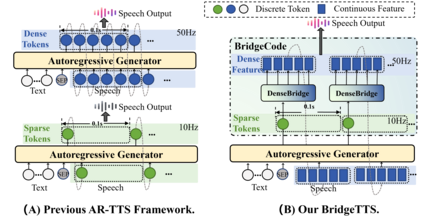
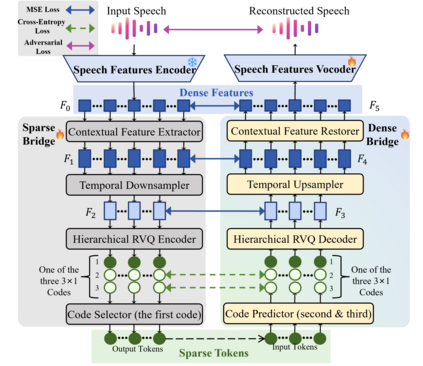
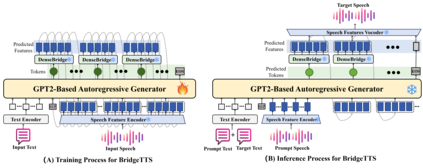
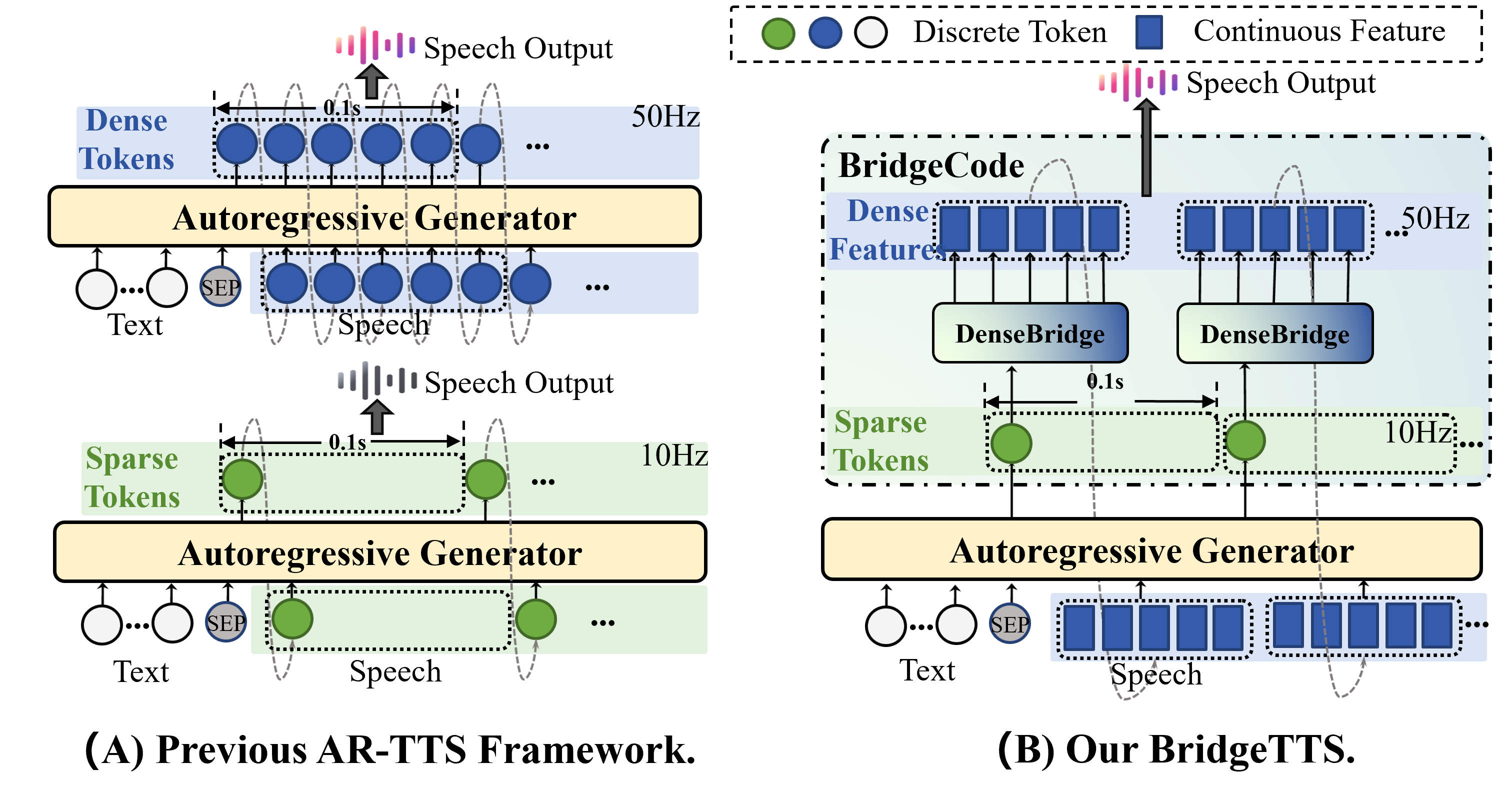
Autoregressive (AR) frameworks have recently achieved remarkable progress in zero-shot text-to-speech (TTS) by leveraging discrete speech tokens and large language model techniques. Despite their success, existing AR-based zero-shot TTS systems face two critical limitations: (i) an inherent speed-quality trade-off, as sequential token generation either reduces frame rates at the cost of expressiveness or enriches tokens at the cost of efficiency, and (ii) a text-oriented supervision mismatch, as cross-entropy loss penalizes token errors uniformly without considering the fine-grained acoustic similarity among adjacent tokens. To address these challenges, we propose BridgeTTS, a novel AR-TTS framework built upon the dual speech representation paradigm BridgeCode. BridgeTTS reduces AR iterations by predicting sparse tokens while reconstructing rich continuous features for high-quality synthesis. Joint optimization of token-level and feature-level objectives further enhances naturalness and intelligibility. Experiments demonstrate that BridgeTTS achieves competitive quality and speaker similarity while significantly accelerating synthesis. Speech demos are available at https://test1562.github.io/demo/.
翻译:暂无翻译