
题目: InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions
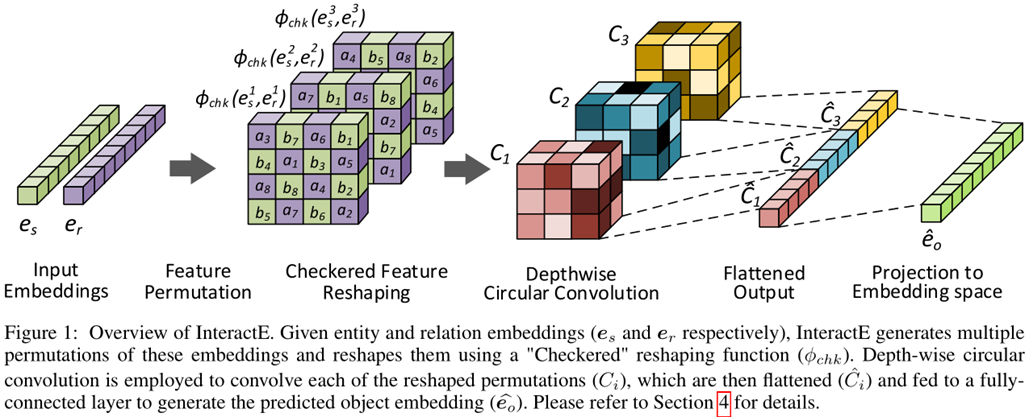
摘要: 现有的大多数知识图谱是不完整的,这个问题是可以通过基于已知事实推断缺失的链接来进行缓解的。目前一种流行的方法是通过生成实体和关系的低维嵌入,并使用它们进行推断。ConvE是最近提出的一种方法,它将卷积滤波器应用于实体和关系嵌入的 2D重构,以捕获它们之间的交互信息。然而,ConvE捕获的交互作用的量是有限的。在这篇文章中,我们分析了增加这些相互作用的数量如何影响链路预测性能,并利用我们的观察提出了InteractE。InteractE基于三个关键思想:特征排列、新颖的特征重塑和循环卷积。通过大量的实验,我们发现InteractE在FB15k-237上的性能优于最先进的卷积链路预测基线方法。此外,在FB15k-237、WN18RR和YAGO3-10数据集上,InteractE的MRR评分分别比ConvE高9%、7.5%和23%。结果验证了我们的假设,即增加特征交互有助于提高链接预测性能。
成为VIP会员查看完整内容
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
80+阅读 · 2019年11月5日
InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions
Arxiv
13+阅读 · 2019年11月1日
Arxiv
9+阅读 · 2019年10月12日
Arxiv
14+阅读 · 2018年5月19日
Arxiv
11+阅读 · 2018年5月9日

相关VIP内容
专知会员服务
101+阅读 · 2020年6月28日
专知会员服务
80+阅读 · 2019年11月5日
相关资讯
相关论文
InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions
Arxiv
13+阅读 · 2019年11月1日
Arxiv
9+阅读 · 2019年10月12日
Arxiv
14+阅读 · 2018年5月19日
Arxiv
11+阅读 · 2018年5月9日