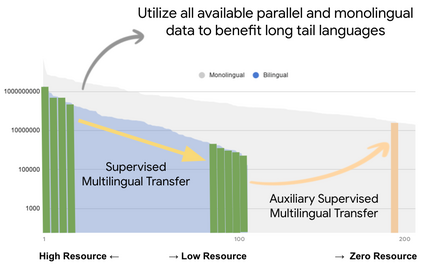
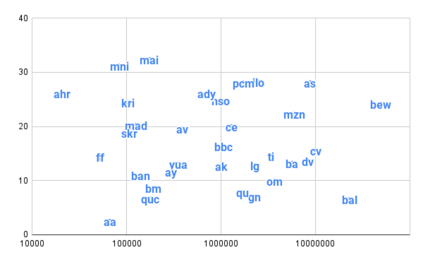
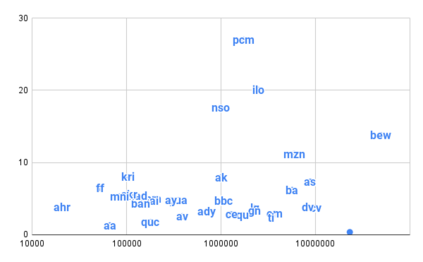
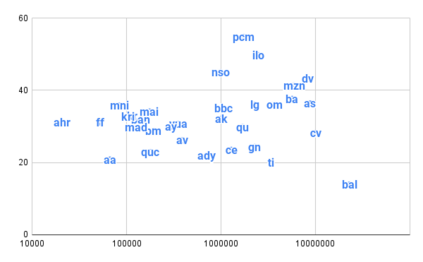
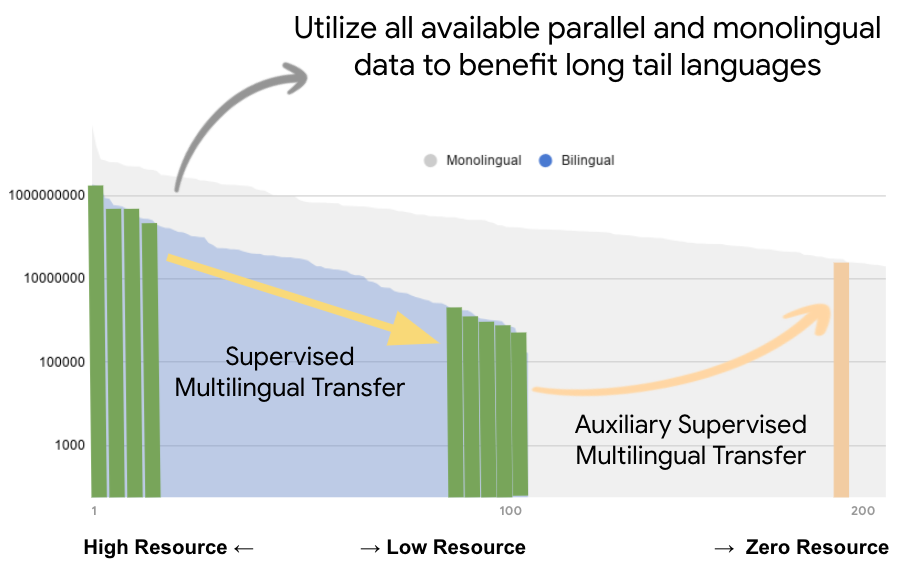
Achieving universal translation between all human language pairs is the holy-grail of machine translation (MT) research. While recent progress in massively multilingual MT is one step closer to reaching this goal, it is becoming evident that extending a multilingual MT system simply by training on more parallel data is unscalable, since the availability of labeled data for low-resource and non-English-centric language pairs is forbiddingly limited. To this end, we present a pragmatic approach towards building a multilingual MT model that covers hundreds of languages, using a mixture of supervised and self-supervised objectives, depending on the data availability for different language pairs. We demonstrate that the synergy between these two training paradigms enables the model to produce high-quality translations in the zero-resource setting, even surpassing supervised translation quality for low- and mid-resource languages. We conduct a wide array of experiments to understand the effect of the degree of multilingual supervision, domain mismatches and amounts of parallel and monolingual data on the quality of our self-supervised multilingual models. To demonstrate the scalability of the approach, we train models with over 200 languages and demonstrate high performance on zero-resource translation on several previously under-studied languages. We hope our findings will serve as a stepping stone towards enabling translation for the next thousand languages.
翻译:实现所有人类语文对口之间的普遍翻译是机器翻译(MT)研究的神圣基石。虽然在大规模多语种MT方面最近取得的进展距离实现这一目标更近一步,但越来越明显的是,仅仅通过对更平行数据的培训而扩大多语种MT系统是无法扩展的,因为为低资源和非以英语为中心的语言对口提供有标签的数据是不容限制的。为此,我们提出了一个务实的办法,以建立涵盖数百种语言的多语种的多语种MT模式,利用受监督和自我监督的混合目标,视不同语言对口的数据提供情况而定。我们证明,这两个培训模式之间的协同作用使该模式能够在零资源环境下产生高质量的翻译,甚至超过中、低资源语言的监督翻译质量。我们进行了一系列广泛的实验,以了解多语种监督的程度、域不匹配以及平行和单语种数据的数量对我们自我强化的多语种模式的质量的影响。为了展示该方法的可扩展性,我们训练了200多种语言的模型,并展示了我们今后在零资源环境下进行高水平翻译的成绩。