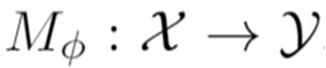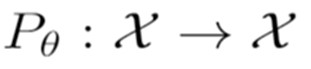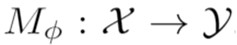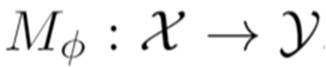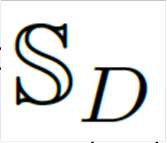The growing interest for adversarial examples, i.e. maliciously modified examples which fool a classifier, has resulted in many defenses intended to detect them, render them inoffensive or make the model more robust against them. In this paper, we pave the way towards a new approach to improve the robustness of a model against black-box transfer attacks. A removable additional neural network is included in the target model, and is designed to induce the \textit{luring effect}, which tricks the adversary into choosing false directions to fool the target model. Training the additional model is achieved thanks to a loss function acting on the logits sequence order. Our deception-based method only needs to have access to the predictions of the target model and does not require a labeled data set. We explain the luring effect thanks to the notion of robust and non-robust useful features and perform experiments on MNIST, SVHN and CIFAR10 to characterize and evaluate this phenomenon. Additionally, we discuss two simple prediction schemes, and verify experimentally that our approach can be used as a defense to efficiently thwart an adversary using state-of-the-art attacks and allowed to perform large perturbations.
翻译:对对抗性例子的兴趣日益浓厚,即恶意修改的例子愚弄了分类者,从而导致许多防守,目的是检测它们,使其不具有攻击性,或使模型更能对付它们。在本文中,我们铺平了道路,以采取新的办法,改进防止黑箱转移攻击的模型的稳健性。目标模型中包括了可复制的额外神经网络,目的是诱使对手选择假方向来欺骗目标模型。培训额外模型是因为在对数序列顺序上运行的损失功能而实现的。我们以欺骗为基础的方法只需要能够了解目标模型的预测,而不需要贴标签的数据集。我们解释了由于强健和不破坏的功能概念而具有的诱惑效应,并在MNIST、SVHN和CIFAR10上进行实验,以描述和评价这一现象。此外,我们讨论了两个简单的预测方案,并核实实验性地将我们的方法用作一种防御手段,以便利用州-图式攻击和允许的大型攻击来有效挫败敌人。