

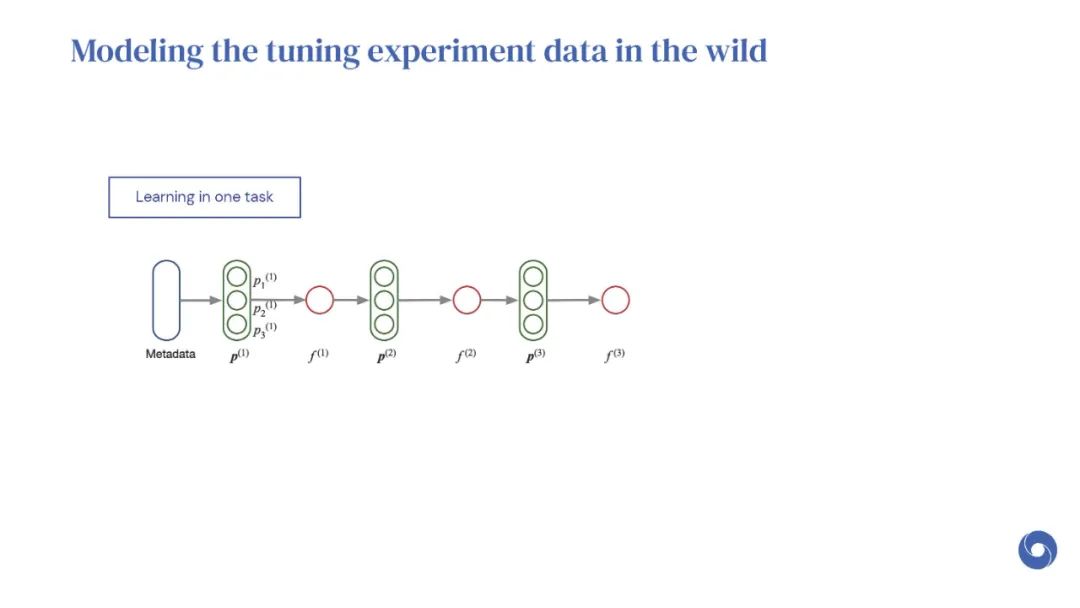
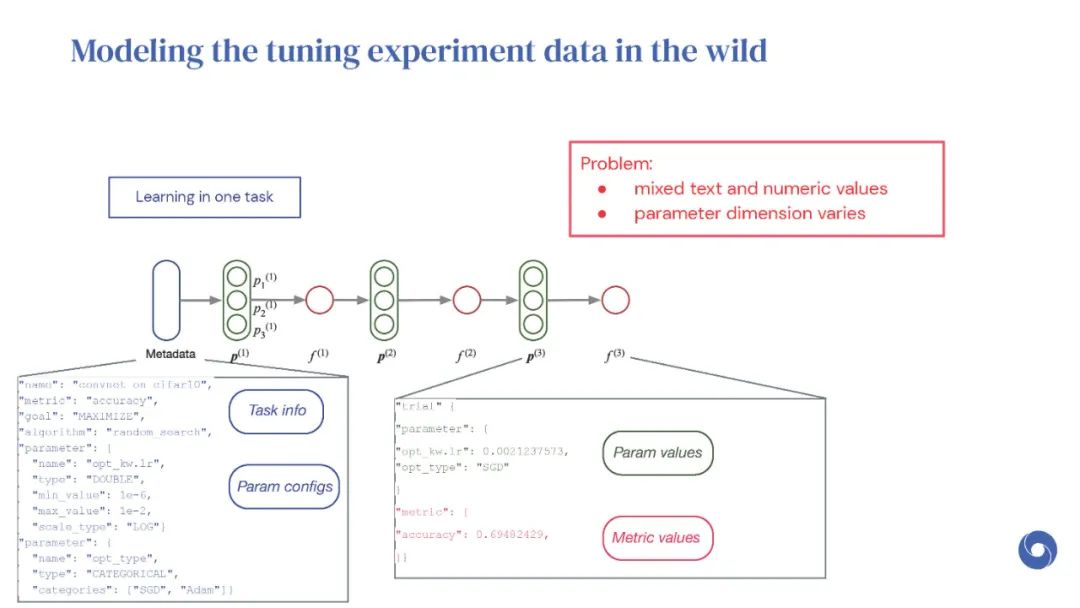
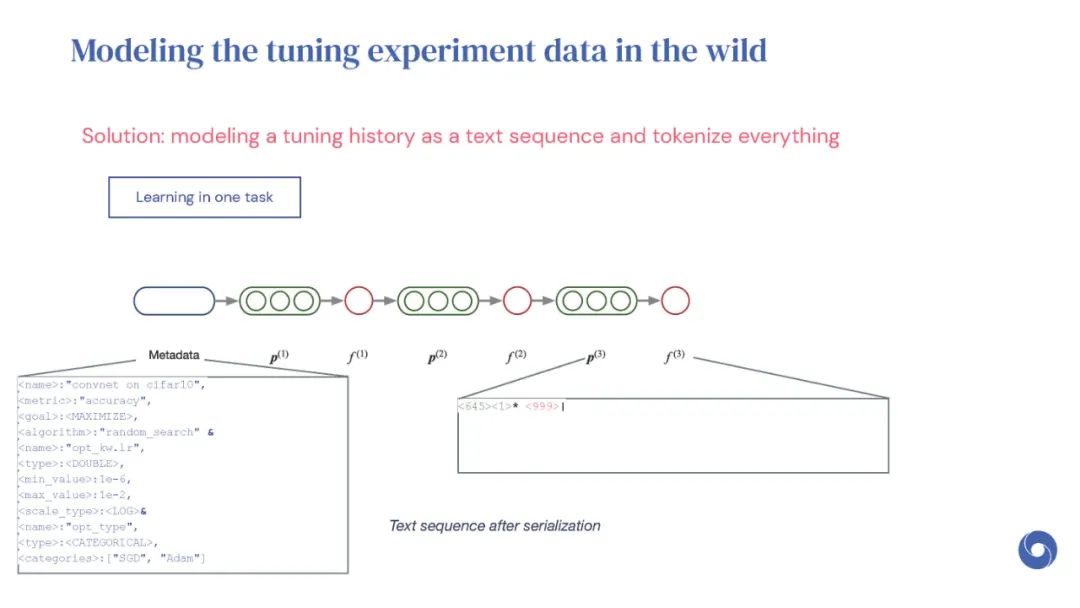
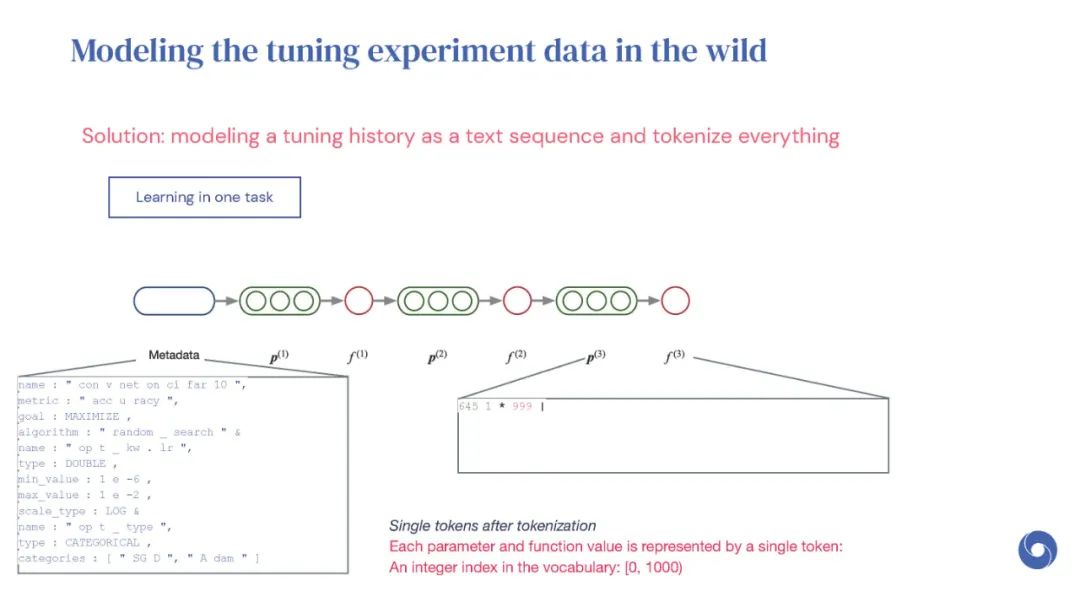
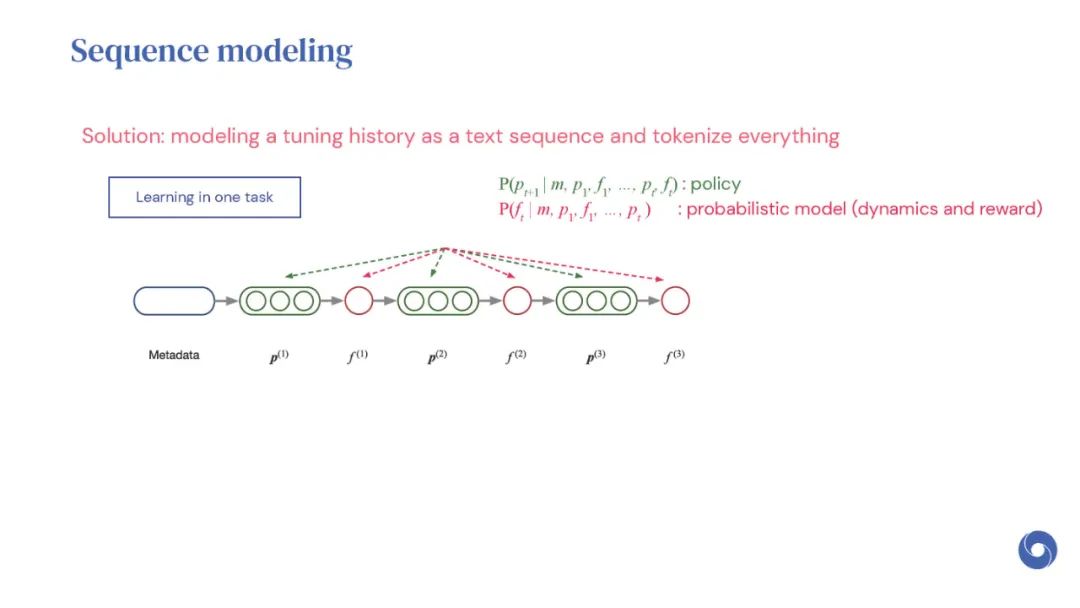
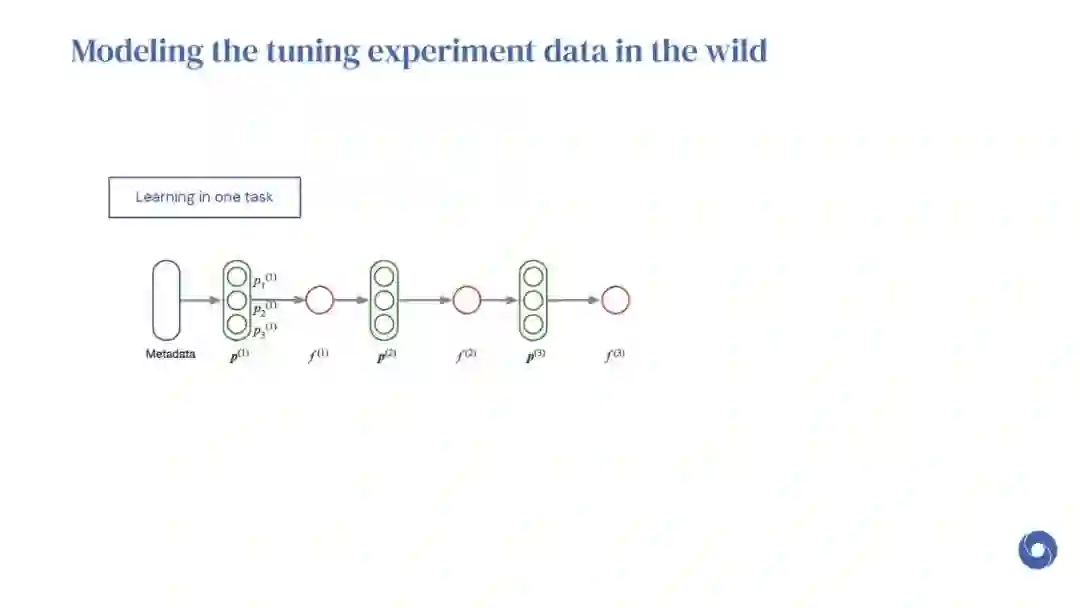
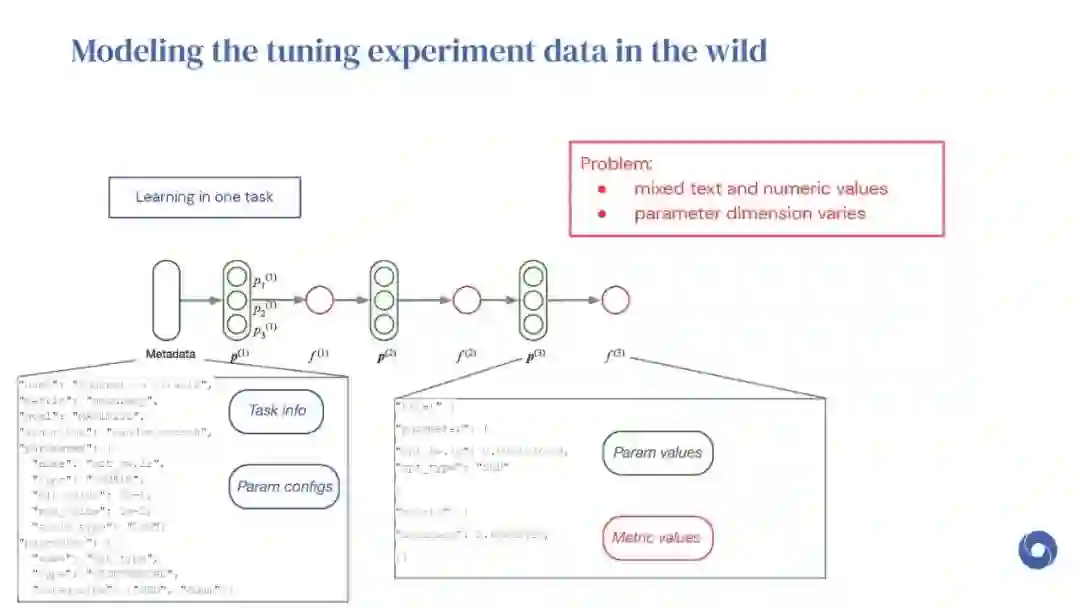
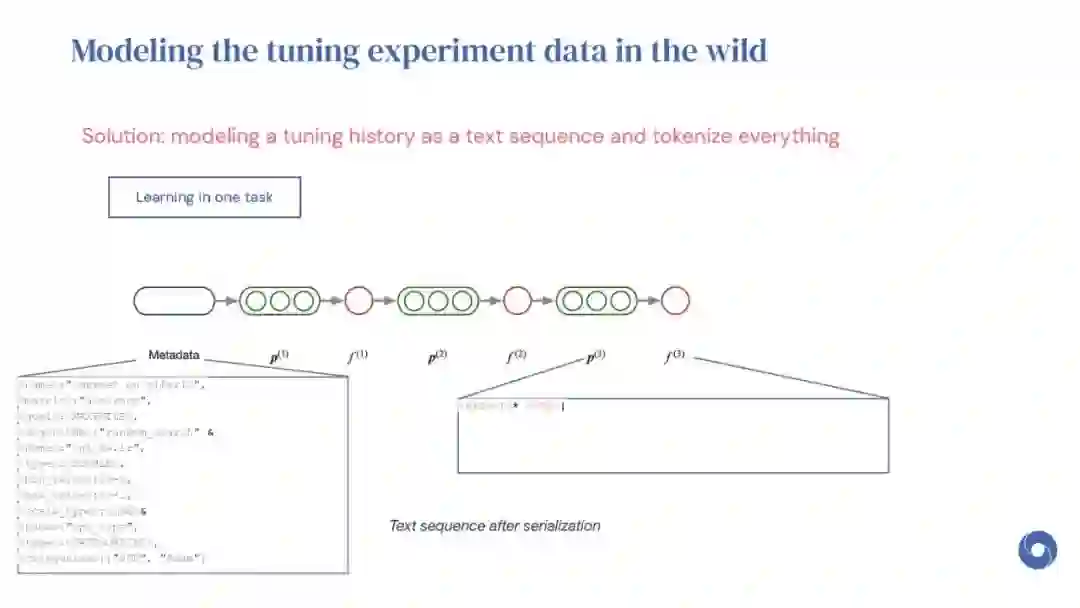
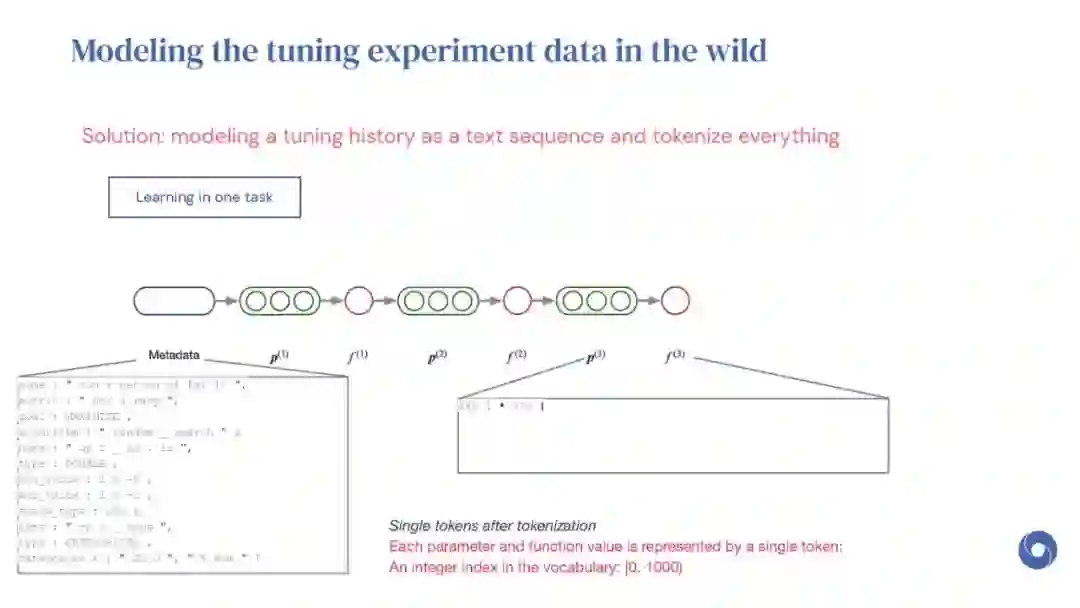
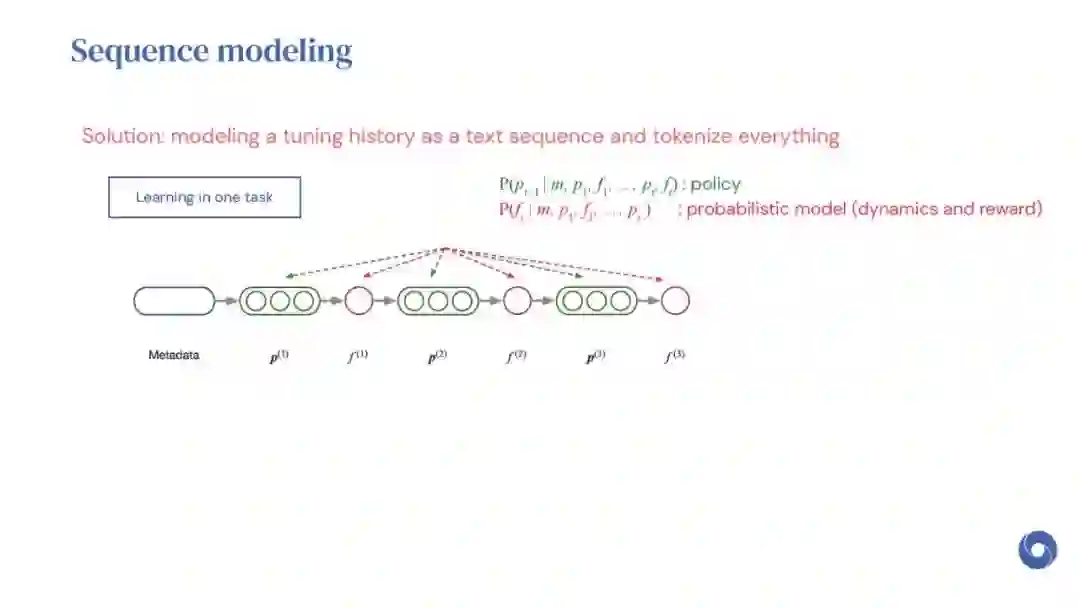
基于先验实验的元学习超参数优化(HPO)算法是提高分布相似目标函数优化效率的有效方法。然而,现有的方法仅限于从共享一组超参数的实验中学习。本文提出OptFormer,第一个基于文本的Transformer HPO框架,在对来自外界的大量调优数据进行训练时,提供了一个通用的端到端接口,用于联合学习策略和功能预测。实验结果表明,OptFormer可以模拟至少7种不同的HPO算法,这些算法可以通过其功能不确定性估计进一步改进。与高斯过程相比,OptFormer还学习了超参数响应函数的鲁棒先验分布,从而可以提供更准确和更好的校准预测。本文工作为未来将基于transformer的模型训练为通用HPO优化器铺平了道路。
Yutian Chen博士是DeepMind的Staff研究科学家。他在加州大学欧文分校(University of California, Irvine)获得机器学习博士学位,后来在剑桥大学(University of Cambridge)担任研究助理(博士后),然后加入DeepMind。于田参与了AlphaGo和AlphaGo Zero项目,开发了击败世界冠军的围棋AI程序。AlphaGo项目被《新科学家》杂志评为2010年代的十大发现之一。Yutian在多个机器学习领域进行了研究,包括贝叶斯方法、离线强化学习、生成模型和应用于游戏AI、计算机视觉和文本到语音的元学习。Yutian还担任多个学术会议和期刊的评审员和区域主席。





成为VIP会员查看完整内容





相关内容

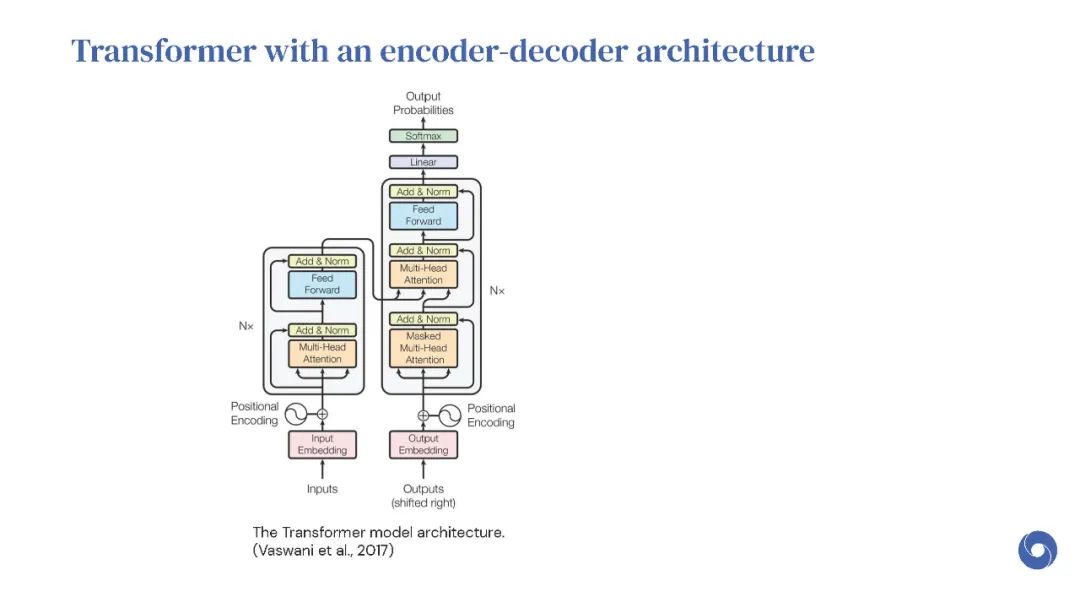
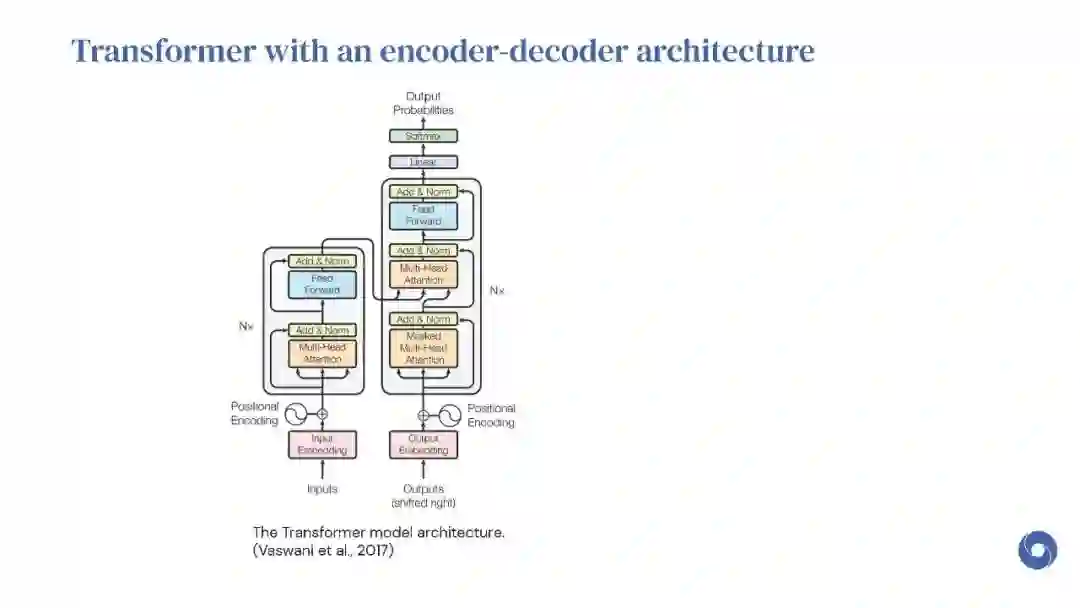
Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
0+阅读 · 2023年4月30日
相关VIP内容
相关资讯