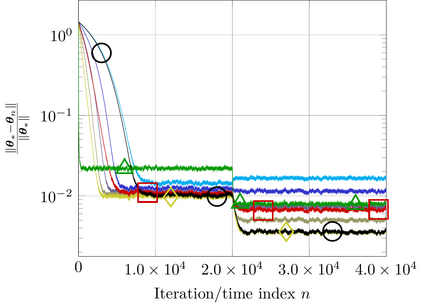
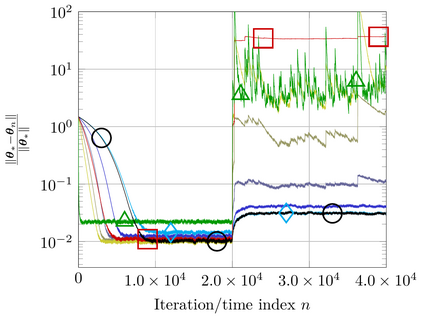
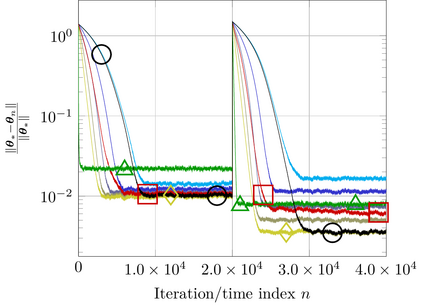
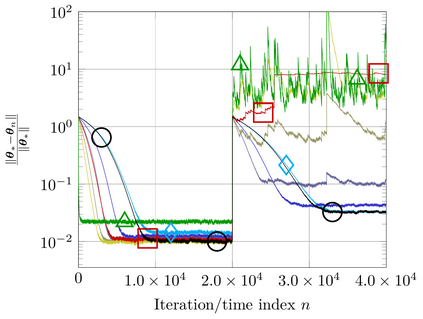
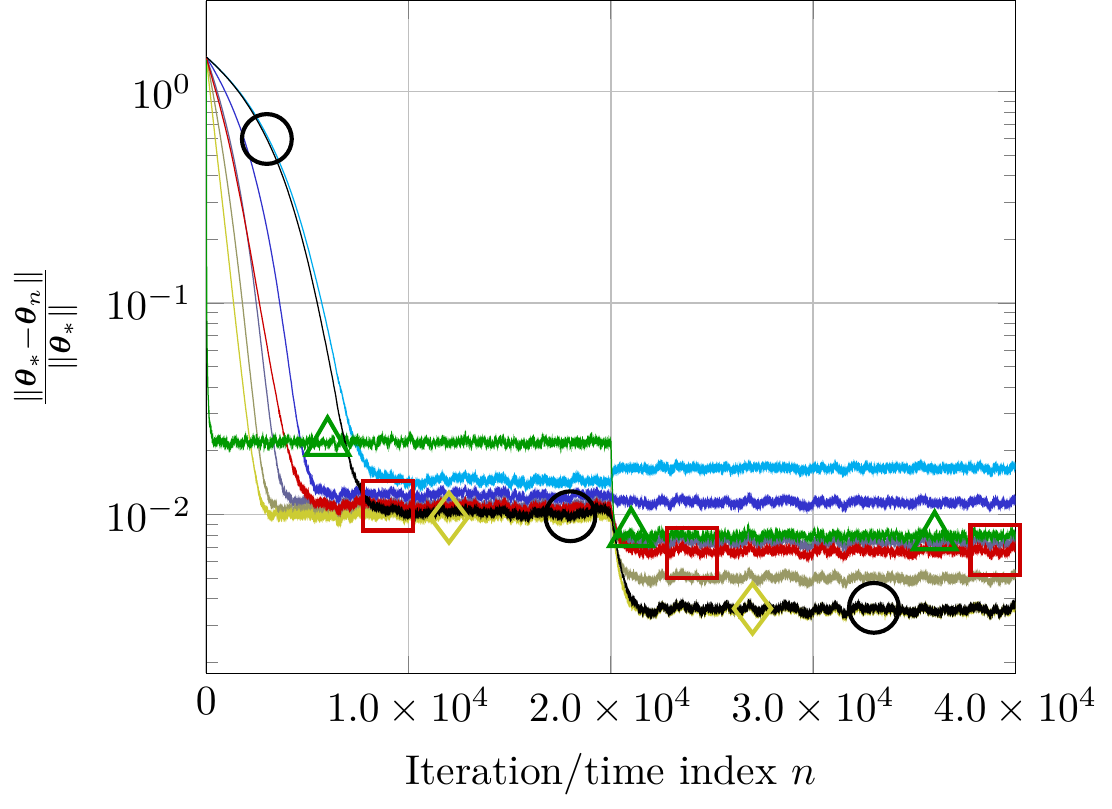
This study addresses the problem of selecting dynamically, at each time instance, the ``optimal'' p-norm to combat outliers in linear adaptive filtering without any knowledge on the potentially time-varying probability distribution function of the outliers. To this end, an online and data-driven framework is designed via kernel-based reinforcement learning (KBRL). Novel Bellman mappings on reproducing kernel Hilbert spaces (RKHSs) are introduced that need no knowledge on transition probabilities of Markov decision processes, and are nonexpansive with respect to the underlying Hilbertian norm. An approximate policy-iteration framework is finally offered via the introduction of a finite-dimensional affine superset of the fixed-point set of the proposed Bellman mappings. The well-known ``curse of dimensionality'' in RKHSs is addressed by building a basis of vectors via an approximate linear dependency criterion. Numerical tests on synthetic data demonstrate that the proposed framework selects always the ``optimal'' p-norm for the outlier scenario at hand, outperforming at the same time several non-RL and KBRL schemes.
翻译:本研究针对的是动态选择问题,在每一次实例中,在线性适应性过滤中,用“最优'p-norm”来对抗线性适应性过滤的外源,而不知道外源的潜在时间变化概率分布功能。为此,通过内核强化学习(KBRL)设计了一个在线和数据驱动的框架。关于再生产核心Hilbert空间(RKHS)的Novel Bellman绘图,不需要了解Markov决定过程的过渡概率,而且对于Hilbertian 基本规范来说是非探索性的。一个近似的政策命名框架最终通过引入拟议的Bellman绘图的固定点组合的有限维度超级集而提供。在RKHS中众所周知的天文特性的参数是通过大致的线性依赖性标准建立矢量基础来解决的。对合成数据的数值测试表明,拟议的框架总是选择Hilbertian 规范的外端假设的“最优度”p-norm。