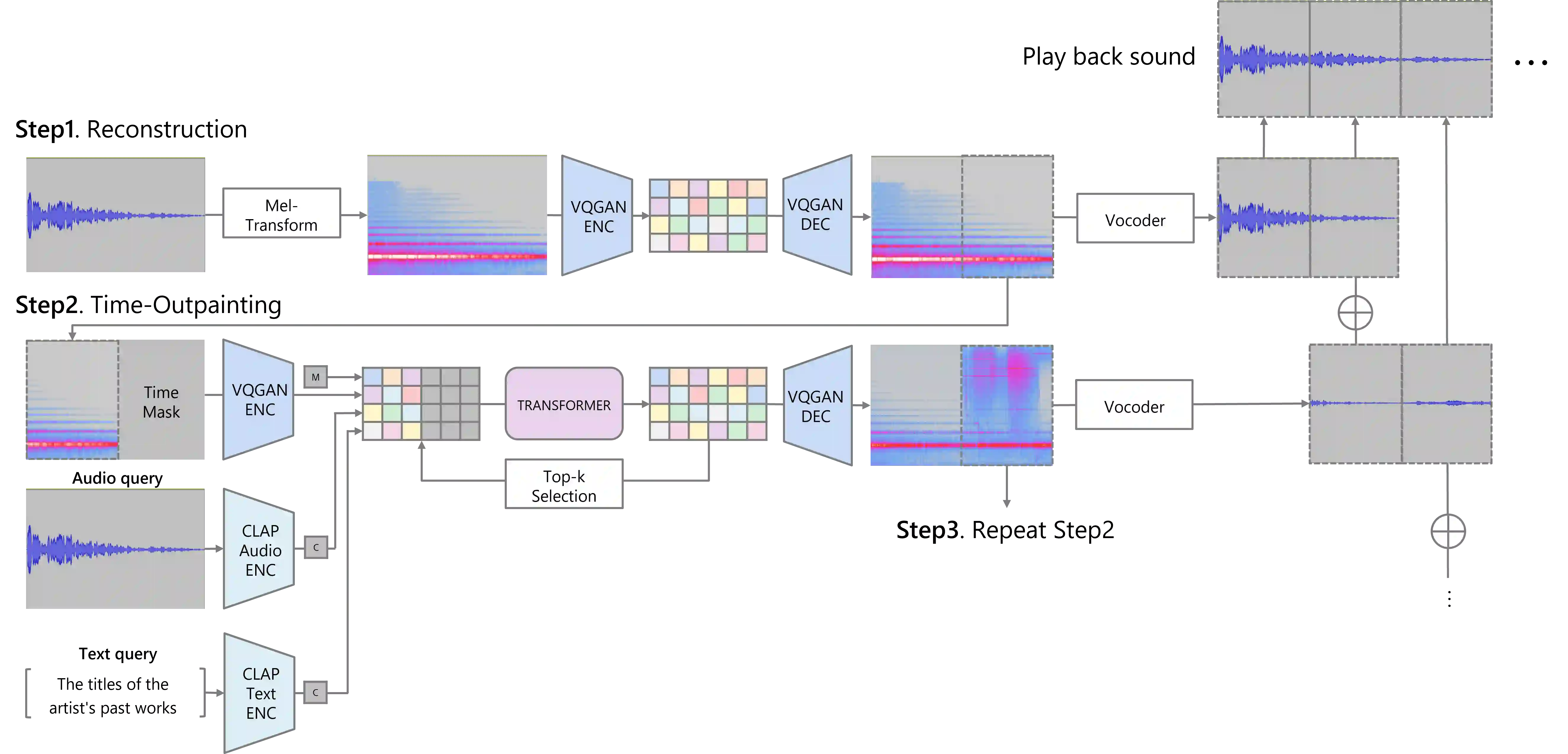
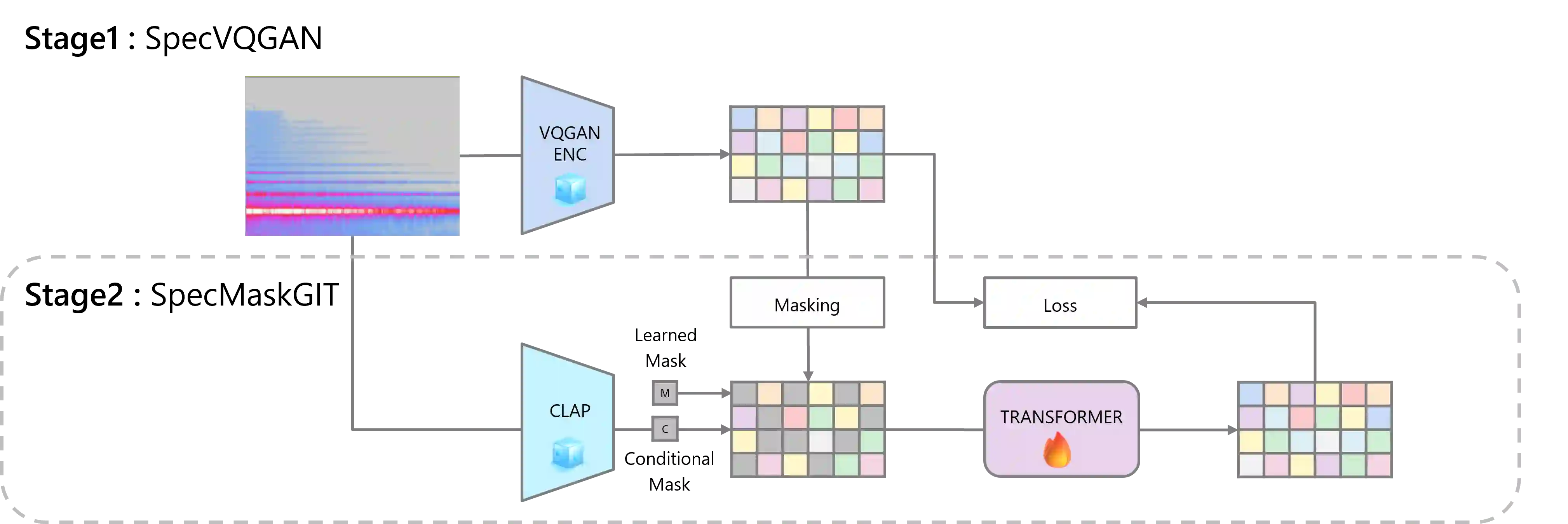
This paper explores the integration of AI technologies into the artistic workflow through the creation of Studies for, a generative sound installation developed in collaboration with sound artist Evala (https://www.ntticc.or.jp/en/archive/works/studies-for/). The installation employs SpecMaskGIT, a lightweight yet high-quality sound generation AI model, to generate and playback eight-channel sound in real-time, creating an immersive auditory experience over the course of a three-month exhibition. The work is grounded in the concept of a "new form of archive," which aims to preserve the artistic style of an artist while expanding beyond artists' past artworks by continued generation of new sound elements. This speculative approach to archival preservation is facilitated by training the AI model on a dataset consisting of over 200 hours of Evala's past sound artworks. By addressing key requirements in the co-creation of art using AI, this study highlights the value of the following aspects: (1) the necessity of integrating artist feedback, (2) datasets derived from an artist's past works, and (3) ensuring the inclusion of unexpected, novel outputs. In Studies for, the model was designed to reflect the artist's artistic identity while generating new, previously unheard sounds, making it a fitting realization of the concept of "a new form of archive." We propose a Human-AI co-creation framework for effectively incorporating sound generation AI models into the sound art creation process and suggest new possibilities for creating and archiving sound art that extend an artist's work beyond their physical existence. Demo page: https://sony.github.io/studies-for/
翻译:本文通过创作《为...而作的研究》这一生成性声音装置,探讨了将人工智能技术融入艺术创作流程的实践。该作品是与声音艺术家Evala(https://www.ntticc.or.jp/en/archive/works/studies-for/)合作开发的。装置采用SpecMaskGIT——一种轻量级且高质量的声音生成AI模型,实时生成并播放八通道声音,在为期三个月的展览中营造沉浸式听觉体验。作品基于‘新型档案’的概念,旨在保存艺术家的艺术风格,同时通过持续生成新的声音元素,超越艺术家过去的作品。这种推测性的档案保存方法通过在一个包含超过200小时Evala过去声音艺术作品的数据集上训练AI模型得以实现。通过解决使用AI进行艺术协同创作的关键需求,本研究强调了以下方面的价值:(1)整合艺术家反馈的必要性,(2)源自艺术家过去作品的数据集,以及(3)确保包含意外、新颖的输出。在《为...而作的研究》中,模型被设计为在生成新的、前所未闻的声音的同时反映艺术家的艺术身份,使其成为‘新型档案’概念的恰当实现。我们提出了一个有效将声音生成AI模型融入声音艺术创作过程的人机协同创作框架,并为创造和归档声音艺术提出了新的可能性,使艺术家的作品得以超越其物理存在而延续。演示页面:https://sony.github.io/studies-for/