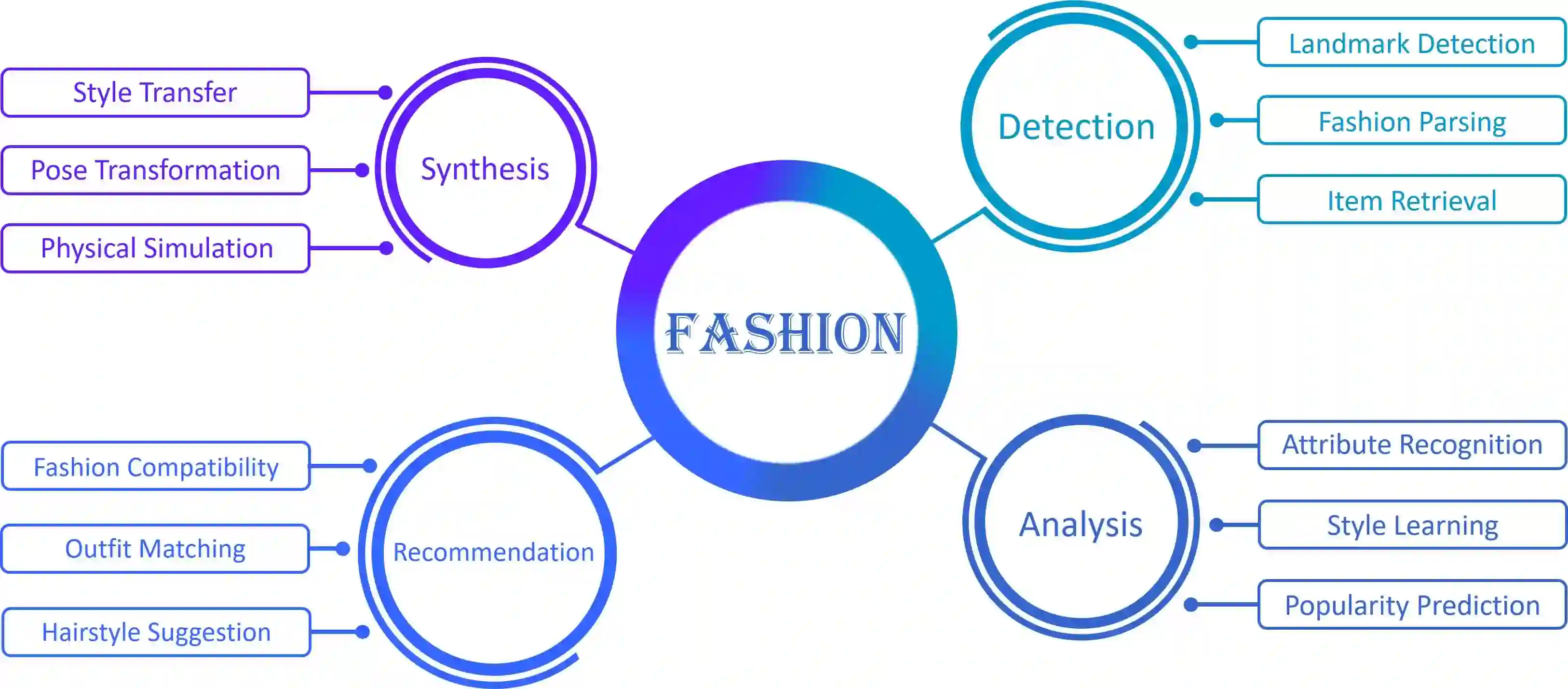
Fashion is the way we present ourselves to the world and has become one of the world's largest industries. Fashion, mainly conveyed by vision, has thus attracted much attention from computer vision researchers in recent years. Given the rapid development, this paper provides a comprehensive survey of more than 200 major fashion-related works covering four main aspects for enabling intelligent fashion: (1) Fashion detection includes landmark detection, fashion parsing, and item retrieval, (2) Fashion analysis contains attribute recognition, style learning, and popularity prediction, (3) Fashion synthesis involves style transfer, pose transformation, and physical simulation, and (4) Fashion recommendation comprises fashion compatibility, outfit matching, and hairstyle suggestion. For each task, the benchmark datasets and the evaluation protocols are summarized. Furthermore, we highlight promising directions for future research.
翻译:时装是我们向世界展示自己的方式,已经成为世界最大的产业之一。近年来,时装主要是通过视觉传递的,因此吸引了计算机视觉研究人员的极大关注。鉴于这种迅速发展,本文件对200多件主要时装相关作品进行了全面调查,涉及智能型四个主要方面,包括: (1) 时装探测包括里程碑式探测、时装区分和物品检索;(2) 时装分析包括属性识别、风格学习和流行预测;(3) 时装合成包括时装转换、面貌转换和物理模拟;(4) 时装建议包括时装兼容性、服装匹配和发型建议;对每一项任务,都摘要介绍基准数据集和评价程序;此外,我们强调未来研究的有希望的方向。