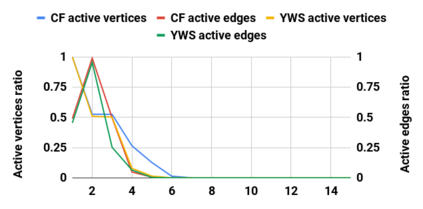
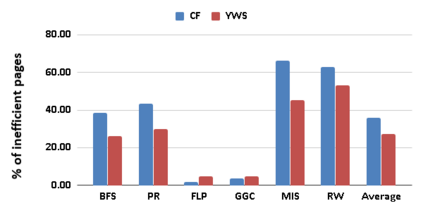
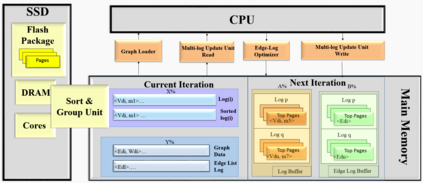
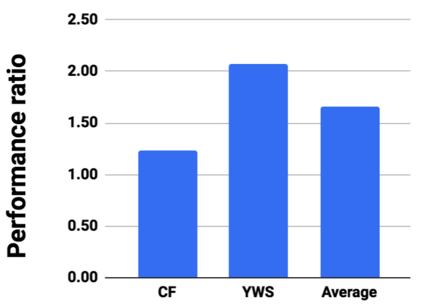
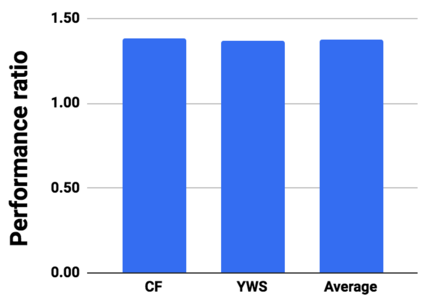
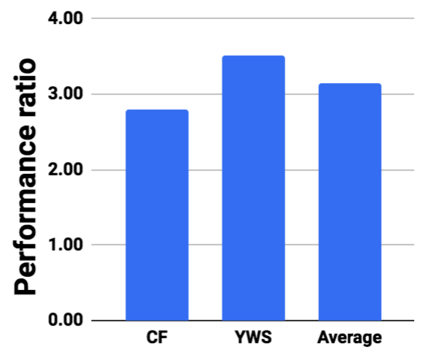
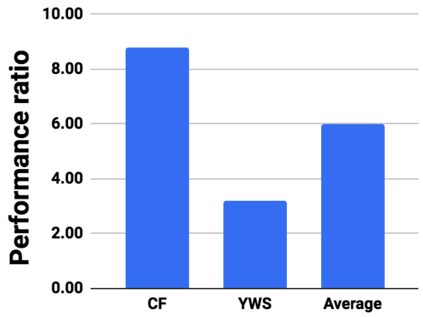
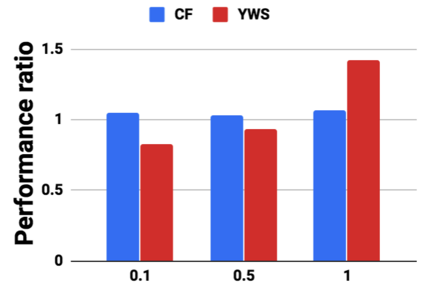
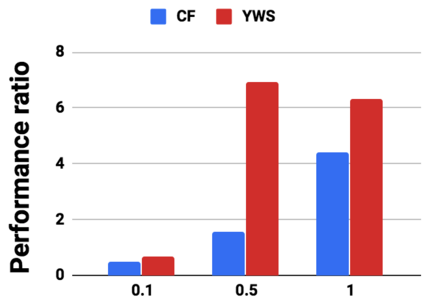
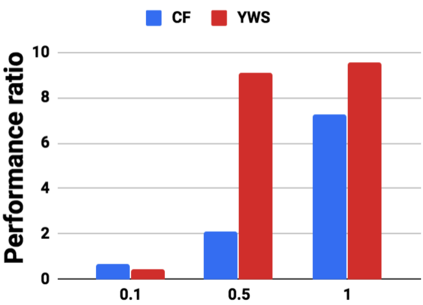
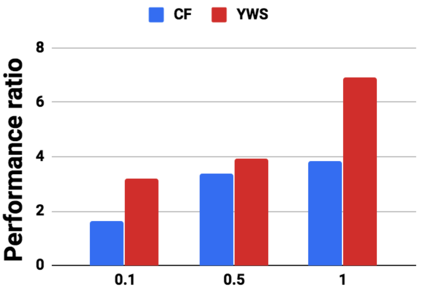
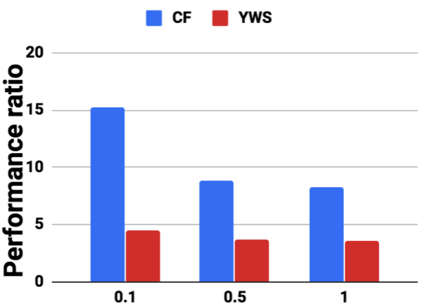
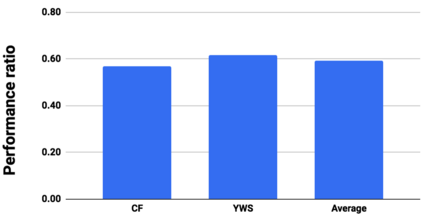
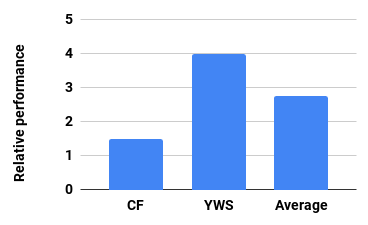
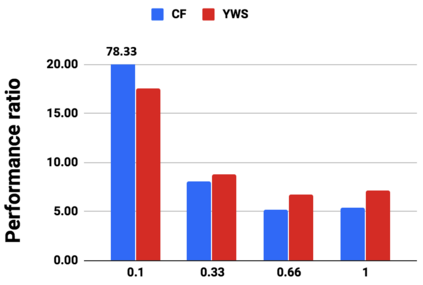
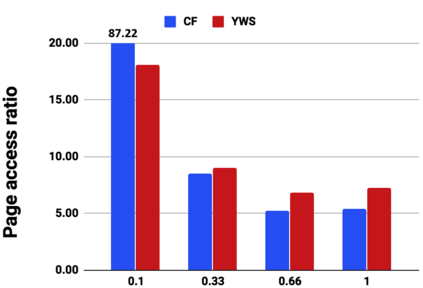
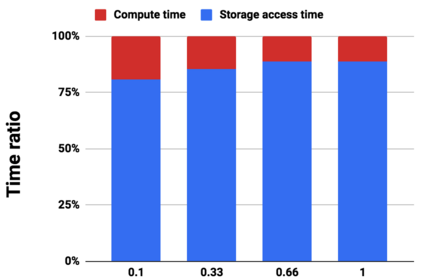
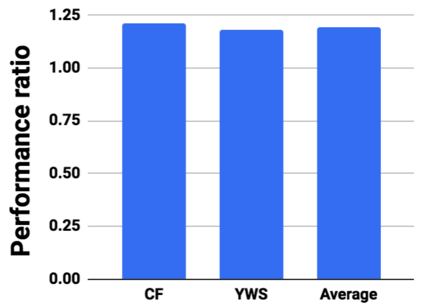
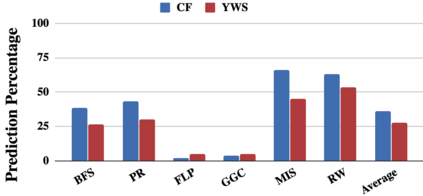
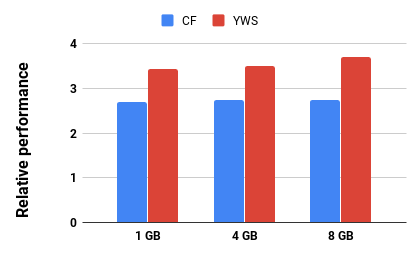
Graph analytics are at the heart of a broad range of applications such as drug discovery, page ranking, and recommendation systems. When graph size exceeds memory size, out-of-core graph processing is needed. For the widely used external memory graph processing systems, accessing storage becomes the bottleneck. We make the observation that nearly all graph algorithms have a dynamically varying number of active vertices that must be processed in each iteration. However, existing graph processing frameworks, such as GraphChi, load the entire graph in each iteration even if a small fraction of the graph is active. This limitation is due to the structure of the data storage used by these systems. In this work, we propose to use a compressed sparse row (CSR) based graph storage that is more amenable for selectively loading only a few active vertices in each iteration. But CSR based systems suffers from random update propagation to many target vertices. To solve this challenge, we propose to use a multi-log update mechanism that logs updates separately, rather than directly update the active edges in a graph. Our proposed multi-log system maintains a separate log per each vertex interval. This separation enables us to efficiently process each vertex interval by just loading the corresponding log. Further, while accessing SSD pages with fewer active vertex data, we reduce the read amplification due to the page granular accesses in SSD by logging the active vertex data in the current iteration and efficiently reading the log in the next iteration. Over the current state of the art out-of-core graph processing framework, our PartitionedVC improves performance by up to $17.84\times$, $1.19\times$, $1.65\times$, $1.38\times$, $3.15\times$, and $6.00\times$ for the widely used bfs, pagerank, community detection, graph coloring, maximal independent set, and random-walk applications, respectively.
翻译:图形分析是药物发现、页面排名和建议系统等广泛应用的核心。 当图形大小超过内存大小时, 需要超出核心图形处理。 对于广泛使用的外部内存图处理系统, 访问存储成为瓶颈。 我们观察到, 几乎所有图形算法都有动态不同的主动顶点, 每次迭代都必须处理。 然而, 现有的图形处理框架, 如 GraphChi, 将整张图表加在每次迭代中, 即使图表中有一小部分正在激活。 这一限制是由于这些系统所使用的数据存储结构 $的缘故 。 在此工作中, 我们提议使用一个压缩的稀薄( CSR) 基面图存储系统, 以便有选择地在每次迭代中只装上几个活跃的顶点。 但是基于 CSR 的系统会因随机更新向许多目标顶点的传播而受到影响。 为了解决这个问题, 我们提议使用一个多方向更新机制, 以单独更新, 而不是直接更新动态边端的 。 我们提议的多面处理系统在每次递增的平面记录中,, 以不断更新的平时, 。