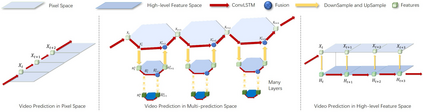
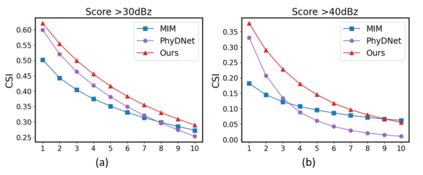
Despite video forecasting has been a widely explored topic in recent years, the mainstream of the existing work still limits their models with a single prediction space but completely neglects the way to leverage their model with multi-prediction spaces. This work fills this gap. For the first time, we deeply study numerous strategies to perform video forecasting in multi-prediction spaces and fuse their results together to boost performance. The prediction in the pixel space usually lacks the ability to preserve the semantic and structure content of the video however the prediction in the high-level feature space is prone to generate errors in the reduction and recovering process. Therefore, we build a recurrent connection between different feature spaces and incorporate their generations in the upsampling process. Rather surprisingly, this simple idea yields a much more significant performance boost than PhyDNet (performance improved by 32.1% MAE on MNIST-2 dataset, and 21.4% MAE on KTH dataset). Both qualitative and quantitative evaluations on four datasets demonstrate the generalization ability and effectiveness of our approach. We show that our model significantly reduces the troublesome distortions and blurry artifacts and brings remarkable improvements to the accuracy in long term video prediction. The code will be released soon.
翻译:尽管视频预报是近年来广泛探讨的一个专题,但现有工作的主流仍然以单一预测空间限制其模型,但完全忽略了利用多频频空间利用模型的方法。 这项工作填补了这一空白。 我们第一次深入研究了在多频域空间进行视频预报的众多战略,并结合了结果以提升性能。 象素空间的预测通常缺乏保存视频的语义和结构内容的能力,然而在高频空间的预测很容易在减少和复原过程中产生错误。 因此,我们在不同地物空间之间建立了经常性的连接,并将其代代代相传纳入更新的取样过程。 令人惊讶的是,这一简单的想法产生比PhyDNet(MITS-2数据集的性能提高了32.1%MAE, KTH数据集的性能提高了21.4% MAE)更显著的性能提升。 对四个数据集的定性和定量评价都显示了我们方法的普及能力和有效性。 我们显示,我们的模型将大大减少麻烦的扭曲和模糊的文物,并将长期的精确性图像预测带来显著的改进。