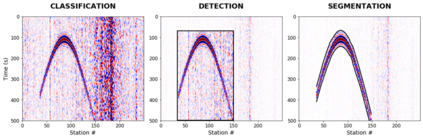
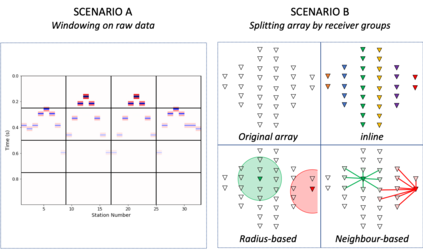
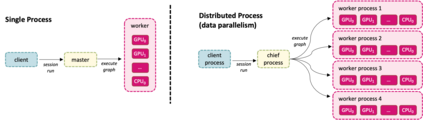
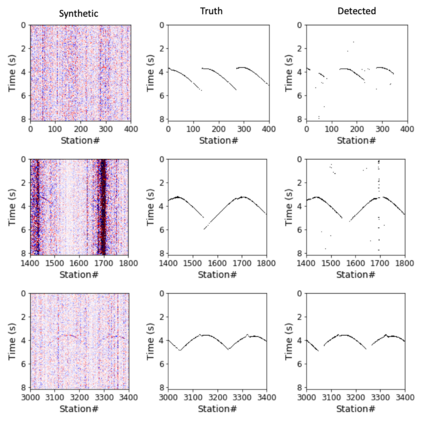
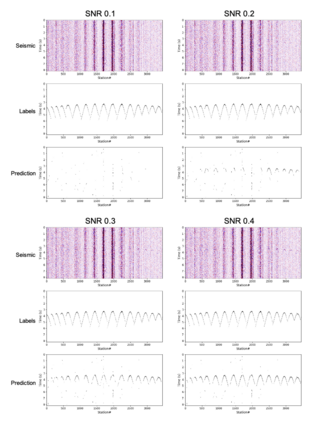
Deep learning applications are drastically progressing in seismic processing and interpretation tasks. However, the majority of approaches subsample data volumes and restrict model sizes to minimise computational requirements. Subsampling the data risks losing vital spatio-temporal information which could aid training whilst restricting model sizes can impact model performance, or in some extreme cases, renders more complicated tasks such as segmentation impossible. This paper illustrates how to tackle the two main issues of training of large neural networks: memory limitations and impracticably large training times. Typically, training data is preloaded into memory prior to training, a particular challenge for seismic applications where data is typically four times larger than that used for standard image processing tasks (float32 vs. uint8). Using a microseismic use case, we illustrate how over 750GB of data can be used to train a model by using a data generator approach which only stores in memory the data required for that training batch. Furthermore, efficient training over large models is illustrated through the training of a 7-layer UNet with input data dimensions of 4096X4096. Through a batch-splitting distributed training approach, training times are reduced by a factor of four. The combination of data generators and distributed training removes any necessity of data 1 subsampling or restriction of neural network sizes, offering the opportunity of utilisation of larger networks, higher-resolution input data or moving from 2D to 3D problem spaces.
翻译:深度学习应用在地震处理和解释任务方面正在取得巨大进步。然而,大多数方法在地震处理和解释任务方面正在取得巨大进步。但是,大多数方法在对数据量进行子抽样,并限制模型大小,以尽量减少计算要求。对数据进行分解,可能会失去重要的时空信息,而这种信息在限制模型规模的同时会帮助培训,从而影响模型性能,或在某些极端情况下,使分解等等任务更加复杂。本文说明了如何解决大型神经网络培训的两个主要问题:记忆限制和不实际的大型培训时间。通常,培训前先将培训数据放在记忆中,这是地震应用的一个特殊挑战,在通常情况下,数据通常比标准图像处理任务(float32 vs. Vint. Vint8.)使用四倍的地震应用。 进行分解式分析时,数据可能会失去重要的空间,我们用750GB的数据来培训模式培训,因为数据只储存在记忆中存储培训批量所需的数据。此外,通过培训一个7层UNet的4-40-4096输入数据层面,对于地震应用来说,这是特别的挑战。通过分解的分解式培训方法,或者分解1号数据输入网络的分解数据,从一个分解一个分解,或分解的数据分解一个分解一个分解一个分解一个分解一个数据分解一个数据分解一个分解一个分解一个数据分解一个分解一个数据数。