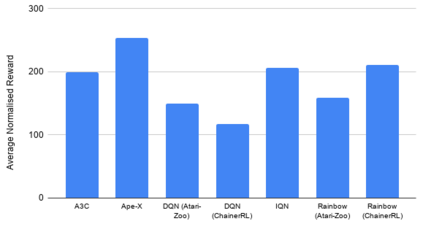
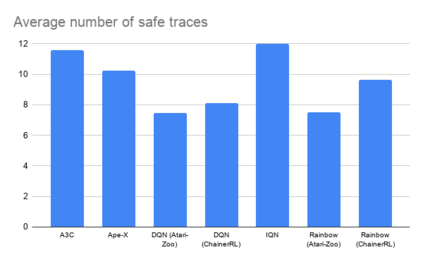
Deep reinforcement learning (DRL) is applied in safety-critical domains such as robotics and autonomous driving. It achieves superhuman abilities in many tasks, however whether DRL agents can be shown to act safely is an open problem. Atari games are a simple yet challenging exemplar for evaluating the safety of DRL agents and feature a diverse portfolio of game mechanics. The safety of neural agents has been studied before using methods that either require a model of the system dynamics or an abstraction; unfortunately, these are unsuitable to Atari games because their low-level dynamics are complex and hidden inside their emulator. We present the first exact method for analysing and ensuring the safety of DRL agents for Atari games. Our method only requires access to the emulator. First, we give a set of properties that characterise "safe behaviour" for several games. Second, we develop a method for exploring all traces induced by an agent and a game and consider a variety of sources of game non-determinism. We observe that the best available DRL agents reliably satisfy only very few properties; several critical properties are violated by all agents. Finally, we propose a countermeasure that combines a bounded explicit-state exploration with shielding. We demonstrate that our method improves the safety of all agents over multiple properties.
翻译:深度强化学习( DRL) 应用在像机器人和自主驾驶等安全关键领域。 它在许多任务中达到超人能力, 但是 DRL 代理器能否被显示安全操作是一个开放的问题。 Atari 游戏是评估 DRL 代理器安全的简单但富有挑战性的范例, 并具有多种游戏机理的特性。 在使用需要系统动态模型或抽象化的方法之前, 神经代理器的安全已经研究过; 不幸的是, 这些不适合 Atari 游戏, 因为它们的低级别动态复杂, 隐藏在模拟器中。 我们提出了第一个精确的方法, 用于分析和确保 Atari 游戏 DRL 代理器的安全。 我们的方法只要求使用模拟器。 首先, 我们给出一套属性为多个游戏“ 安全行为” 的属性。 其次, 我们开发一种方法来探索由代理器和游戏引发的所有痕迹, 并考虑游戏非决定性的多种来源。 我们观察到, 最佳的 DRL 代理器只能可靠地满足很少的属性; 几个关键属性被所有代理器破坏。 我们提出一个清晰的套式 。