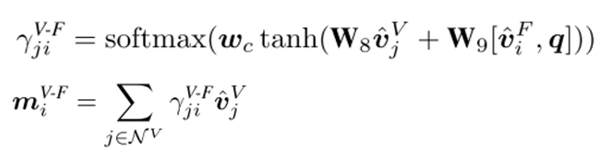
2)Semantic-to-Fact Convolution
同理可以得到语义的互补信息。
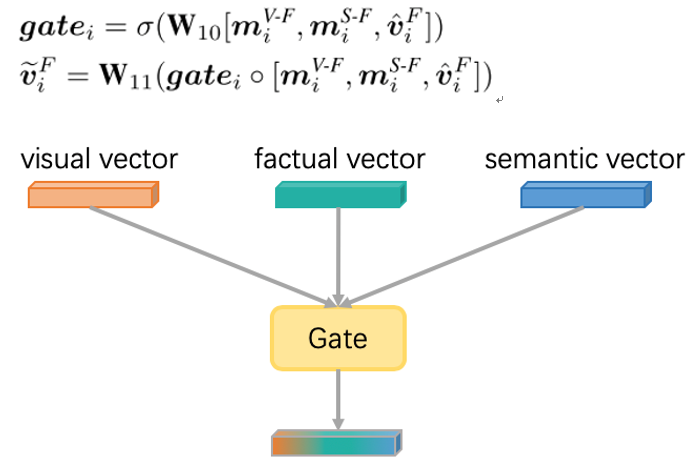
3)Fact-to-Fact Aggregation
4、学习
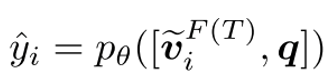
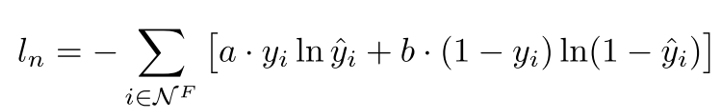
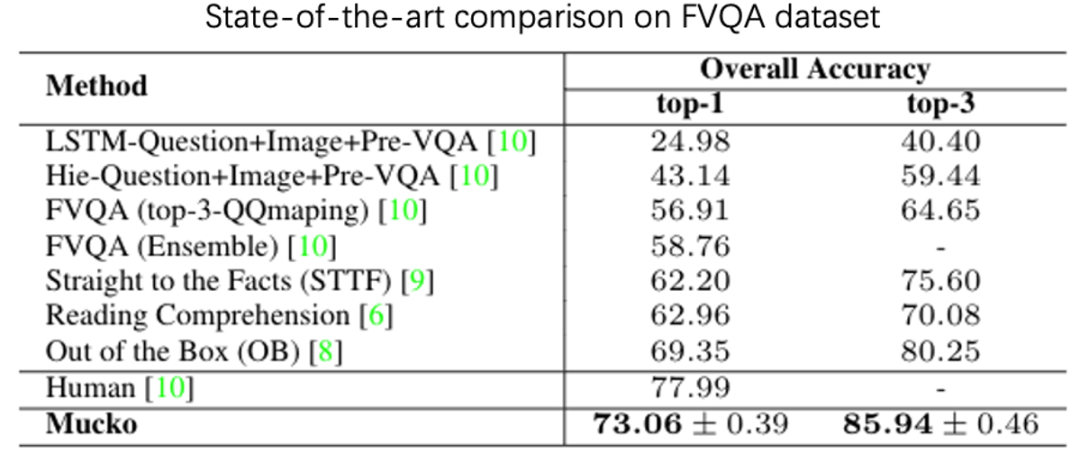
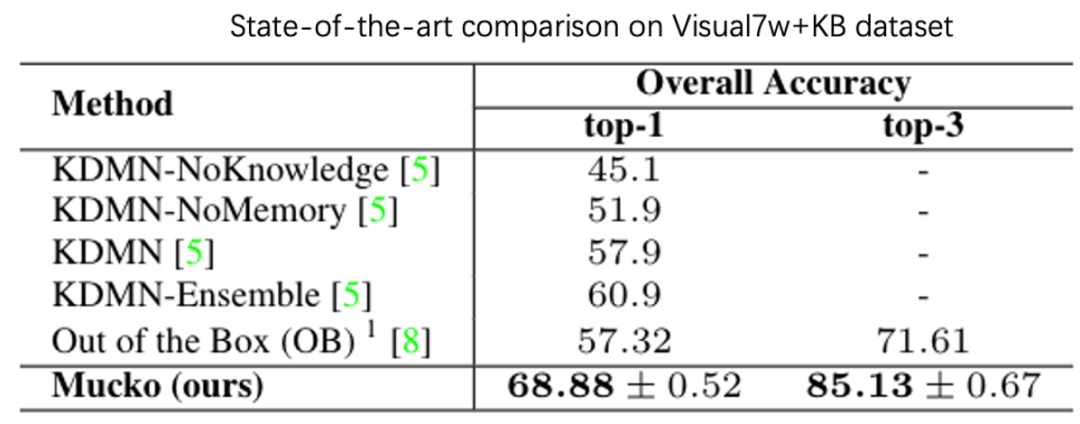

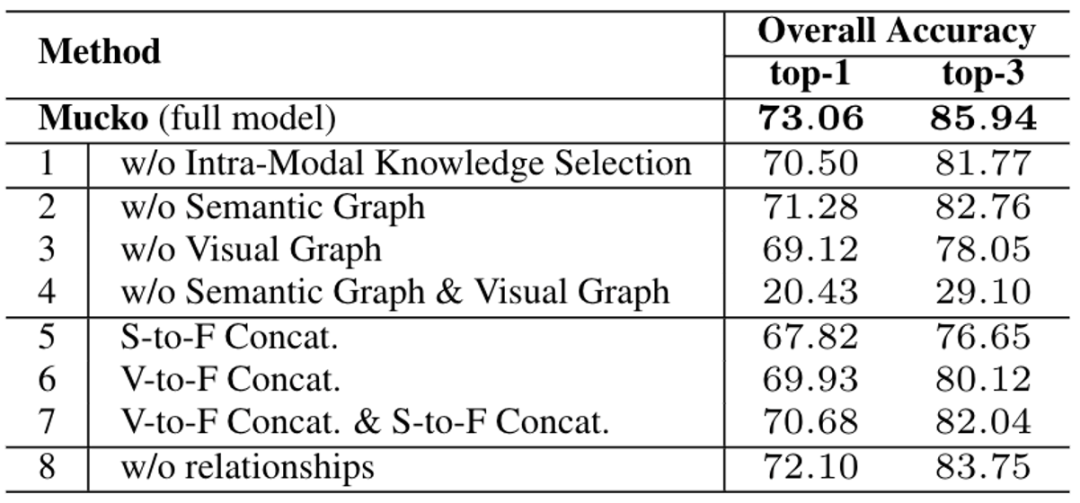
2、消融实验
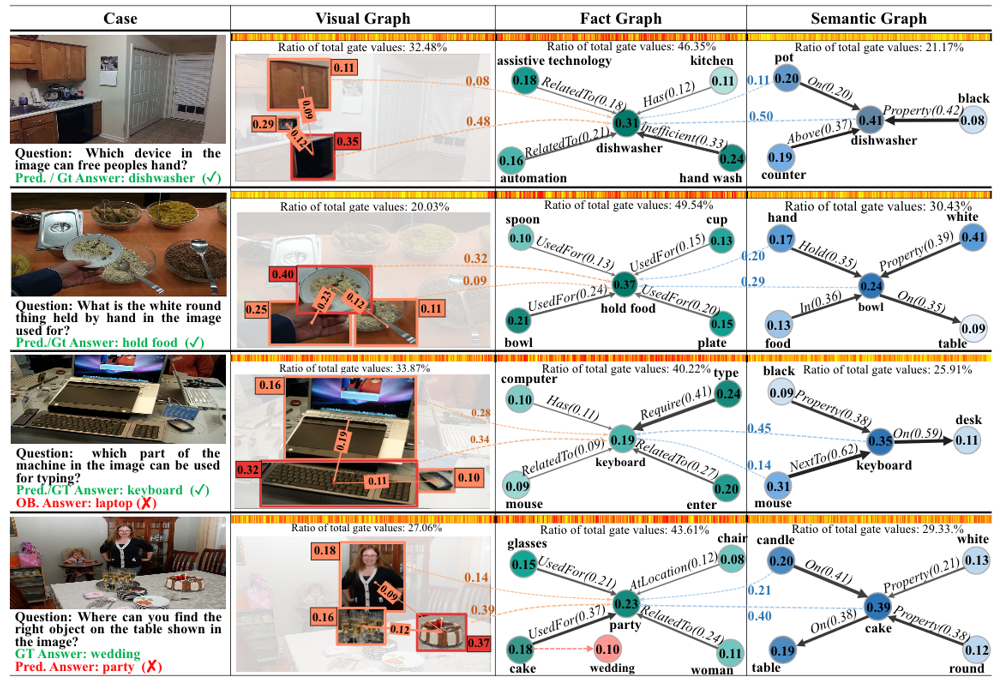
3、可视化


登录查看更多
相关内容

视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻译为中文:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是给定的图片进行问答。
专知会员服务
59+阅读 · 2020年6月30日
Arxiv
3+阅读 · 2019年1月3日
Arxiv
4+阅读 · 2018年8月29日
Arxiv
8+阅读 · 2018年2月6日
Arxiv
9+阅读 · 2018年1月27日


相关VIP内容
专知会员服务
59+阅读 · 2020年6月30日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年1月3日
Arxiv
4+阅读 · 2018年8月29日
Arxiv
8+阅读 · 2018年2月6日
Arxiv
9+阅读 · 2018年1月27日