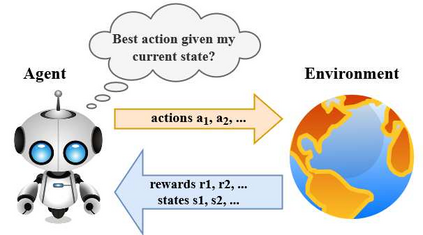
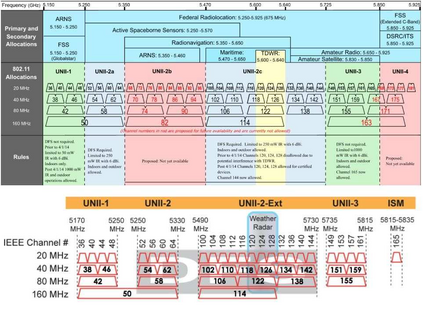
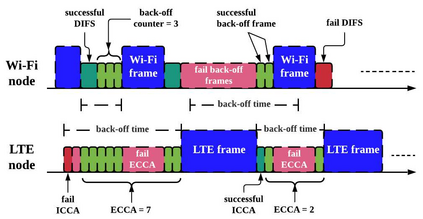
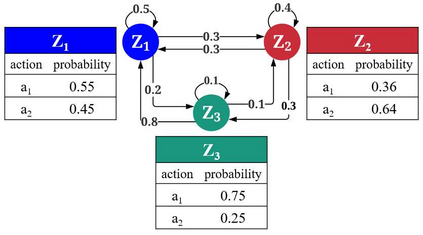
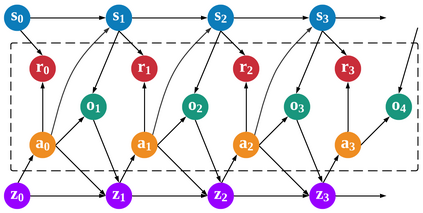
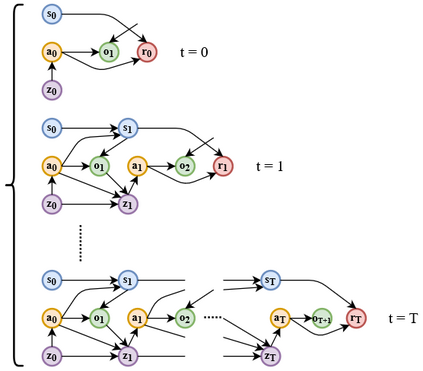
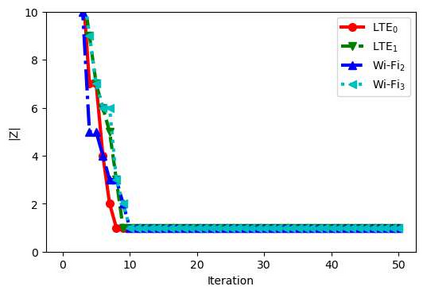
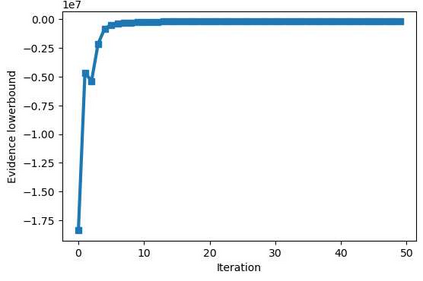
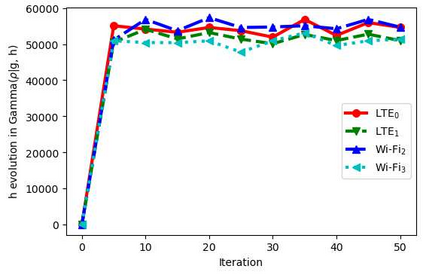
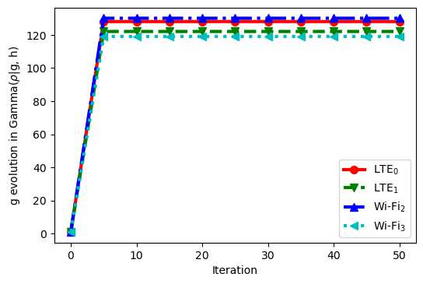
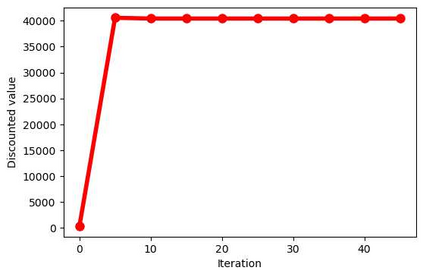
With the formation of next generation wireless communication, a growing number of new applications like internet of things, autonomous car, and drone is crowding the unlicensed spectrum. Licensed network such as the long-term evolution (LTE) also comes to the unlicensed spectrum for better providing high-capacity contents with low cost. However, LTE was not designed for sharing spectrum with others. A cooperation center for these networks is costly because they possess heterogeneous properties and everyone can enter and leave the spectrum unrestrictedly, so the design will be challenging. Since it is infeasible to incorporate potentially infinite scenarios with one unified design, an alternative solution is to let each network learn its own coexistence policy. Previous solutions only work on fixed scenarios. In this work a reinforcement learning algorithm is presented to cope with the coexistence between Wi-Fi and LTE agents in 5 GHz unlicensed spectrum. The coexistence problem was modeled as a decentralized partially observable Markov decision process (Dec-POMDP) and Bayesian approach was adopted for policy learning with nonparametric prior to accommodate the uncertainty of policy for different agents. A fairness measure was introduced in the reward function to encourage fair sharing between agents. The reinforcement learning was turned into an optimization problem by transforming the value function as likelihood and variational inference for posterior approximation. Simulation results demonstrate that this algorithm can reach high value with compact policy representations, and stay computationally efficient when applying to agent set.
翻译:随着下一代无线通信的形成,越来越多的新应用程序,如事物的互联网、自主汽车和无人驾驶飞机等,正在挤压无许可证的频谱。长期演进(LTE)等有许可证的网络也来到无许可证的频谱,以便以低成本更好地提供高容量内容。然而,LTE并不是设计用于与他人共享频谱。这些网络的合作中心成本高昂,因为它们拥有不同属性,每个人都可以不受限制地进入和离开频谱,因此设计将是具有挑战性的。由于用一个统一的设计来纳入潜在的无限情景是行不通的,因此,一个替代解决方案是让每个网络学习自己的共存政策。以往的解决方案仅针对固定情景开展工作。在这项工作中,提供强化学习算法是为了应对Wi-Fi和LTE代理在5 GHz无许可证频谱中的共存。这些网络的共存问题以分散化部分观测的Markov决策过程(Dec-POMDP)和Bayesian方法为模范式模式,在适应不同代理人政策不确定性之前就采用非对称的方法学习。在奖励性策略上引入公平性措施,在固定情况下,将奖励性计量性措施措施措施措施只用于鼓励公平分享工具。在Simimimalimalimalal resulational resultional resultiontiontiontiontiontiontiontiontiontionaldal 学习上,以学习该方法,从而学习如何学习如何学习如何学习如何学习标准学习如何学习如何学习如何学习。