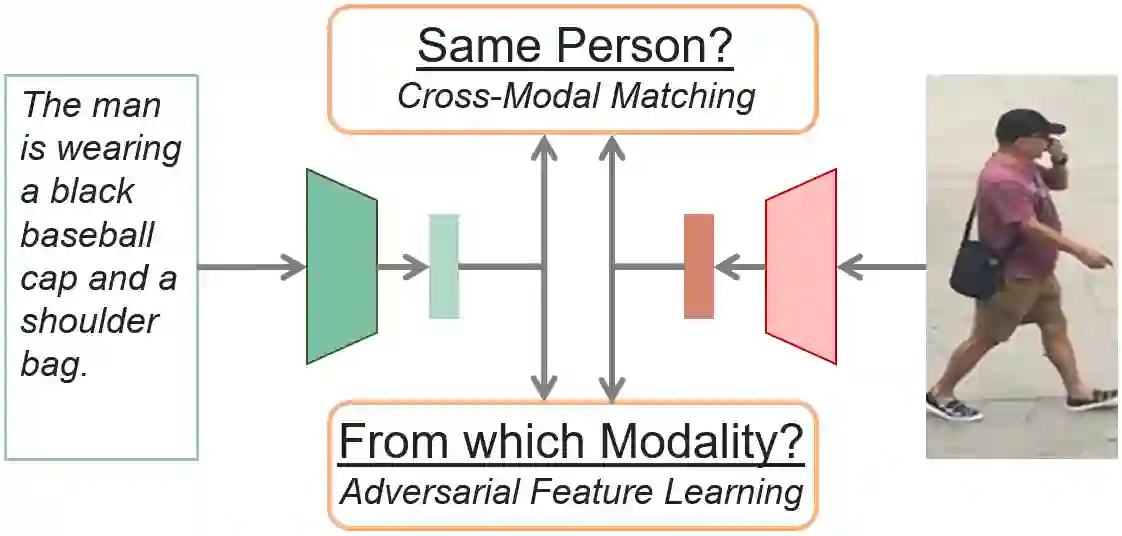
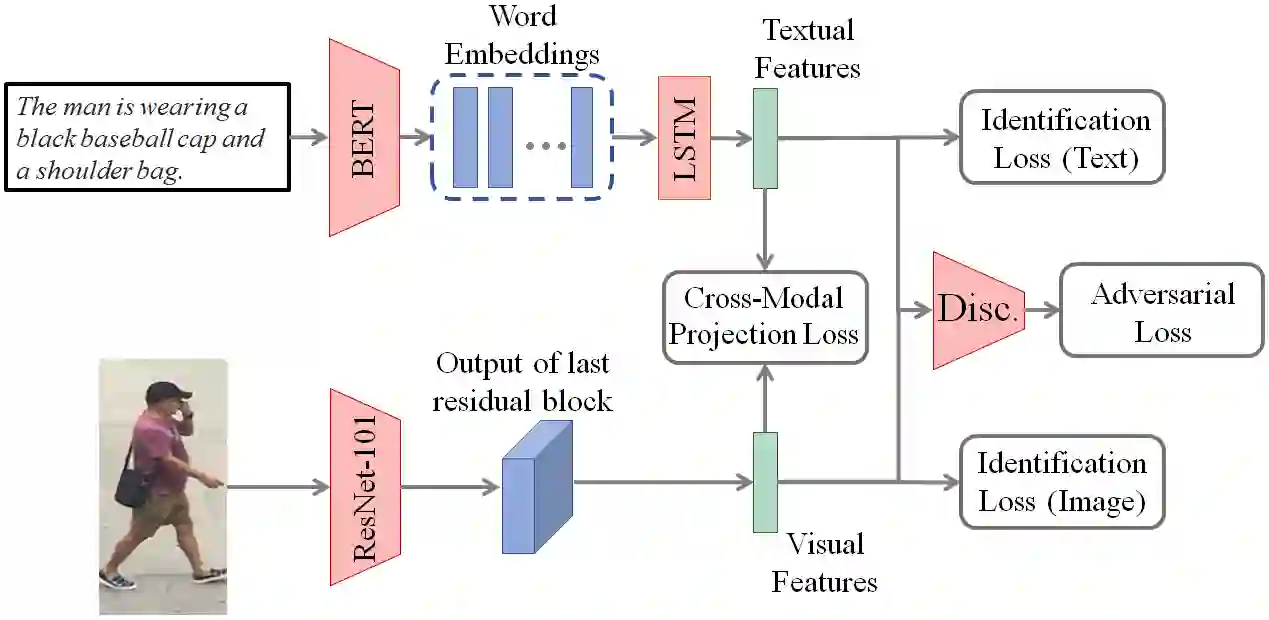
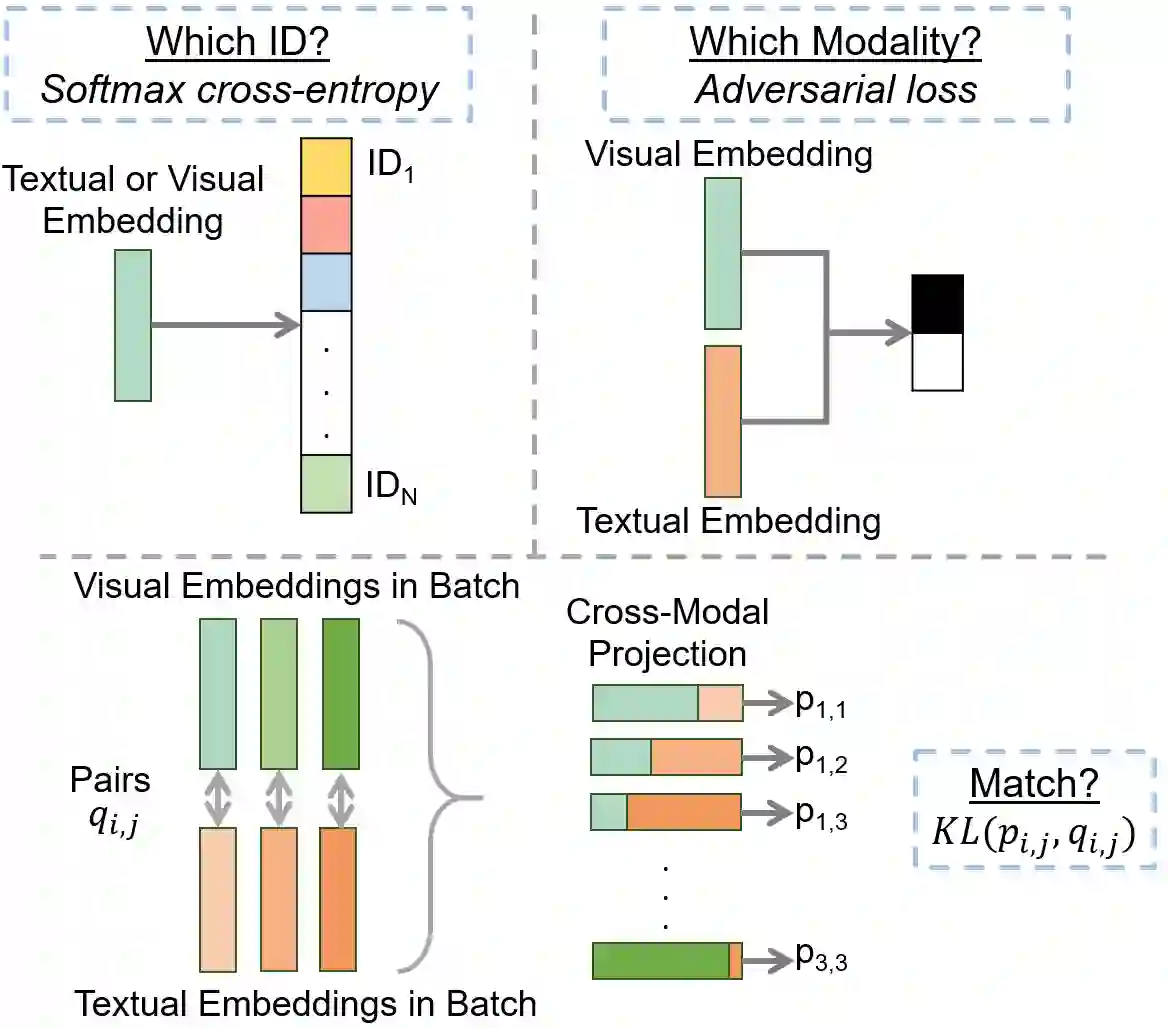
For many computer vision applications such as image captioning, visual question answering, and person search, learning discriminative feature representations at both image and text level is an essential yet challenging problem. Its challenges originate from the large word variance in the text domain as well as the difficulty of accurately measuring the distance between the features of the two modalities. Most prior work focuses on the latter challenge, by introducing loss functions that help the network learn better feature representations but fail to account for the complexity of the textual input. With that in mind, we introduce TIMAM: a Text-Image Modality Adversarial Matching approach that learns modality-invariant feature representations using adversarial and cross-modal matching objectives. In addition, we demonstrate that BERT, a publicly-available language model that extracts word embeddings, can successfully be applied in the text-to-image matching domain. The proposed approach achieves state-of-the-art cross-modal matching performance on four widely-used publicly-available datasets resulting in absolute improvements ranging from 2% to 5% in terms of rank-1 accuracy.
翻译:对于许多计算机视觉应用,如图像字幕、视觉问答和人员搜索等,学习图像和文本层面的歧视性特征表现是一个重要但具有挑战性的问题。挑战来自文本领域的大字差异以及准确测量两种模式特征之间距离的难度。大多数先前的工作侧重于后一种挑战,即引入损失功能,帮助网络学习更好的特征表现,但不能说明文字输入的复杂性。考虑到这一点,我们引入了TIMAM:一种文本-图像模式对立方法,通过对抗和交叉模式匹配目标学习模式-变量特征表现。此外,我们证明BERT这一可公开使用的语言模型可以成功应用于文本到图像匹配领域,它有助于网络学习更好的特征表现,但无法对文本输入的复杂性进行解释。拟议方法在四种广泛使用的公开可用数据集上实现最先进的交叉模式匹配性表现,其结果是在排名-1准确性方面从2%到5%的绝对改进。