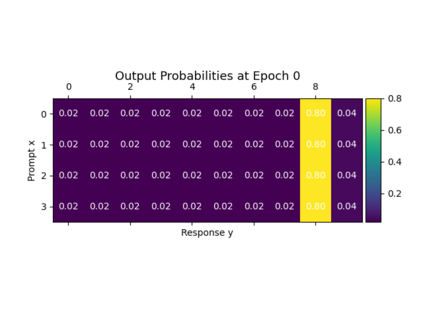
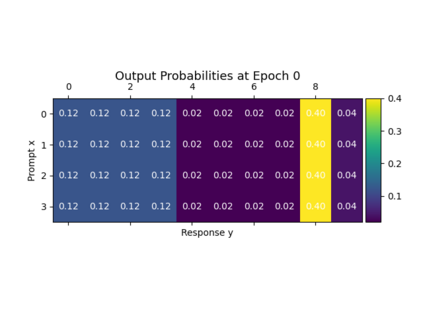
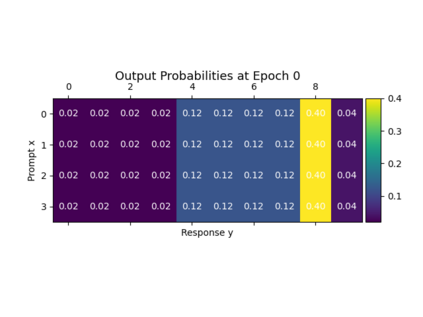
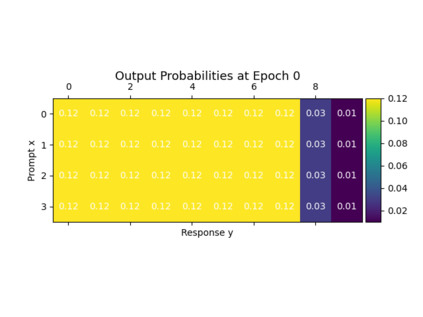
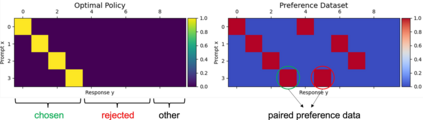
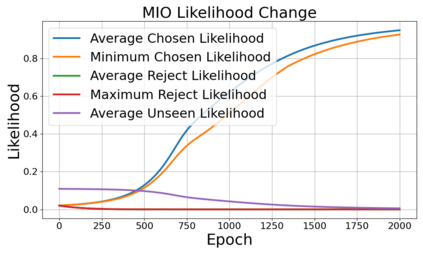
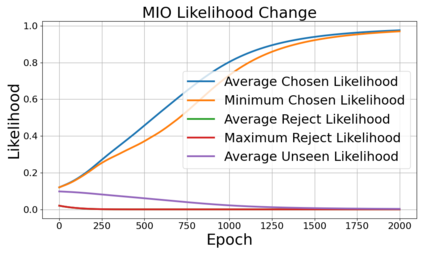
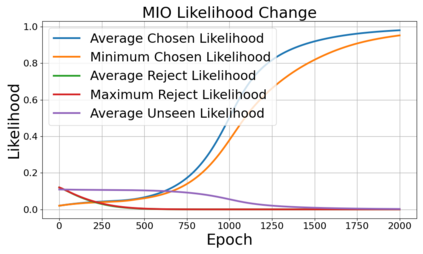
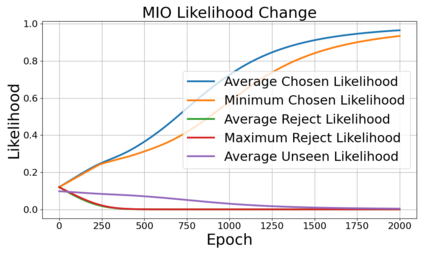
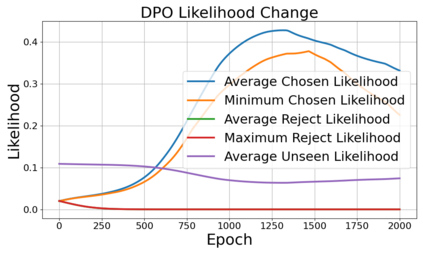
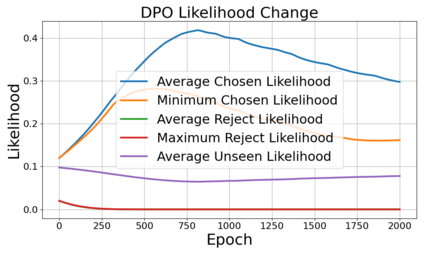
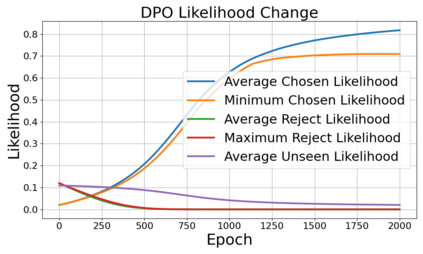
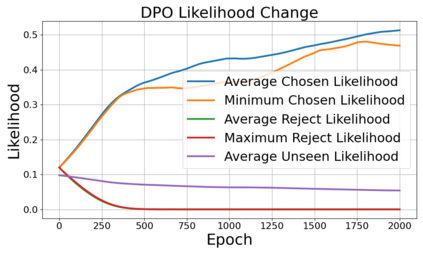
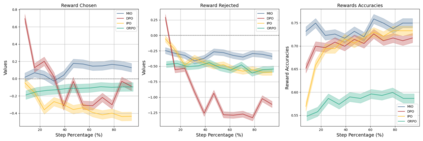
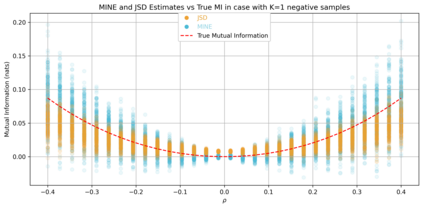
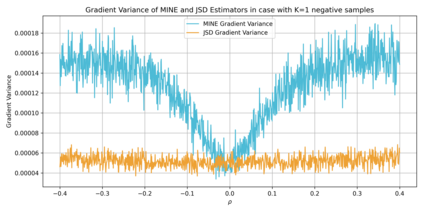
Alignment of large language models (LLMs) with human values has recently garnered significant attention, with prominent examples including the canonical yet costly Reinforcement Learning from Human Feedback (RLHF) and the simple Direct Preference Optimization (DPO). In this work, we demonstrate that both RLHF and DPO can be interpreted from the perspective of mutual information (MI) maximization, uncovering a profound connection to contrastive learning. Within this framework, both RLHF and DPO can be interpreted as methods that performing contrastive learning based on the positive and negative samples derived from base model, leveraging the Donsker-Varadhan (DV) lower bound on MI (equivalently, the MINE estimator). Such paradigm further illuminates why RLHF may not intrinsically incentivize reasoning capacities in LLMs beyond what is already present in the base model. Building on the perspective, we replace the DV/MINE bound with the Jensen-Shannon (JS) MI estimator and propose the Mutual Information Optimization (MIO). Comprehensive theoretical analysis and extensive empirical evaluations demonstrate that MIO mitigates the late-stage decline in chosen-likelihood observed in DPO, achieving competitive or superior performance across various challenging reasoning and mathematical benchmarks.
翻译:暂无翻译