
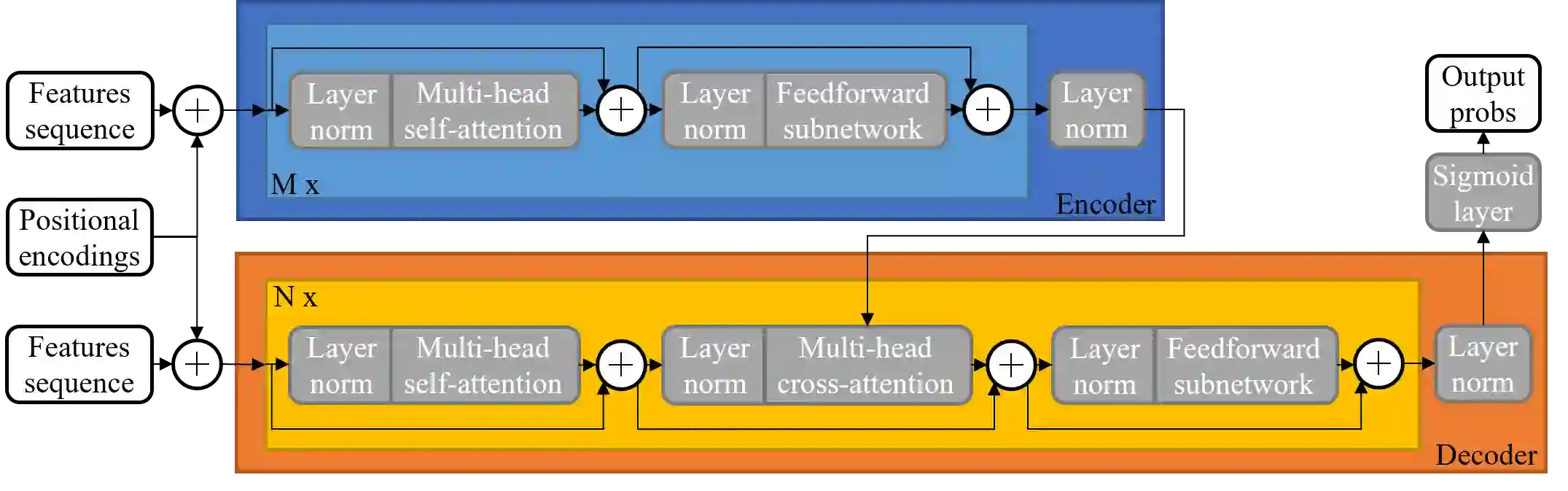
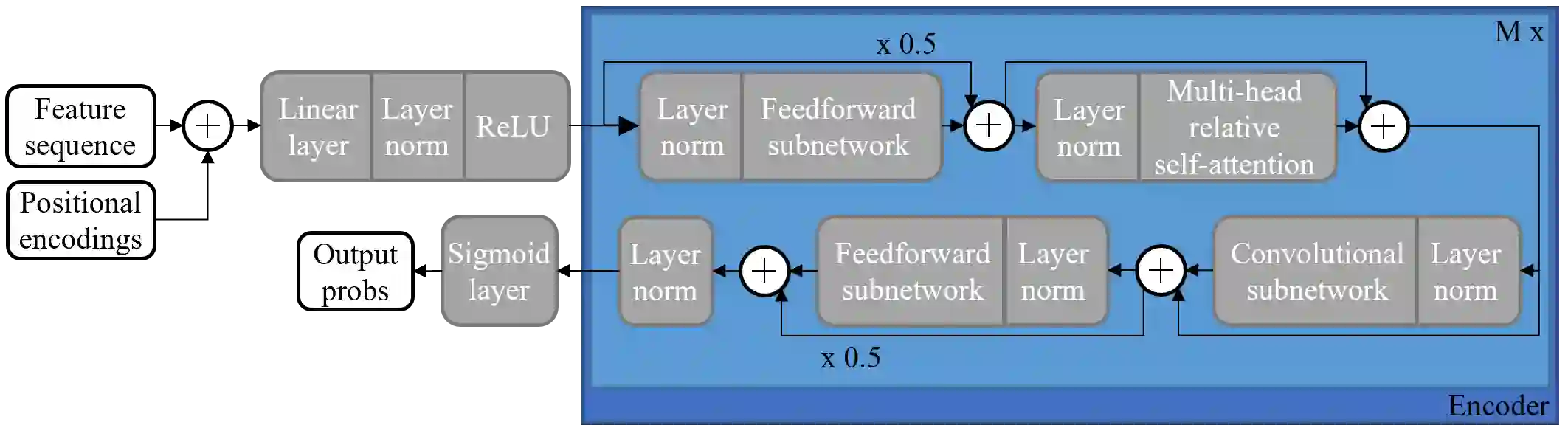
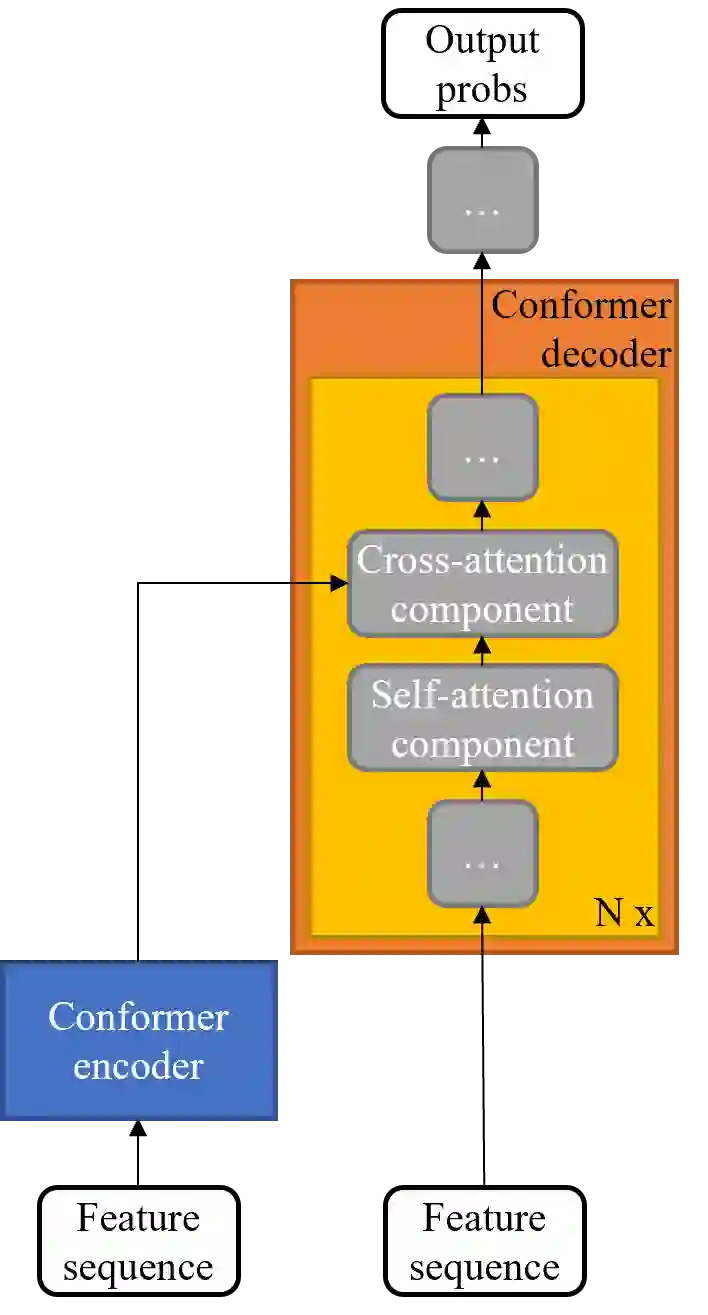
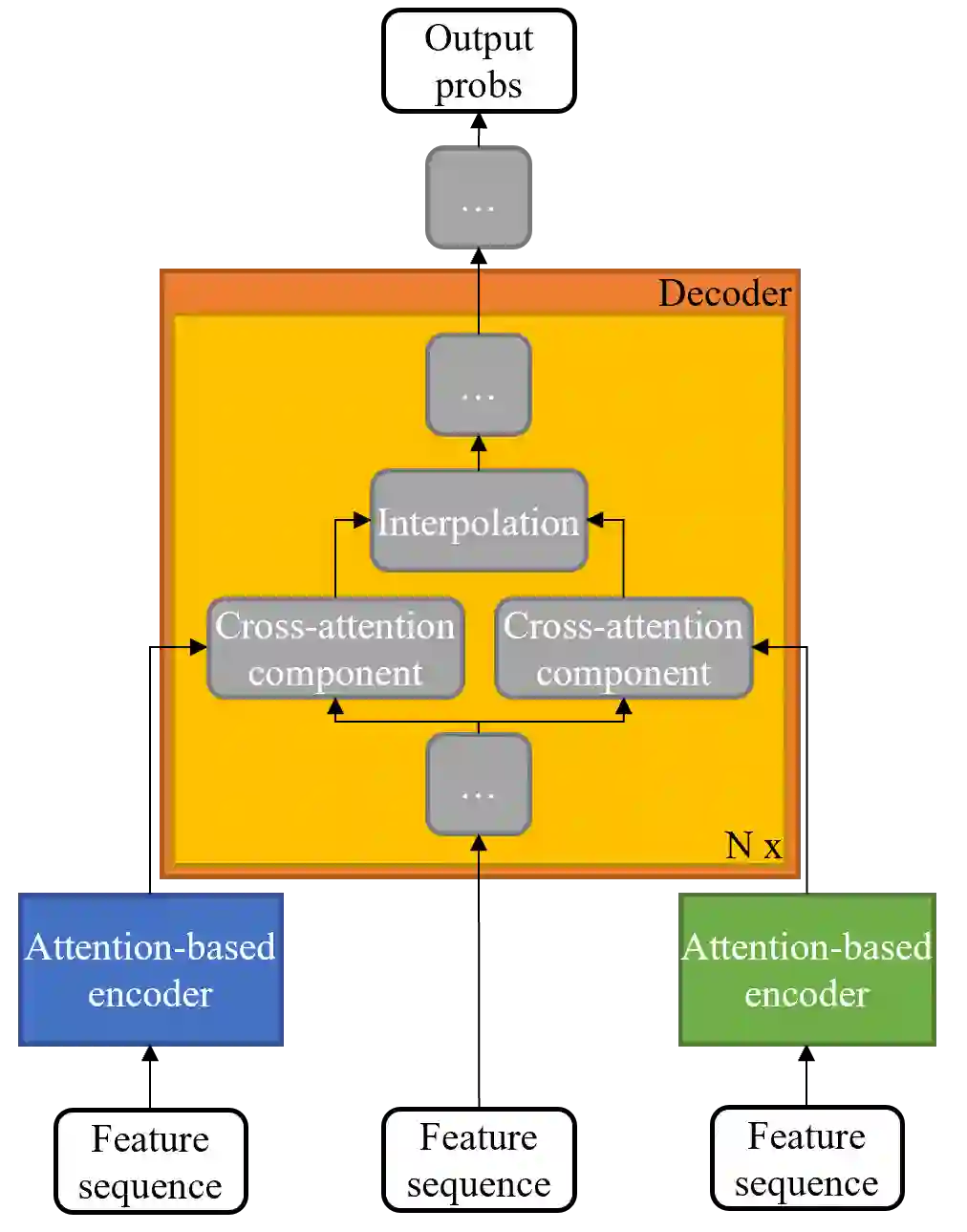
Large-scale sound recognition data sets typically consist of acoustic recordings obtained from multimedia libraries. As a consequence, modalities other than audio can often be exploited to improve the outputs of models designed for associated tasks. Frequently, however, not all contents are available for all samples of such a collection: For example, the original material may have been removed from the source platform at some point, and therefore, non-auditory features can no longer be acquired. We demonstrate that a multi-encoder framework can be employed to deal with this issue by applying this method to attention-based deep learning systems, which are currently part of the state of the art in the domain of sound recognition. More specifically, we show that the proposed model extension can successfully be utilized to incorporate partially available visual information into the operational procedures of such networks, which normally only use auditory features during training and inference. Experimentally, we verify that the considered approach leads to improved predictions in a number of evaluation scenarios pertaining to audio tagging and sound event detection. Additionally, we scrutinize some properties and limitations of the presented technique.
翻译:大型声学识别数据集通常包括从多媒体图书馆获得的声学记录,因此,往往可以利用音频以外的其他方法来改进为相关任务设计的模型的输出结果。但通常并非所有样本都有这种收集的样本:例如,原始材料可能在某个时候从源平台上移除,因此,无法再获得非审校特征。我们证明,通过将这种方法应用于目前声学领域最新水平的以关注为基础的深层学习系统,可以使用多级编码框架来处理这一问题。更具体地说,我们表明,可以成功地利用拟议的模型扩展将部分可获得的视觉信息纳入这种网络的操作程序,因为这些网络通常只在培训和推断过程中使用审校功能。我们实验性地核实,所考虑的方法能够改进与音频标记和音频事件探测有关的若干评价情景中的预测。此外,我们仔细检查了所介绍的技术的一些属性和局限性。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


