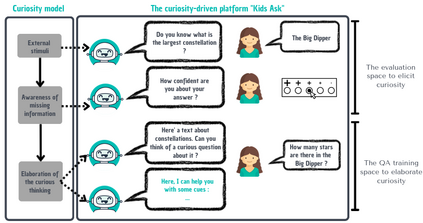
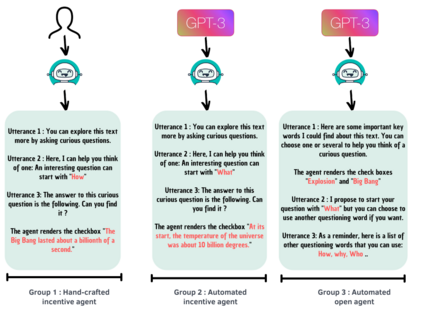
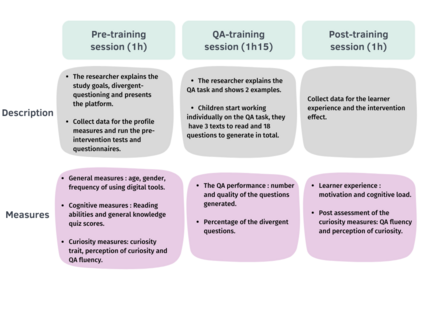
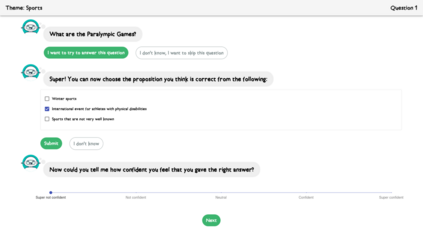
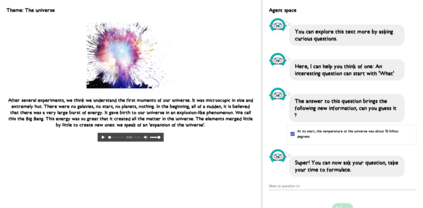
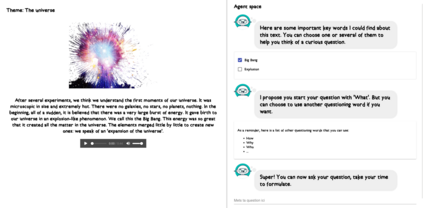
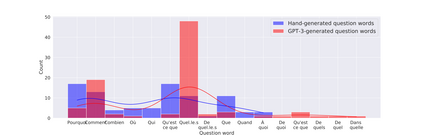
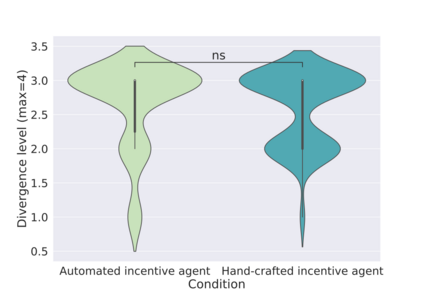
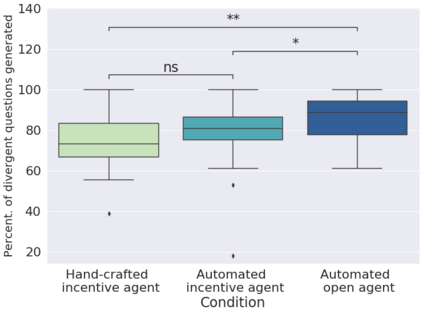
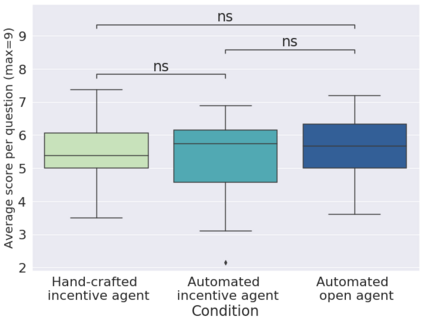
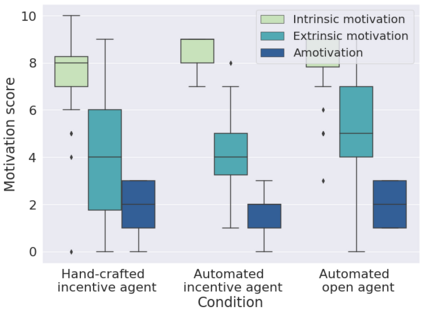
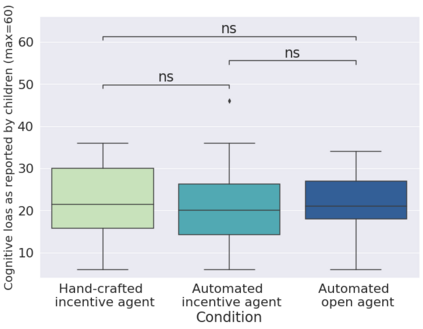
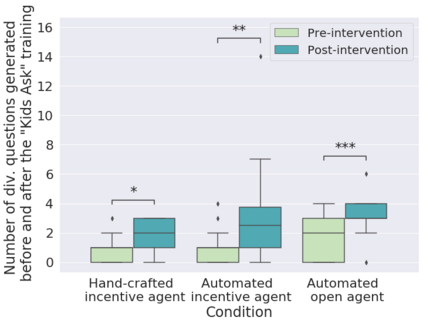
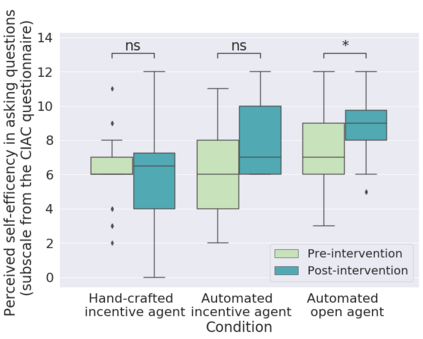
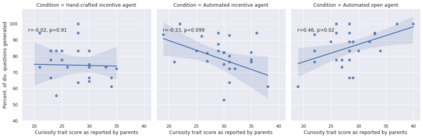
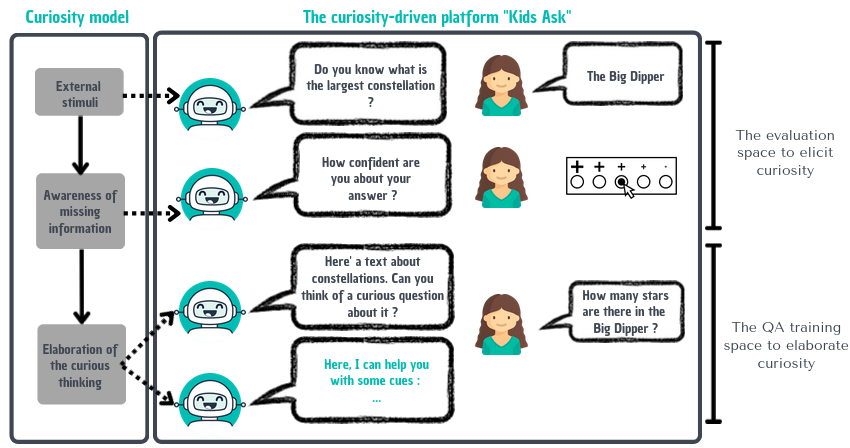
In order to train children's ability to ask curiosity-driven questions, previous research has explored designing specific exercises relying on providing semantic and linguistic cues to help formulate such questions. But despite showing pedagogical efficiency, this method is still limited as it relies on generating the said cues by hand, which can be a very costly process. In this context, we propose to leverage advances in the natural language processing field (NLP) and investigate the efficiency of using a large language model (LLM) for automating the production of the pedagogical content of a curious question-asking (QA) training. We study generating the said content using the "prompt-based" method that consists of explaining the task to the LLM in natural text. We evaluate the output using human experts annotations and comparisons with hand-generated content. Results suggested indeed the relevance and usefulness of this content. We also conduct a field study in primary school (75 children aged 9-10), where we evaluate children's QA performance when having this training. We compare 3 types of content : 1) hand-generated content that proposes "closed" cues leading to predefined questions; 2) GPT-3-generated content that proposes the same type of cues; 3) GPT-3-generated content that proposes "open" cues leading to several possible questions. We see a similar QA performance between the two "closed" trainings (showing the scalability of the approach using GPT-3), and a better one for participants with the "open" training. These results suggest the efficiency of using LLMs to support children in generating more curious questions, using a natural language prompting approach that affords usability by teachers and other users not specialists of AI techniques. Furthermore, results also show that open-ended content may be more suitable for training curious question-asking skills.
翻译:为了训练儿童提问好奇心驱动的能力,先前的研究探索设计特定的练习,依赖于提供语义和语言线索来帮助制定这样的问题。但尽管显示出教育效果,但这种方法仍然有限,因为它依赖于手动生成上述线索,这可能是一个非常昂贵的过程。在这种情况下,我们提议利用自然语言处理领域(NLP)的进展,并研究使用大型语言模型(LLM)自动化好奇心提问(QA)训练的教育内容的有效性。我们使用“基于提示”的方法生成上述内容,该方法包括在自然文本中解释任务以向LLM解释。我们使用人类专家注释和与手动生成的内容比较来评估输出。结果确实表明了这种内容的相关性和有用性。我们还在小学进行了现场研究(75名年龄为9-10岁的儿童),在此过程中,我们评估了儿童在进行此项训练时的QA表现。我们比较了3种类型的内容:1)提供导致预定义问题的“封闭”线索的手动生成的内容;2)提供相同类型线索的 GPT-3 生成的内容;3)提供导致几个可能问题的“开放”线索的 GPT-3 生成的内容。我们发现两种“封闭”训练之间的QA性能类似(展示了使用GPT-3扩展方法的可伸缩性),对于接受“开放”训练的参与者,则性能更好。这些结果表明,使用LLMs支持儿童在生成更好奇的问题方面具有效率,使用一种自然语言提示方法,该方法可以为教师和其他非AI技术专业人员提供易用性。此外,结果还表明,开放式内容可能更适合训练好奇心提问技能。