
题目: Time2Vec: Learning a Vector Representation of Time
摘要:
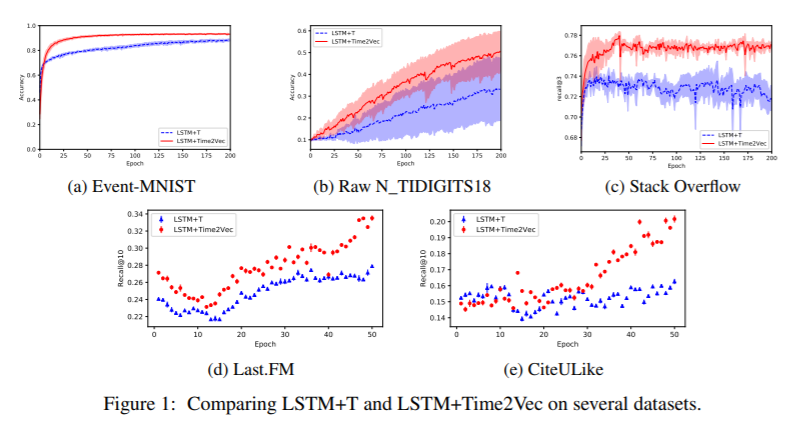
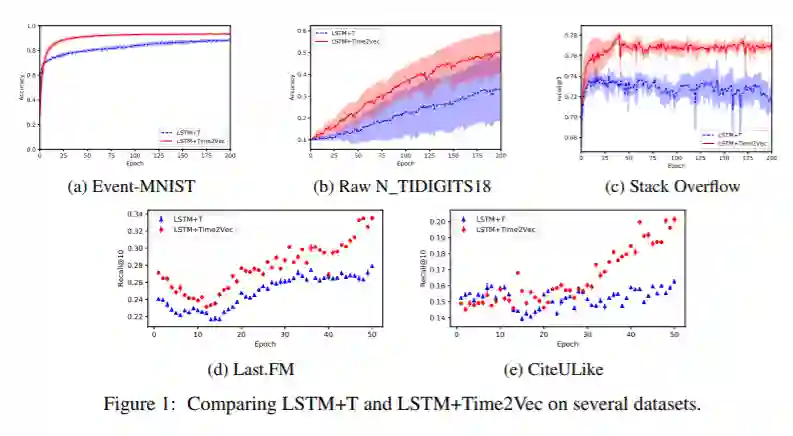
在许多涉及同步或异步发生的事件的应用程序中,时间是一个重要的特性。为了有效地消耗时间信息,最近的研究集中于设计新的架构。在本文中,采用了一种正交但又互补的方法,提供了一种与模型无关的时间向量表示,称为Time2Vec,它可以很容易地导入到许多现有和未来的体系结构中并改进其性能。文中展示了一系列的模型和问题,用Time2Vec表示代替时间的概念可以提高最终模型的性能。
成为VIP会员查看完整内容

相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
相关资讯
相关论文