
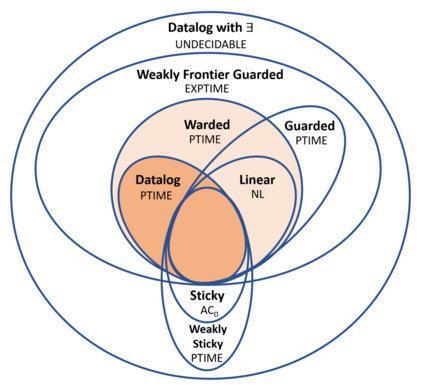
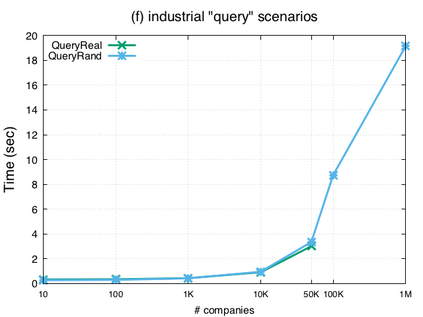
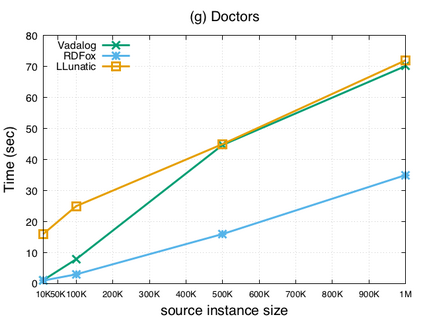
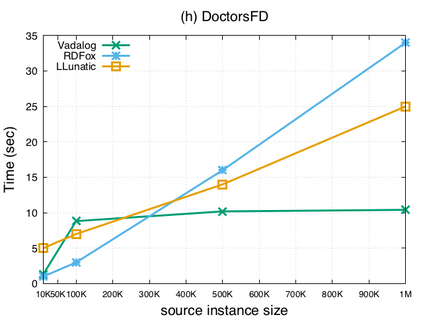
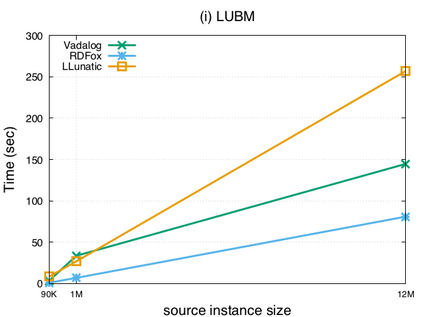
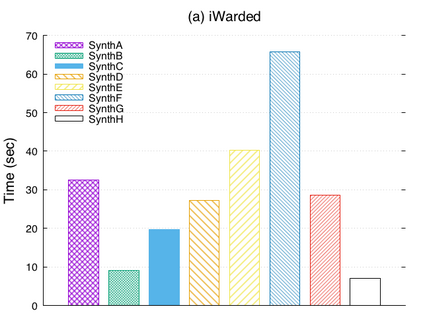
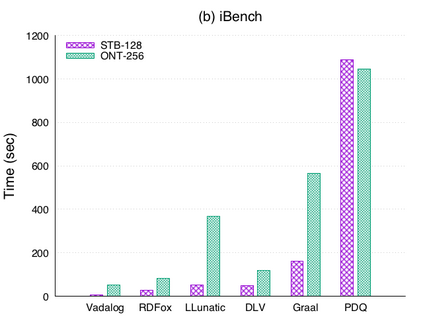
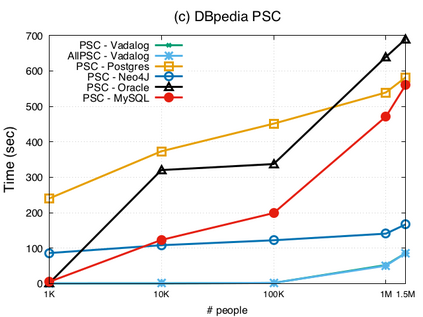
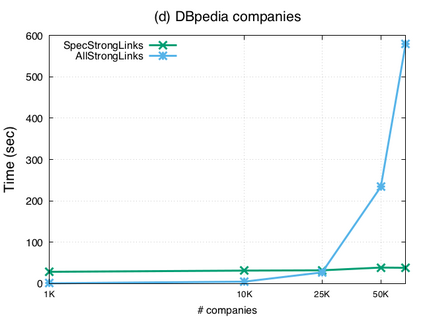
Over the past years, there has been a resurgence of Datalog-based systems in the database community as well as in industry. In this context, it has been recognized that to handle the complex knowl\-edge-based scenarios encountered today, such as reasoning over large knowledge graphs, Datalog has to be extended with features such as existential quantification. Yet, Datalog-based reasoning in the presence of existential quantification is in general undecidable. Many efforts have been made to define decidable fragments. Warded Datalog+/- is a very promising one, as it captures PTIME complexity while allowing ontological reasoning. Yet so far, no implementation of Warded Datalog+/- was available. In this paper we present the Vadalog system, a Datalog-based system for performing complex logic reasoning tasks, such as those required in advanced knowledge graphs. The Vadalog system is Oxford's contribution to the VADA research programme, a joint effort of the universities of Oxford, Manchester and Edinburgh and around 20 industrial partners. As the main contribution of this paper, we illustrate the first implementation of Warded Datalog+/-, a high-performance Datalog+/- system utilizing an aggressive termination control strategy. We also provide a comprehensive experimental evaluation.
翻译:过去几年来,数据库界和行业都重新出现了以数据为基础的系统,在这方面,人们认识到,要处理今天遇到的复杂的知识-前沿-基于前沿的情景,例如大型知识图表的推理,数据log必须扩展,具有生存量化等特征;然而,以数据为基础的推理在存在量化方面总的来说是不可变化的;为界定可变碎片作出了许多努力;经调整的数据log+/-是一个很有希望的系统,因为它既反映了PTIME的复杂性,又允许本体推理;然而,迄今为止,没有实施经调整的数据+/-。在本文件中,我们介绍了Vadalog系统,这是一个基于数据系统的系统,用于执行复杂的逻辑推理任务,如高级知识图表中要求的那些任务。VADA研究方案是牛津大学、曼彻斯特和爱丁堡大学以及大约20个工业伙伴的一项联合努力,这是很有希望的。作为本文件的主要贡献,我们介绍了首次实施经调整的数据+/高性实验战略,我们还提供了一种高性数据-终止系统。
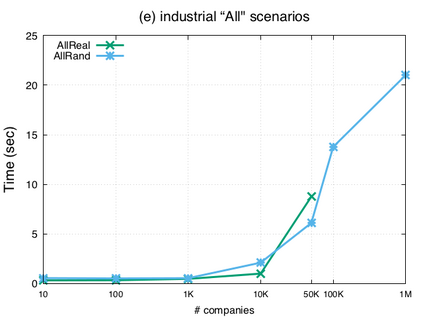
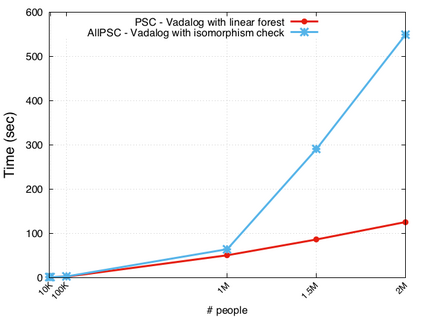
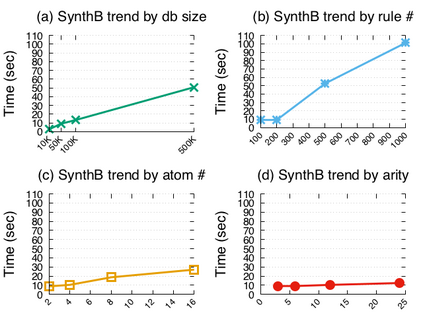
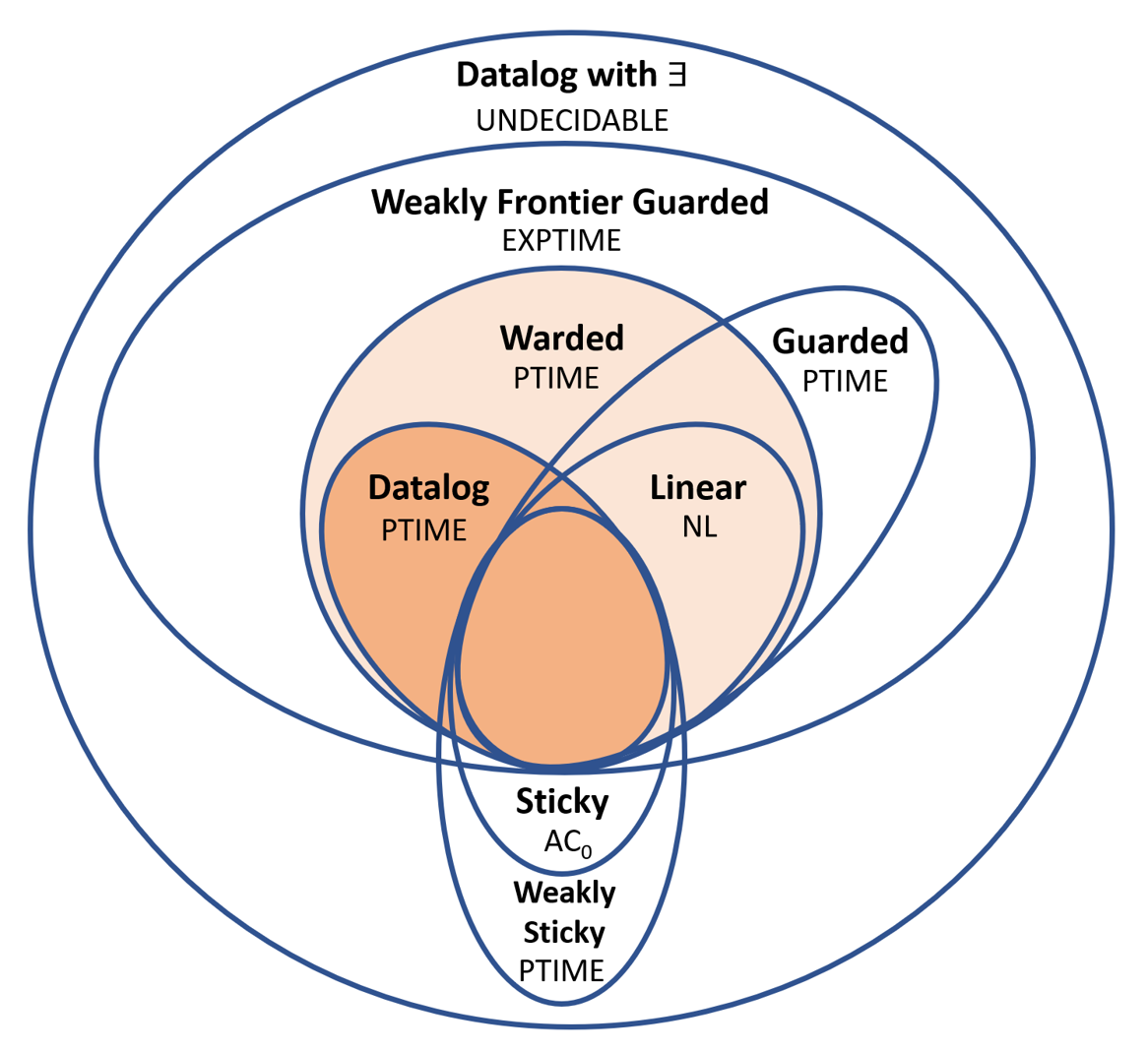
相关内容

牛津大学是一所英国研究型大学,也是罗素大学集团、英国“G5超级精英大学”,欧洲顶尖大学科英布拉集团、欧洲研究型大学联盟的核心成员。牛津大学培养了众多社会名人,包括了27位英国首相、60位诺贝尔奖得主以及数十位世界各国的皇室成员和政治领袖。2016年9月,泰晤士高等教育发布了2016-2017年度世界大学排名,其中牛津大学排名第一。

