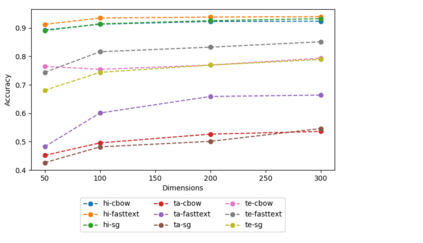
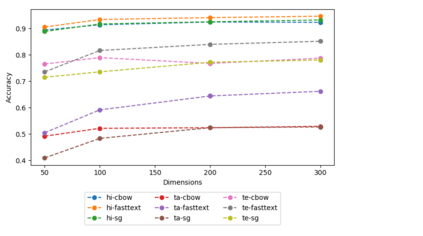
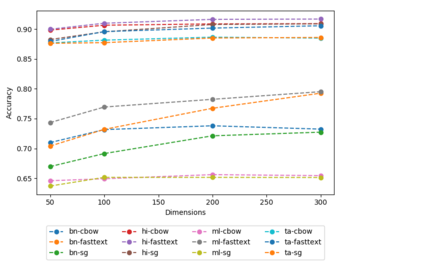
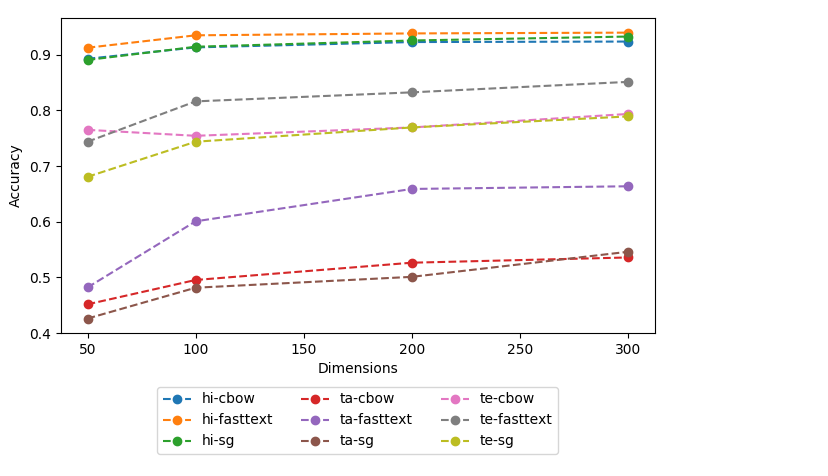
Dense word vectors or 'word embeddings' which encode semantic properties of words, have now become integral to NLP tasks like Machine Translation (MT), Question Answering (QA), Word Sense Disambiguation (WSD), and Information Retrieval (IR). In this paper, we use various existing approaches to create multiple word embeddings for 14 Indian languages. We place these embeddings for all these languages, viz., Assamese, Bengali, Gujarati, Hindi, Kannada, Konkani, Malayalam, Marathi, Nepali, Odiya, Punjabi, Sanskrit, Tamil, and Telugu in a single repository. Relatively newer approaches that emphasize catering to context (BERT, ELMo, etc.) have shown significant improvements, but require a large amount of resources to generate usable models. We release pre-trained embeddings generated using both contextual and non-contextual approaches. We also use MUSE and XLM to train cross-lingual embeddings for all pairs of the aforementioned languages. To show the efficacy of our embeddings, we evaluate our embedding models on XPOS, UPOS and NER tasks for all these languages. We release a total of 436 models using 8 different approaches. We hope they are useful for the resource-constrained Indian language NLP. The title of this paper refers to the famous novel 'A Passage to India' by E.M. Forster, published initially in 1924.
翻译:包含语言语义的刻录式文字矢量或“ 字嵌入”, 将文字的语义特性编码为语言的语义特性, 现在已经成为国家语言方案任务的组成部分, 如机器翻译、 问答、 Word Sense Disamdiguation( WSD) 和信息检索( IR) 。 在本文中, 我们使用各种现有方法为14种印度语言创建多字嵌入。 我们用各种语言, 即 Assamese、 Bengali、 Gulatati、 Indim、 Kannada、 Konkani、 Malyalalam、 Marathi、 Nepali、 Odiya、 Punjai、 Sanskrit、 Tamil 和 Telugu, 在一个单一的存储库中 。 相对新的方法, 重点是要向环境环境( BERT、 ELMo 等) 创建多语言的多词嵌入 。 我们用背景和非外语种语言来发布经过预先训练的嵌入的嵌入 。 我们还使用MUSTE 和 XLM 来培训所有上述语言的文档的交叉嵌入 。