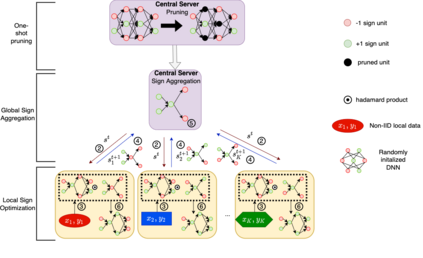
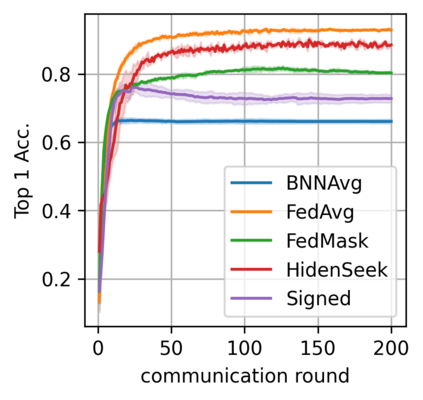
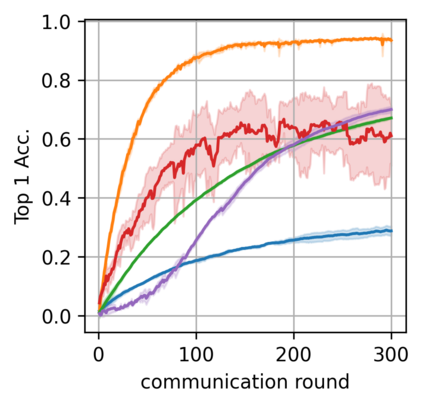
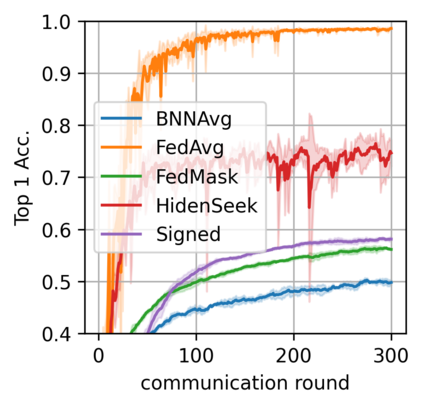
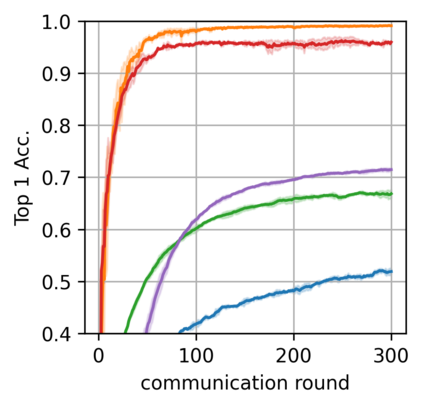
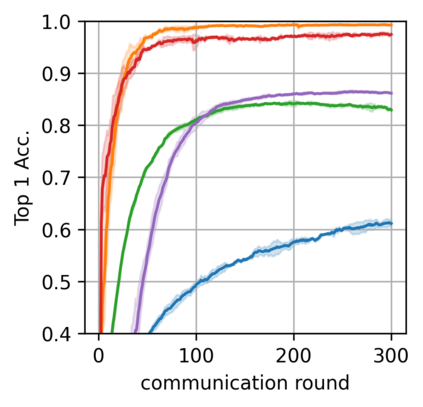
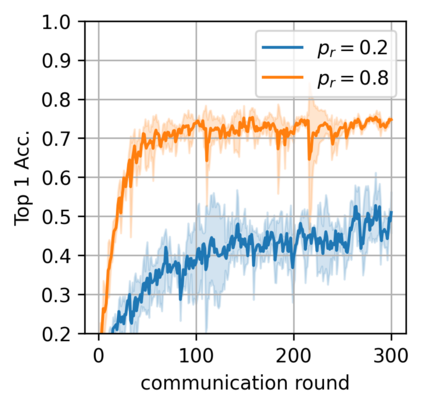
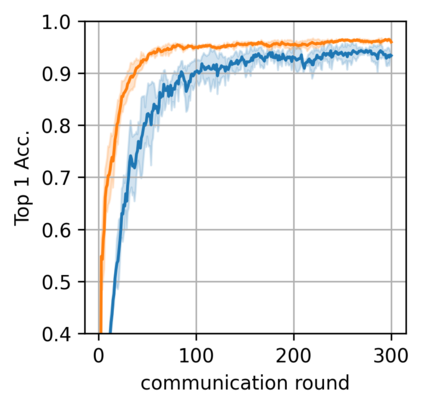
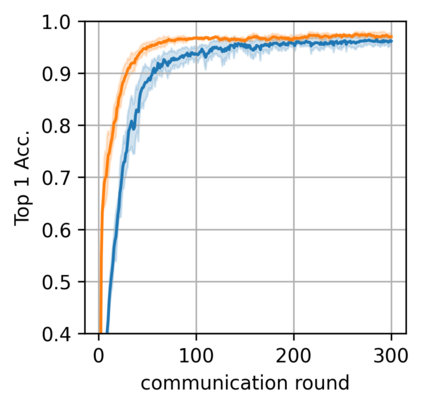
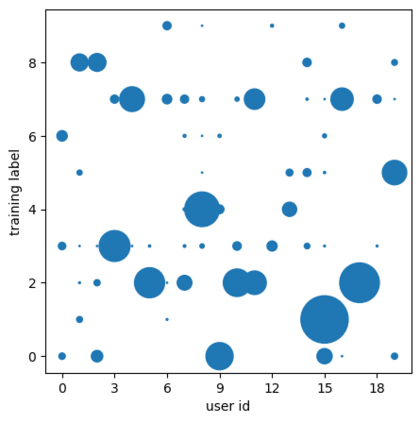
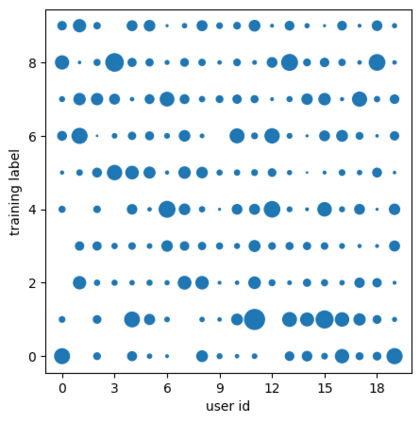
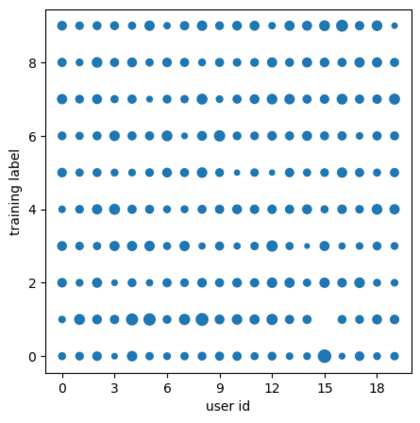
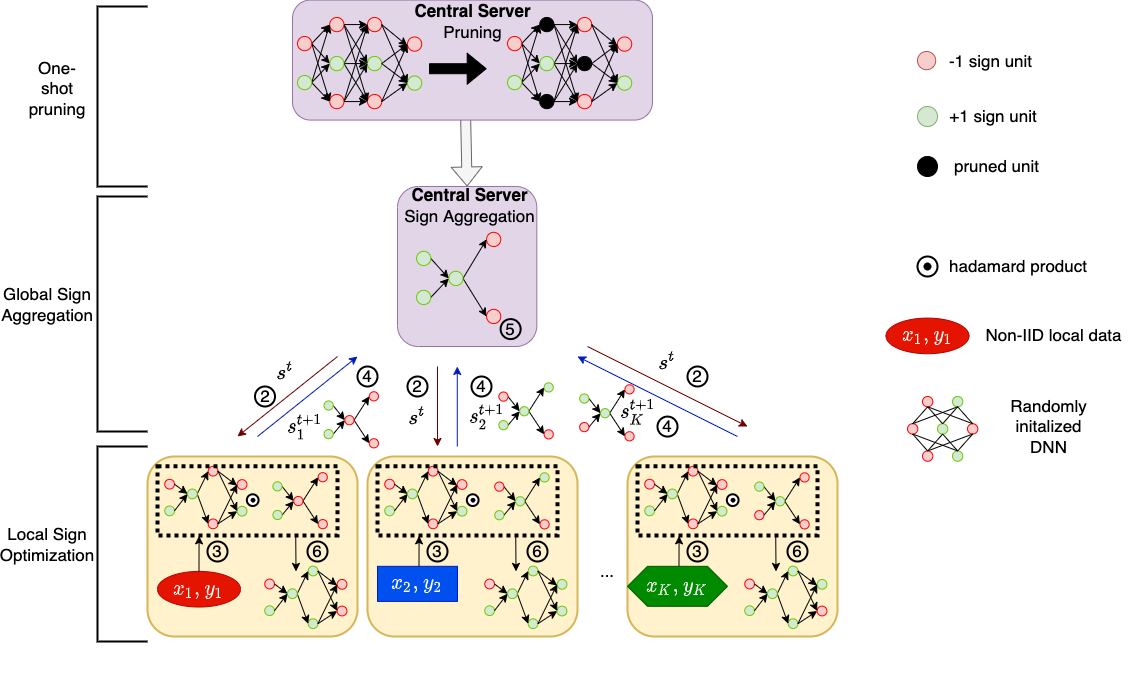
Federated learning alleviates the privacy risk in distributed learning by transmitting only the local model updates to the central server. However, it faces challenges including statistical heterogeneity of clients' datasets and resource constraints of client devices, which severely impact the training performance and user experience. Prior works have tackled these challenges by combining personalization with model compression schemes including quantization and pruning. However, the pruning is data-dependent and thus must be done on the client side which requires considerable computation cost. Moreover, the pruning normally trains a binary supermask $\in \{0, 1\}$ which significantly limits the model capacity yet with no computation benefit. Consequently, the training requires high computation cost and a long time to converge while the model performance does not pay off. In this work, we propose HideNseek which employs one-shot data-agnostic pruning at initialization to get a subnetwork based on weights' synaptic saliency. Each client then optimizes a sign supermask $\in \{-1, +1\}$ multiplied by the unpruned weights to allow faster convergence with the same compression rates as state-of-the-art. Empirical results from three datasets demonstrate that compared to state-of-the-art, HideNseek improves inferences accuracies by up to 40.6\% while reducing the communication cost and training time by up to 39.7\% and 46.8\% respectively.
翻译:联邦学习联盟通过向中央服务器发送本地模型更新来减轻分布式学习的隐私风险。然而,它面临诸多挑战,包括客户数据集的统计多样性和客户设备的资源限制,这严重影响了培训业绩和用户经验。先前的工程通过将个人化与模型压缩计划(包括量化和修剪)相结合,解决了这些挑战。然而,修剪取决于数据,因此必须在客户方面进行,这需要相当大的计算成本。此外,修剪通常只培训一个二进制超模xxxx $@in 0.0,1 $1美元,这大大限制了模型能力,但却没有计算效益。因此,培训需要很高的计算成本和很长的时间来汇合,而模型的性能却无收效。在这项工作中,我们建议HideNseek在初始化时使用一发数据-Annonocriprun,以获得一个基于重量合成特征的子网络。每个客户然后优化一个符号超模xxxxx $_1,+1,+1美元xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx