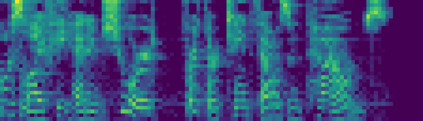
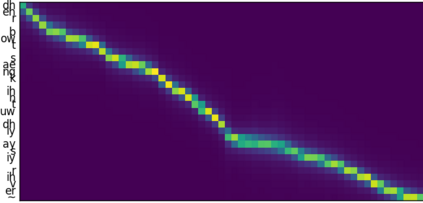
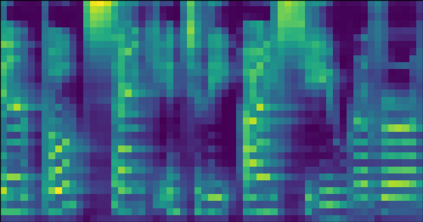
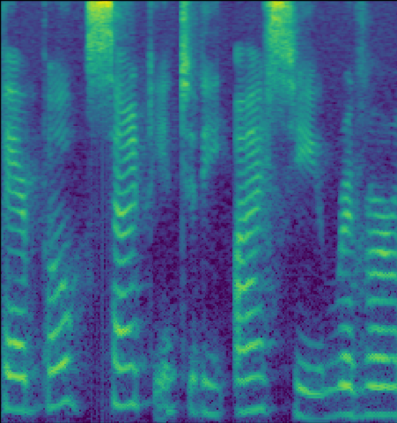
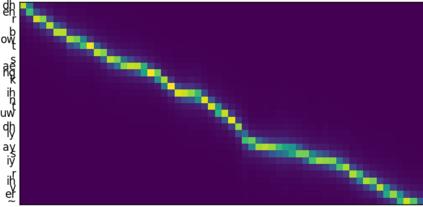
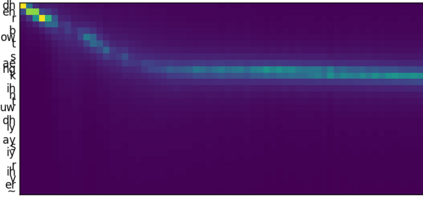
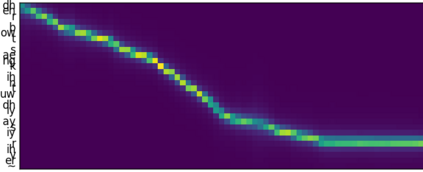
This paper introduces R-MelNet, a two-part autoregressive architecture with a frontend based on the first tier of MelNet and a backend WaveRNN-style audio decoder for neural text-to-speech synthesis. Taking as input a mixed sequence of characters and phonemes, with an optional audio priming sequence, this model produces low-resolution mel-spectral features which are interpolated and used by a WaveRNN decoder to produce an audio waveform. Coupled with half precision training, R-MelNet uses under 11 gigabytes of GPU memory on a single commodity GPU (NVIDIA 2080Ti). We detail a number of critical implementation details for stable half precision training, including an approximate, numerically stable mixture of logistics attention. Using a stochastic, multi-sample per step inference scheme, the resulting model generates highly varied audio, while enabling text and audio based controls to modify output waveforms. Qualitative and quantitative evaluations of an R-MelNet system trained on a single speaker TTS dataset demonstrate the effectiveness of our approach.
翻译:本文介绍了R- MelNet, 这是一种由两部分组成的自动递增结构,前端为MelNet第一层,前端为神经文字合成,后端为WaverNNNN-风格的音频解码器。作为输入,该模型生成了一个混合字符和音频序列,并带有一个可选的音频边缘序列,产生低分辨率中位谱特征,由WaveRNNN 解码器进行内插并用于制作音波形。R-MelNet与半精度培训结合,在11千兆字节的GPU记忆下使用R-MelNet用于单一的GPU(NVIDIA 2080Ti) 。我们详细介绍了稳定半精度培训的关键实施细节,包括一个大致、数字稳定的物流关注组合。使用一种随机、多相位组合的推导法模型生成了高度不同的音频,同时使文字和音频控制能够修改输出波形。对在单一讲者TTTS数据集上培训的R- MelNet系统进行了定性和定量评估。我们的方法效果。