动态网络嵌入
·

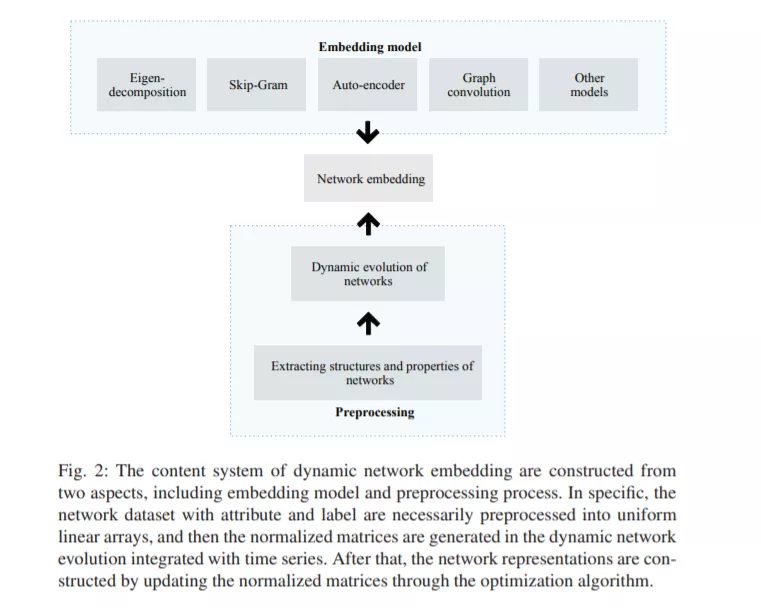
现实网络由多种相互作用、不断进化的实体组成,而现有的研究大多将其简单地描述为特定的静态网络,而没有考虑动态网络的演化趋势。近年来,动态网络的特性跟踪研究取得了重大进展,利用网络中实体和链接的变化来设计网络嵌入技术。与被广泛提出的静态网络嵌入方法相比,动态网络嵌入努力将节点编码为低维密集表示,有效地保持了网络结构和时间动态,有利于处理各种下游机器学习任务。本文对动态网络嵌入问题进行了系统的研究,重点介绍了动态网络嵌入的基本概念,首次对现有的动态网络嵌入技术进行了分类,包括基于矩阵分解的、基于跃格的、基于自动编码器的、基于神经网络的等嵌入方法。此外,我们仔细总结了常用的数据集和各种各样的后续任务,动态网络嵌入可以受益。在此基础上,提出了动态嵌入模型、大规模动态网络、异构动态网络、动态属性网络、面向任务的动态网络嵌入以及更多的嵌入空间等现有算法面临的挑战,并提出了未来可能的研究方向。
成为VIP会员查看完整内容
相关内容
相关主题
相关VIP内容
相关资讯
相关论文