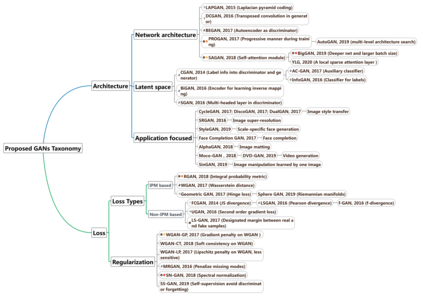
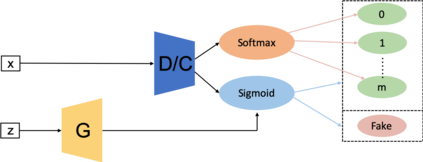
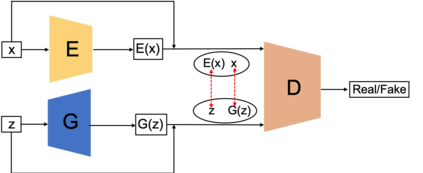
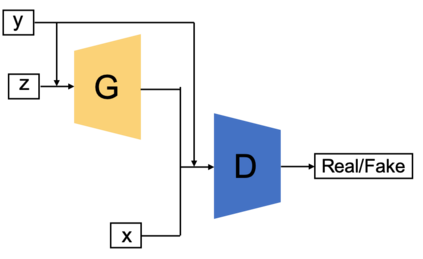
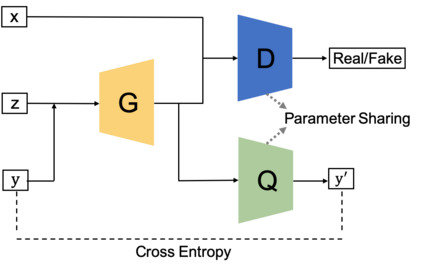
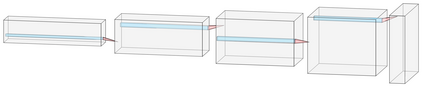
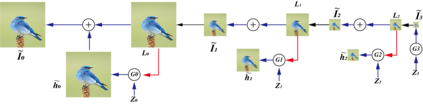
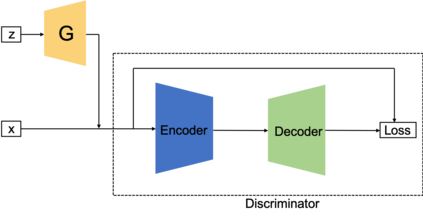
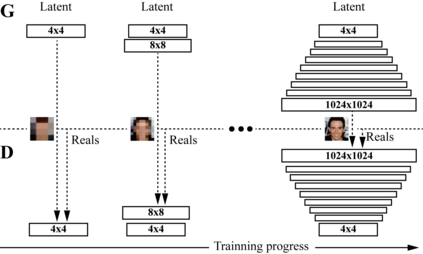
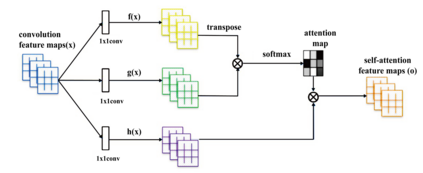
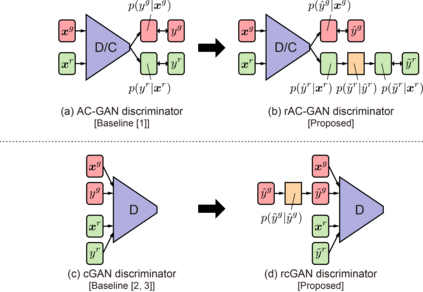
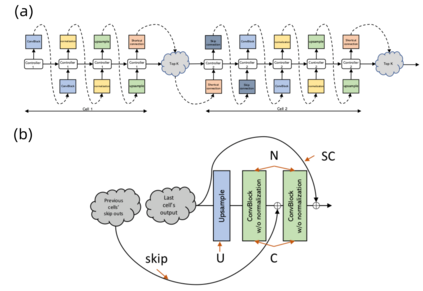
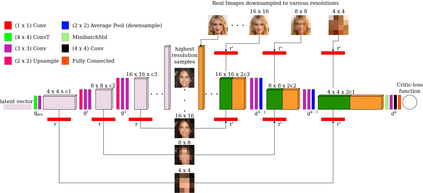
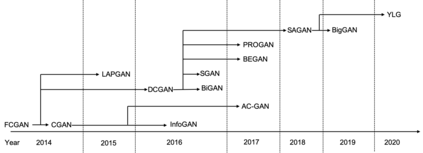
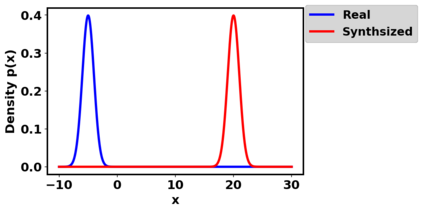
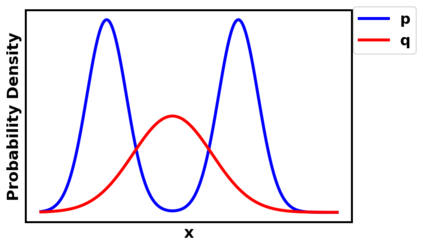
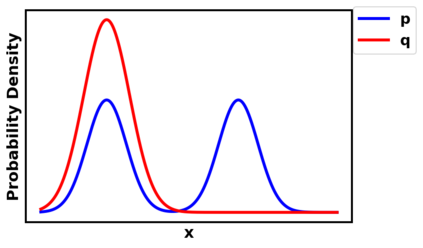
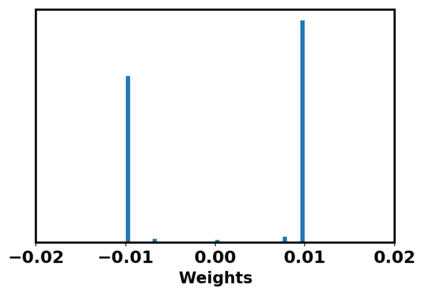
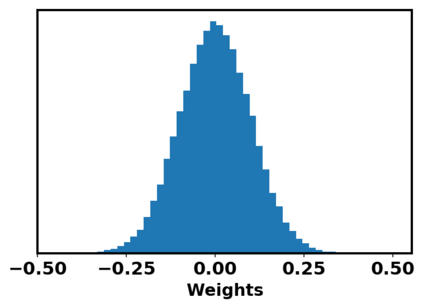
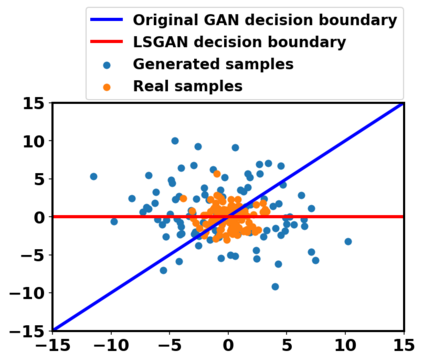
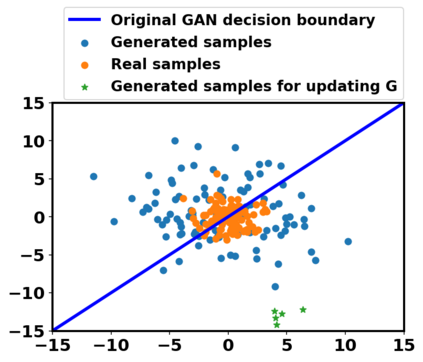
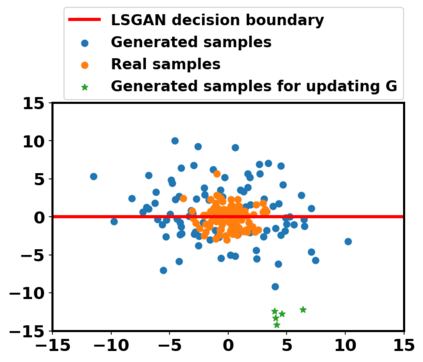
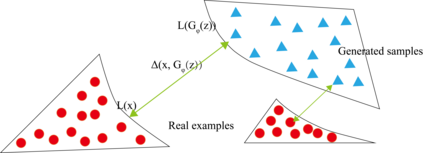
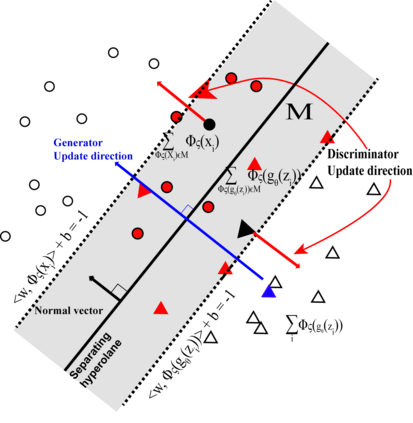
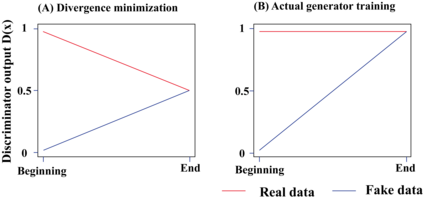
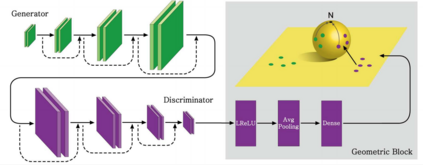
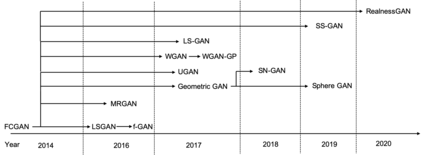
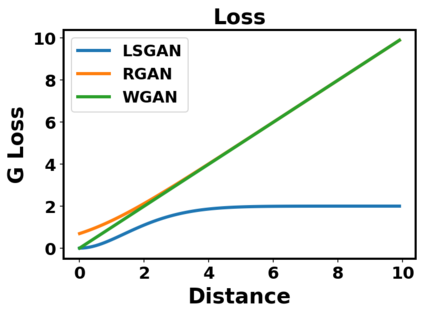
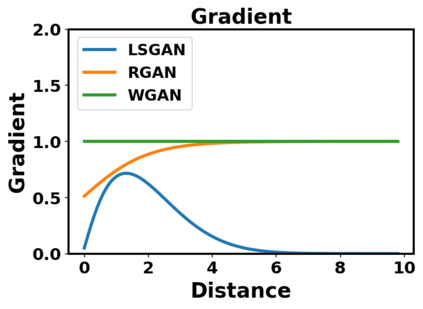
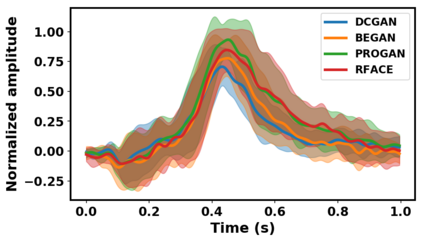
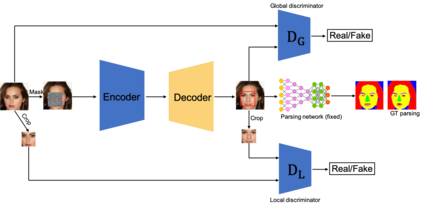
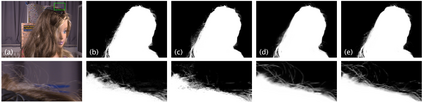
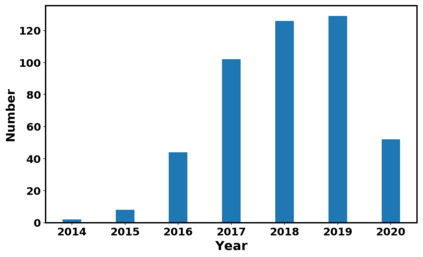
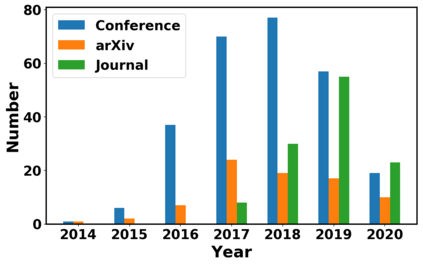
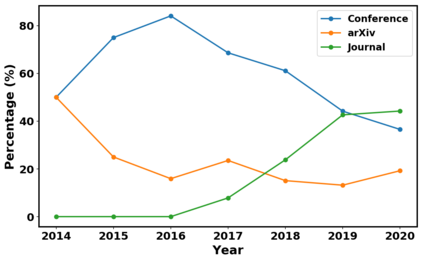
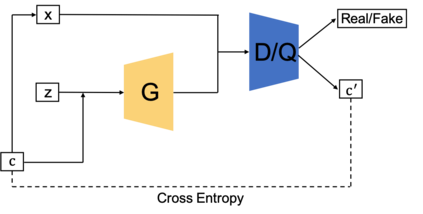Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably their most significant impact has been in the area of computer vision where great advances have been made in challenges such as plausible image generation, image-to-image translation, facial attribute manipulation and similar domains. Despite the significant successes achieved to date, applying GANs to real-world problems still poses significant challenges, three of which we focus on here. These are: (1) the generation of high quality images, (2) diversity of image generation, and (3) stable training. Focusing on the degree to which popular GAN technologies have made progress against these challenges, we provide a detailed review of the state of the art in GAN-related research in the published scientific literature. We further structure this review through a convenient taxonomy we have adopted based on variations in GAN architectures and loss functions. While several reviews for GANs have been presented to date, none have considered the status of this field based on their progress towards addressing practical challenges relevant to computer vision. Accordingly, we review and critically discuss the most popular architecture-variant, and loss-variant GANs, for tackling these challenges. Our objective is to provide an overview as well as a critical analysis of the status of GAN research in terms of relevant progress towards important computer vision application requirements. As we do this we also discuss the most compelling applications in computer vision in which GANs have demonstrated considerable success along with some suggestions for future research directions. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.
翻译:过去几年来,人们广泛研究了对抗性网络(GANs),认为其最显著的影响是在计算机视野领域,在计算机视野领域取得了巨大进展,在诸如貌似图像生成、图像到图像翻译、面部属性操控和类似领域等挑战方面取得了巨大进展。尽管迄今为止取得了巨大成功,但将GANs应用于现实世界问题仍构成重大挑战,其中三项我们在此集中研究。它们是:(1) 制作高质量图像,(2) 图像生成多样性和(3) 稳定培训。侧重于大众GAN技术在应对这些挑战方面取得的进展程度,我们详细回顾了GAN相关研究在已出版的科学文献中的最新进展。我们通过基于GAN结构的变异和损失功能的方便分类,进一步构建了这一审查。虽然迄今为止已经提出了对GAN的几次审查,但还没有根据在解决计算机视野相关实际挑战方面取得的进展来考虑该领域的现状。因此,我们审查并批判性地讨论了最受欢迎的建筑变量,以及GAN相关研究中的损失-AN趋势。我们对于GAN应用的这一重要工作前景分析也显示了我们如何应对GAN的关键性进展。