一个新的 TensorFlow Lite 示例应用:棋盘游戏


发布人:TensorFlow 技术推广工程师 魏巍
开发人员经常通过游戏来测试各种强化学习 (RL) 算法。我们很高兴看到机器学习研究人员发明新的 RL 算法来解决游戏方面的难题,与此同时,我们也对游戏开发者通过 RL 在 TensorFlow 中构建游戏机器人来实现各种目的感到好奇,其中包括质量测试、游戏平衡调整和游戏难度评估。
强化学习
https://developers.google.cn/machine-learning/glossary/rl#reinforcement-learning-rl
我们已有一个详细的教程,演示如何用 TensorFlow 为传统的 CartPole Gym 环境实现 actor-critic RL 方法。在这次的端到端教程中,我们将展示如何使用 TensorFlow、TensorFlow Agents 和 TensorFlow Lite 来构建游戏 agent,在小型棋盘游戏应用中与真人用户进行对抗。最终生成如下图所示的 Android 参考应用,其代码已经在 tensorflow/examples 代码库中开放,供您参考。
教程
https://tensorflow.google.cn/tutorials/reinforcement_learning/actor_critic
tensorflow/examples
https://github.com/tensorflow/examples/tree/master/lite/examples/reinforcement_learning
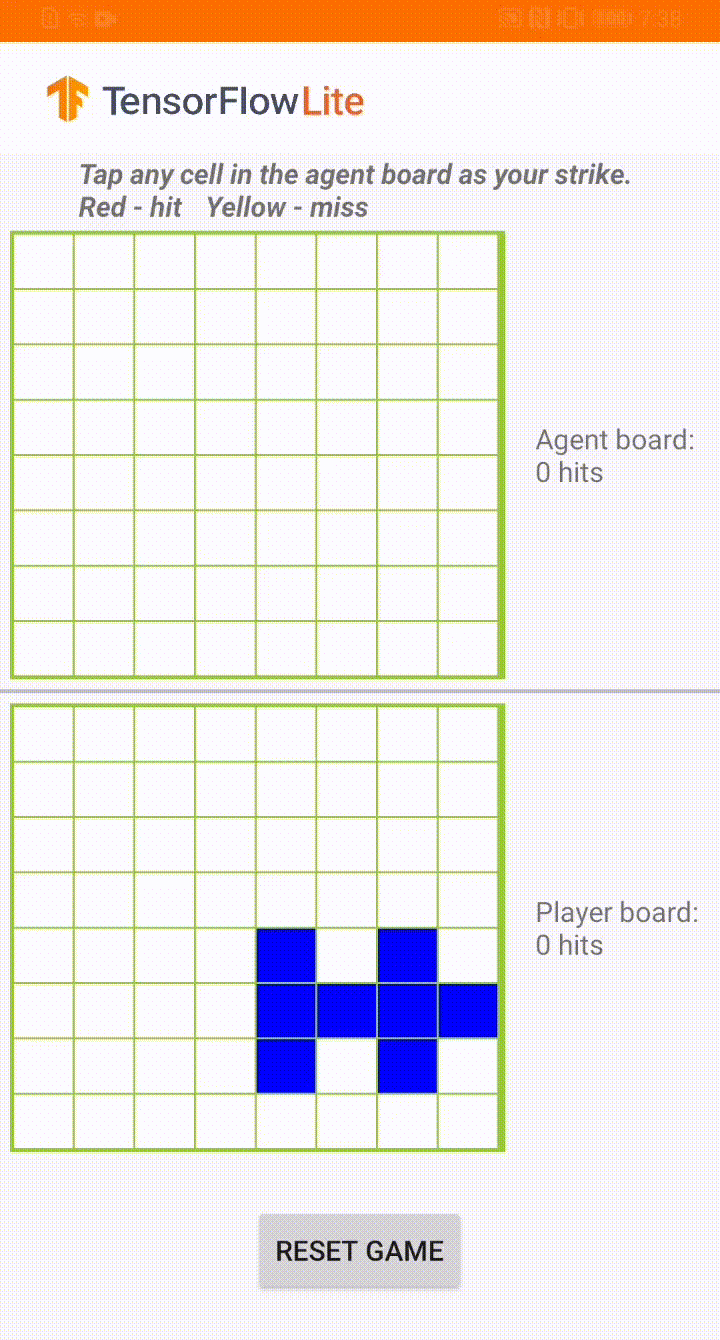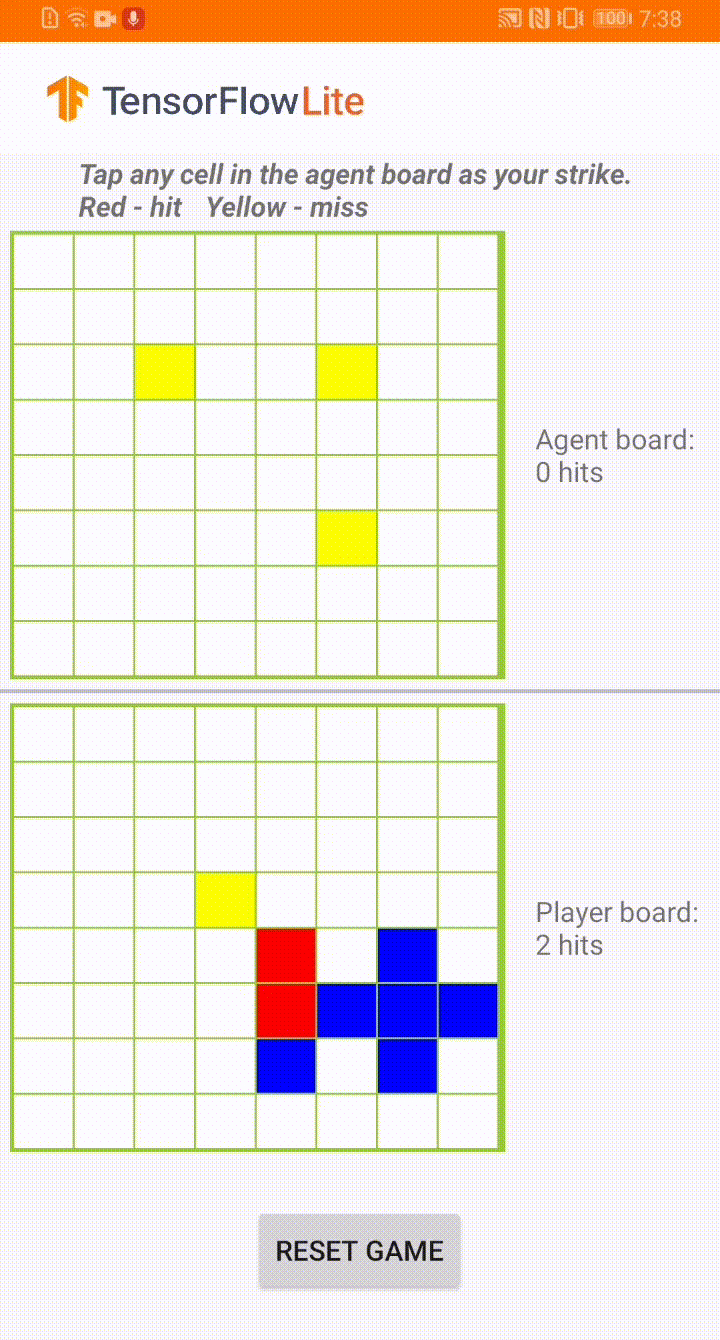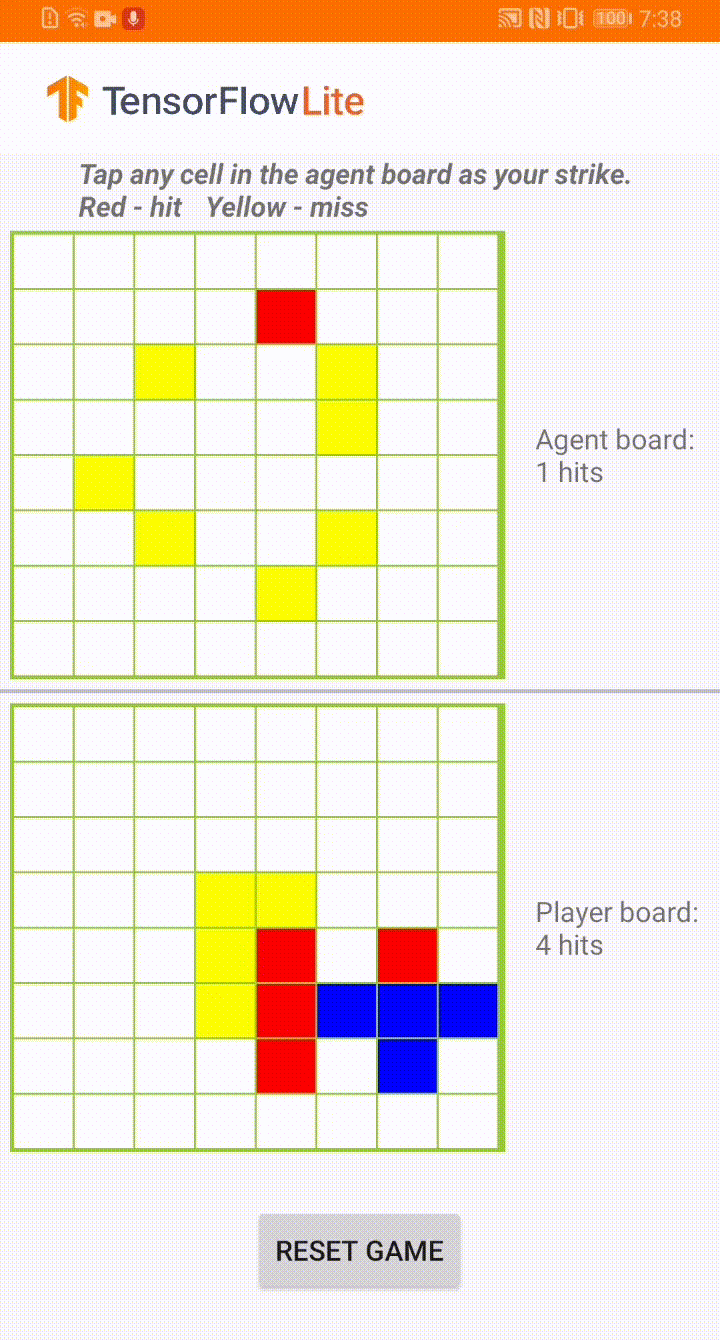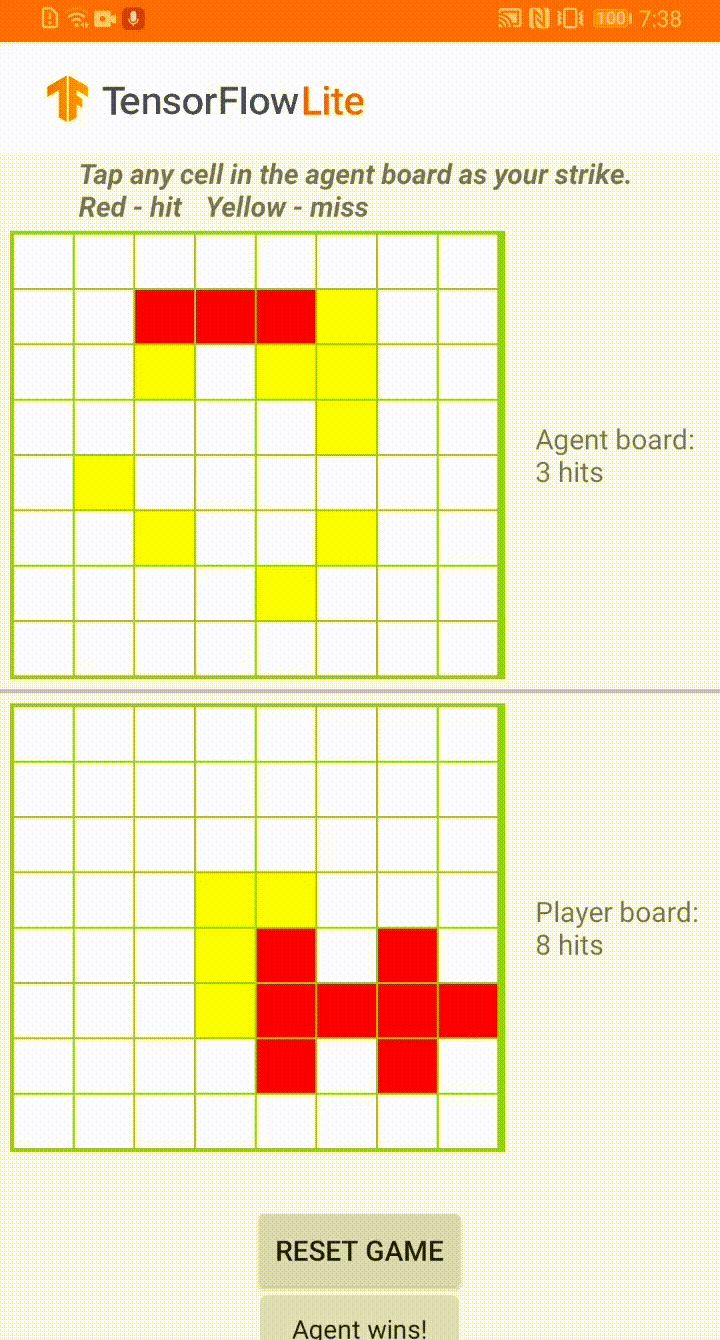
Plane Strike 游戏演示
这款游戏名为 Plane Strike,是一款类似于棋盘游戏 Battleship 的小型棋盘游戏。规则非常简单:
与在游戏开始时,用户和 agent 在自己的棋盘上各有一个“飞机”对象(如上方动图所示,8 个蓝色单元格组成“飞机”);这些飞机只对棋盘所有者可见,而对其对手是隐藏的。
用户和 agent 轮番攻击对方棋盘,每次攻击一个单元格。用户可以点击 agent 棋盘上的任何单元格,而 agent 将根据机器学习模型的预测自动做出选择。如果点击的单元格是组成“飞机”的单元格(“命中”),则单元格会变为红色;否则将会变成黄色(“未命中”)。
首先击中 8 个红色单元格的一方赢得比赛;然后刷新棋盘,重新开始游戏。
虽然可以为此类小游戏手动创建规则,但我们还是通过强化学习创建了真人玩家无法轻易击败的智能 agent。有关强化学习概述,请参考来自 DeepMind 和 UCL 的 RL 课程。
来自 DeepMind 和 UCL 的 RL 课程
https://deepmind.com/learning-resources/reinforcement-learning-series-2021
我们为此游戏应用提供了 2 种训练和部署的途径。


若要通过这种方式训练 agent,我们首先要创建一个自定义的 OpenAI Gym 环境“PlaneStrike-v0”,该环境可以帮助我们轻松地发布游戏玩法并收集游戏日志。然后通过 reward-to-go 策略梯度算法来训练 agent。REINFORCE 是 RL 中的一种策略梯度算法。该算法的基本理念是根据游戏过程中收集到的奖励信号来调整策略网络参数,让策略网络在未来的游戏中能够实现最大的返回值。
OpenAI Gym
https://gym.openai.com/
PlaneStrike-v0
https://github.com/tensorflow/examples/blob/master/lite/examples/reinforcement_learning/ml/tf_and_jax/gym_planestrike/gym_planestrike/envs/planestrike.py
策略梯度
http://rail.eecs.berkeley.edu/deeprlcourse/static/slides/lec-5.pdf
在数学层面上,策略梯度的定义为:
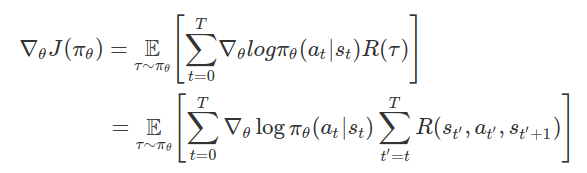
其中:
T:每段的时步数,各段的时步数可能有所不同
st:时步上的状态 t
at:时步上的所选操作 t 指定状态 s
πθ:参数为 θ 的策略
R(*):在指定策略下,收集到的奖励
请参考有关策略梯度的 DeepMind 讲座,了解相关细节讨论。为通过 TensorFlow 实现策略梯度,我们定义了一个简单的 3 层 MLP 作为策略网络,并根据真人玩家棋盘的状态预测 agent 的下一个攻击位置。请注意,上述策略梯度的逻辑表达式(没有奖励部分)相当于负数交叉熵损失。在这种情况下,若要实现奖励最大化,只需让分类交叉熵损失达到最小。
有关策略梯度的 DeepMind 讲座
https://www.youtube.com/watch?v=y3oqOjHilio
model.compile(loss='sparse_categorical_crossentropy', optimizer=sgd)我们创建了一个 play_game() 函数来发布游戏并帮助收集游戏日志。每段结束后,我们通过 Keras fit() 函数训练 agent:
model.fit(x=board_log, y=action_log, sample_weight=rewards)请注意,我们将折扣的 rewards-to-go 作为“sample_weight”传入 Keras fit() 函数,作为一种实现策略梯度算法的捷径,这样我们就无需编写自定义训练循环。一种直观的理解方法是,我们需要 (x, y, reward) 元组,而不仅仅是监督学习中的 (x, y)。奖励可以为负数,从而帮助预测器的输出结果根据 x 的值移向/远离 y 值。这与监督学习不同(在监督学习中,“sample_weight”不会是负数)。
由于我们没有采用监督学习,所以不能真正使用训练损失来监测训练进度。相反,我们将使用“game_length”指标来表示 agent 完成每盘游戏所需的步数。可以用一种比较直观的方式来理解,agent 越智能,其预测能力就越高,游戏长度就越短。
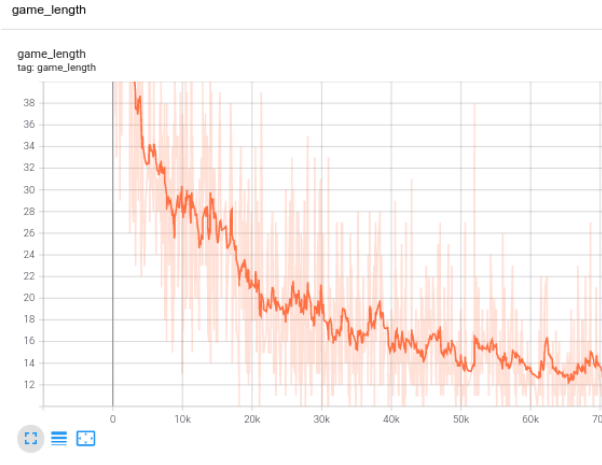
TensorBoard 中的训练进度
由于这是一个需要 agent 即时响应的游戏,我们需要将模型部署在移动设备上而不是服务器上。模型训练完成后,我们使用 TFLite 转换器将 Keras 模型转换为 TFLite 模型,并将其整合到我们的 Android 应用中。
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()导出模型的速度非常快,在 Pixel 手机上执行所需的时间甚至不到 1 毫秒。在游戏过程中,agent 在每一步时都会查看用户的棋盘位置,并预测其下一个打击位置,以期尽快击中 8 个红色单元格。
convertBoardStateToByteBuffer(board);
tflite.run(boardData, outputProbArrays);
float[] probArray = outputProbArrays[0];
int agentStrikePosition = -1;
float maxProb = 0;
for (int i = 0; i < probArray.length; i++) {
int x = i / Constants.BOARD_SIZE;
int y = i % Constants.BOARD_SIZE;
if (board[x][y] == BoardCellStatus.UNTRIED && probArray[i] > maxProb) {
agentStrikePosition = i;
maxProb = probArray[i];
}
}使用 TensorFlow API 从零开始编写 agent,这种方式虽好,但最好还是利用现有的 RL 算法实现。TensorFlow Agents 是一个基于 TensorFlow 的强化学习的库,该库提供可修改、可扩展,且经过精心测试的模块组件,让设计、实现和测试新 RL 算法变得更加简单。TF agent 已经实现了几种最先进的 RL 算法,包括 DQN、DDPG、REINFORCE、PPO、SAC 和 TD3。经 TF agent 训练的策略可以直接转换为 TFLite 并部署到移动应用中(注意,此特征刚于近期启用,需要使用 TensorFlow 和 TensorFlow Agents 的 nightly 版)。
TensorFlow Agents
https://tensorflow.google.cn/agents
转换为 TFLite
https://tensorflow.google.cn/agents/tutorials/10_checkpointer_policysaver_tutorial#convert_policy_to_tflite
我们使用 TF Agents REINFORCE agent 来训练我们的 agent。首先,我们需要定义 TF Agents 的训练环境,如同在上一节中定义 Gym 环境。然后,我们可以定义一个行动网络作为策略网络。
REINFORCE agent
https://tensorflow.google.cn/agents/tutorials/6_reinforce_tutorial
训练环境
https://github.com/tensorflow/examples/blob/master/lite/examples/reinforcement_learning/ml/tf_agents/planestrike_py_environment.py
actor_net = tfa.networks.Sequential([
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation='relu'),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
], input_spec=train_py_env.observation_spec(
))我们将使用 已经实现内置的 TF Agents REINFORCE agent。构建该 agent 的基础是上述定义的“actor_net”:
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)为了训练 agent,我们需要收集一些轨迹作为经验。我们使用 DeepMind Reverb 和 TF Agents PyDriver 定义了一个专门用于此的函数:
DeepMind Reverb
https://github.com/deepmind/reverb
PyDriver
https://tensorflow.google.cn/agents/tutorials/4_drivers_tutorial#python_drivers
def collect_episode(environment, policy, num_episodes, replay_buffer_observer):
"""Collect game episode trajectories."""
initial_time_step = environment.reset()
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(policy, use_tf_function=True),
[replay_buffer_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)现在就可以训练模型了:
for i in range(iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(train_py_env, collect_policy,
COLLECT_EPISODES_PER_ITERATION, replay_buffer_observer)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()您可以使用 TensorBoard 来监控训练进度。在这种情况下,我们对平均段长和平均返回值都进行了可视化。
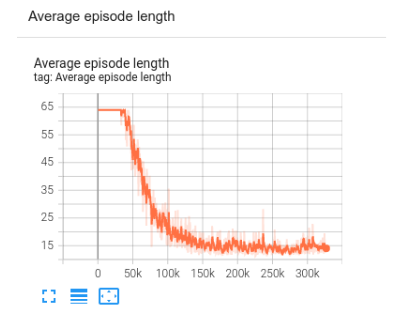
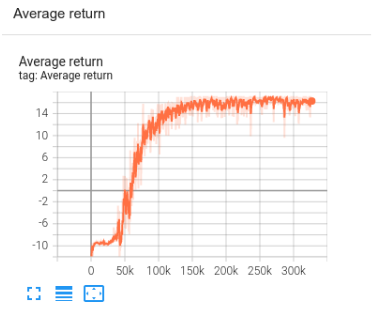
TensorBoard 中 TF agent 的训练进度
训练策略并将其作为 SavedModel 导出之后,您就可以将其转换为 TFLite 模型:
converter = tf.lite.TFLiteConverter.from_saved_model(
policy_dir, signature_keys=['action'])
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TensorFlow Lite ops.
tf.lite.OpsSet.SELECT_TF_OPS # enable TensorFlow ops.
]
tflite_policy = converter.convert()
with open(os.path.join(model_dir, 'planestrike_tf_agents.tflite'), 'wb') as f:
f.write(tflite_policy)目前,在转换过程中需要一些 TensorFlow 算子。转换后的模型与直接使用 TensorFlow 训练的模型略有不同,因为转换后的模型需要 4 个张量作为输入。其中“observation”张量至关重要。agent 将会查看此“观察”张量并预测其下一步行动。在推断时,忽略其他 3 个张量不会造成风险。
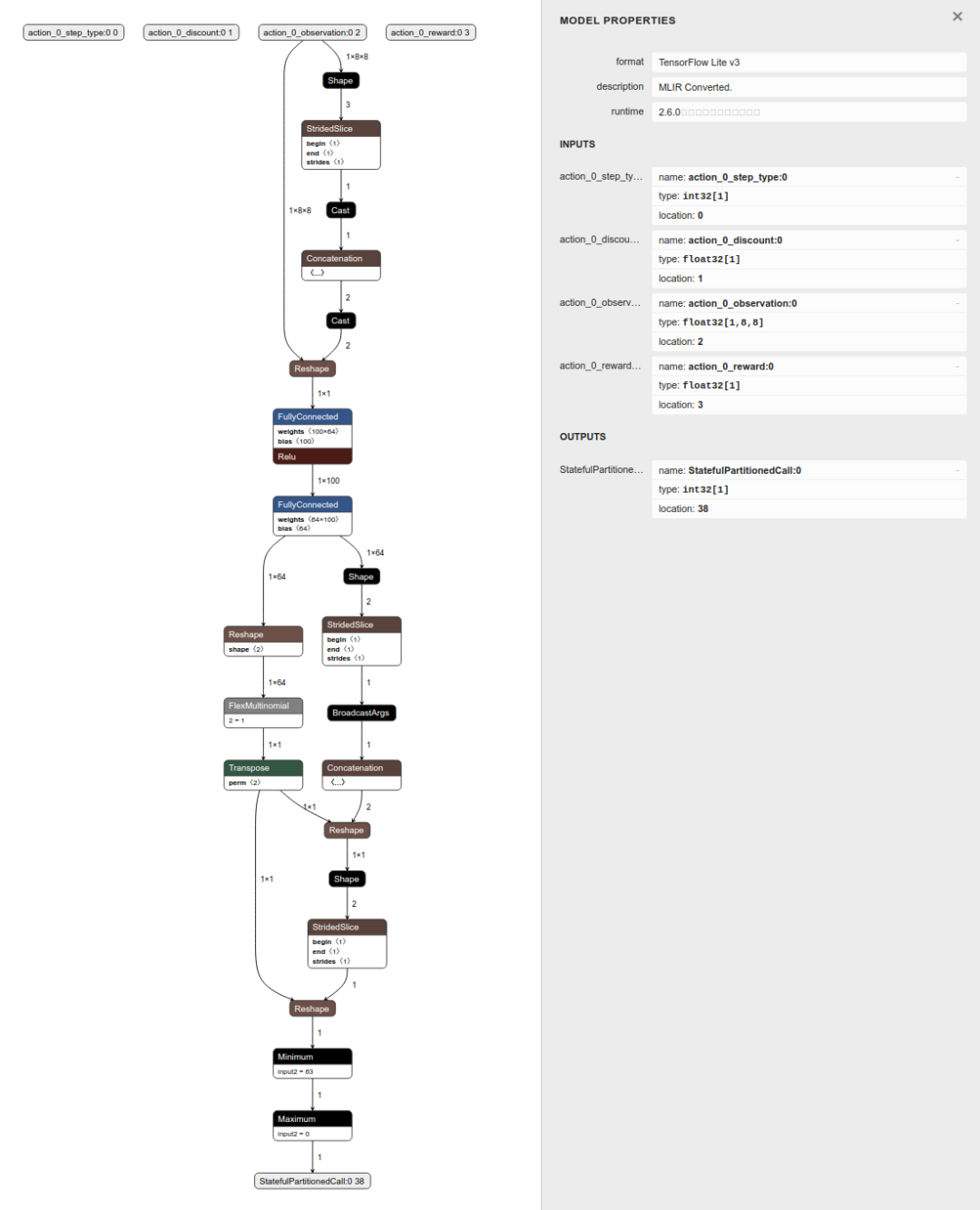
使用 Netron 对 TF Agents 转换的 TFLite 模型进行可视化
除此之外,模型还会直接输出攻击位置而不是概率分布,因此我们不再需要手动执行 argmax。
@Override
protected void runInference() {
Map output = new HashMap<>();
// TF Agent directly returns the predicted action
int[][] prediction = new int[1][1];
output.put(0, prediction);
tflite.runForMultipleInputsOutputs(inputs, output);
agentStrikePosition = prediction[0][0];以上,我们向您展示了 2 种途径,帮助了解如何训练游戏 agent、将训练后的模型转换为 TFLite 并将其部署到 Android 应用。希望此端到端的教程可以帮助您更好地了解如何利用 TensorFlow 生态系统来构建炫酷的游戏。
最后,如果您觉得这个小游戏很有趣,可以在手机上安装该应用,看看是否可以击败我们训练的 agent 😃。
应用
https://github.com/tensorflow/examples/tree/master/lite/examples/reinforcement_learning/android

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看



