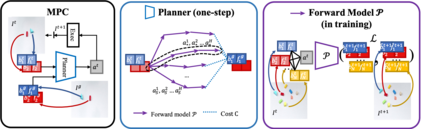
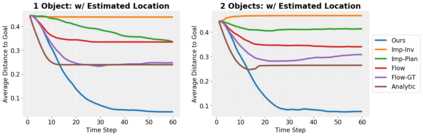
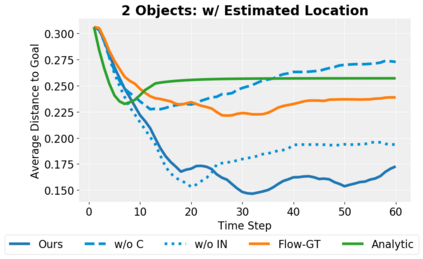
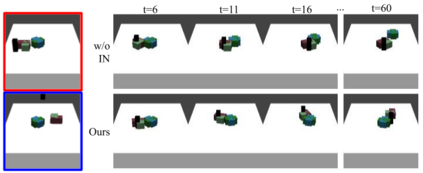
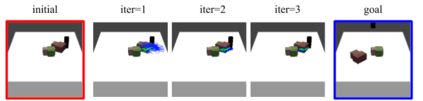
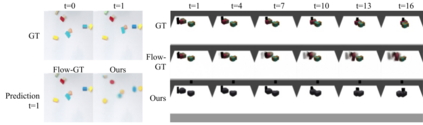
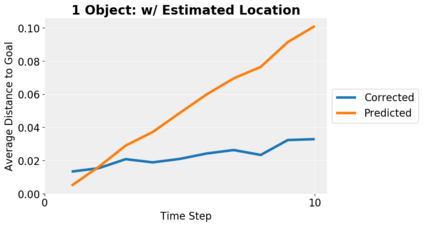
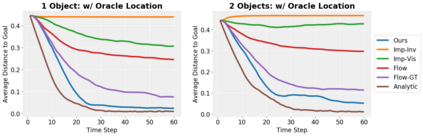
We present an approach to learn an object-centric forward model, and show that this allows us to plan for sequences of actions to achieve distant desired goals. We propose to model a scene as a collection of objects, each with an explicit spatial location and implicit visual feature, and learn to model the effects of actions using random interaction data. Our model allows capturing the robot-object and object-object interactions, and leads to more sample-efficient and accurate predictions. We show that this learned model can be leveraged to search for action sequences that lead to desired goal configurations, and that in conjunction with a learned correction module, this allows for robust closed loop execution. We present experiments both in simulation and the real world, and show that our approach improves over alternate implicit or pixel-space forward models. Please see our project page (https://judyye.github.io/ocmpc/) for result videos.
翻译:我们提出了一个方法来学习一个以物体为中心的远方模型,并显示这使我们能够规划实现远方预期目标的行动序列。 我们提议将场景建模成一个物体集,每个物体都有明确的空间位置和隐含的视觉特征,并学习使用随机交互数据模拟行动的效果。 我们的模型可以捕捉机器人-物体和物体-物体相互作用,并导致更具有抽样效率和准确的预测。 我们显示,可以利用这个学习过的模型来搜索导致理想目标配置的行动序列,并且与一个学习的校正模块一起,可以进行稳健的闭路执行。 我们在模拟和真实世界中进行实验,并表明我们的方法在替代的隐含或像素-空间前方模型方面有所改进。 请参见我们的项目网页(https://judyye.github.io/ocmpc/) 以获取结果视频。