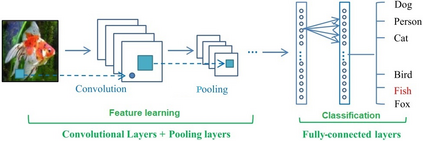
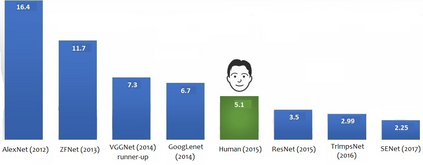
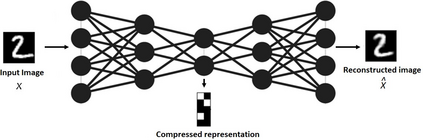
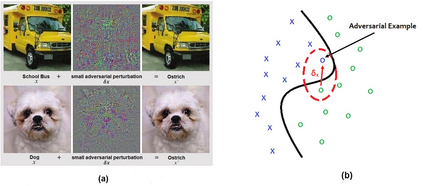
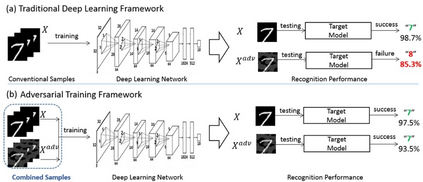
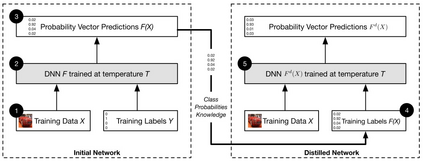
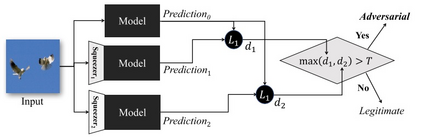
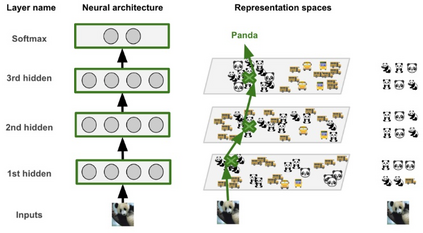
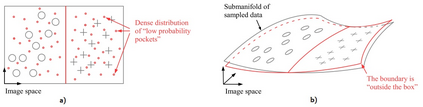
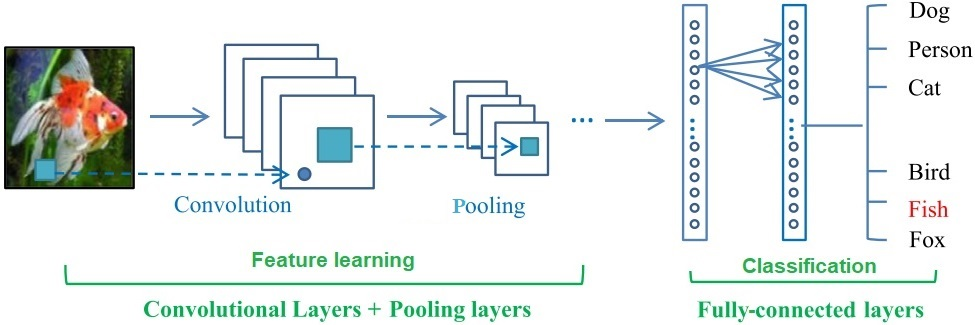
Deep Learning algorithms have achieved the state-of-the-art performance for Image Classification and have been used even in security-critical applications, such as biometric recognition systems and self-driving cars. However, recent works have shown those algorithms, which can even surpass the human capabilities, are vulnerable to adversarial examples. In Computer Vision, adversarial examples are images containing subtle perturbations generated by malicious optimization algorithms in order to fool classifiers. As an attempt to mitigate these vulnerabilities, numerous countermeasures have been constantly proposed in literature. Nevertheless, devising an efficient defense mechanism has proven to be a difficult task, since many approaches have already shown to be ineffective to adaptive attackers. Thus, this self-containing paper aims to provide all readerships with a review of the latest research progress on Adversarial Machine Learning in Image Classification, however with a defender's perspective. Here, novel taxonomies for categorizing adversarial attacks and defenses are introduced and discussions about the existence of adversarial examples are provided. Further, in contrast to exisiting surveys, it is also given relevant guidance that should be taken into consideration by researchers when devising and evaluating defenses. Finally, based on the reviewed literature, it is discussed some promising paths for future research.
翻译:深学习算法达到了图像分类的最新水平,甚至被用于安全关键应用,如生物鉴别识别系统和自行驾驶汽车等。然而,最近的著作显示,这些算法甚至可能超过人的能力,很容易受到对抗性的例子的影响。在计算机愿景中,对抗性的例子包括恶意优化算法产生的微妙扰动的图像,以愚弄分类者。为了减轻这些脆弱性,文献中不断提出许多对策。然而,设计高效的防御机制证明是一项困难的任务,因为许多方法已经证明对适应性攻击者来说是无效的。因此,这一自含文件旨在向所有读者提供关于Aversarial机器学习在图像分类方面的最新研究进展的回顾,但以维护者的观点为依据。在这里,引入了用于对对抗性攻击和辩护进行分类的新分类,并讨论了是否存在对抗性实例。此外,与说明性调查相反,它还提供了相关指导,研究人员在设计和评价防御时应考虑这些指导。最后,根据经过审查的文献的路径,讨论了未来研究的前景。